







数据库约束:
primary key: 主键默认不能为空(物理上存储的顺序)
auto_increment: 表示自动增长
create table teachers(
id int primary key auto_increment,
name varchar(20) unique ,
gender varchar(20) default "保密" not null comment "男女" ,
age int not null default 0 ,
height double default 0 not null comment "厘米",
weight double default 0 not null comment "公斤"
) engine = InnoDB auto_increment=3 default charset = utf8;
注意:
null不视为重复值
约束类型
1)NOT NULL - 指示某列不能存储NULL 值。
2)UNIQUE - 保证某列的每行必须有唯一的值。
3)DEFAULT - 规定没有给列赋值时的默认值。
4)PRIMARY KEY - NOT NULL 和UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
5)FOREIGN KEY - 保证一个表中的数据匹配另一个表中的值的参照完整性。
6)CHECK - 保证列中的值符合指定的条件。对于MySQL数据库,对CHECK子句进行分析,但是忽略CHECK子句
注意:
- 对于整数类型的主键,常配搭自增长auto_increment来使用。插入数据对应字段不给值时,使用时最大值+1。
- foreign key外键用于关联其他表的主键或唯一键,语法:
foreign key (字段名) references 主表(列)
建数据表时添加外键:
foreign key(cate_id) references goods_cates(id)
添加外键约束:
alter table goods add foreign key (cate_id) references goods_cates(id);
插入查询结果
insert into test_user(name, email) select name, qq_mail from student;
1 聚合查询
GROUP BY 子句(可以独立出现)
HAVING 子句(必须跟在 GROUP BY 后边)
常见的聚合函数(独立于 GROUP BY 出现)有:
COUNT([DISTINCT] expr) 返回查询到的数据的数量
SUM([DISTINCT] expr) 返回查询到的数据的总和,不是数字没有意义
AVG([DISTINCT] expr) 返回查询到的数据的平均值,不是数字没有意义
MAX([DISTINCT] expr) 返回查询到的数据的最大值,不是数字没有意义
MIN([DISTINCT] expr) 返回查询到的数据的最小值,不是数字没有意义
平均总分:
SELECT AVG(chinese + math + english) FROM exam_result;
返回英语最高分:
SELECT MAX(english) FROM exam_result;
GROUP BY子句
SELECT 中使用GROUP BY 子句可以对指定列进行分组查询。需要满足:使用GROUP BY 进行分组查询时,SELECT 指定的字段必须是“分组依据字段”,其他字段若想出现在SELECT 中则必须包含在聚合函数中. 即在分组语句中,其select后只能是分组凭证字段和聚合函数。role即为分组凭证。
select role,max(salary),min(salary),avg(salary) from emp
group by role;
注意:
和 WHERE 对比:WHERE 对聚合前的数据进行过滤;HAVING 对聚合后的数据进行过滤。GROUP BY 子句进行分组以后,对分组结果进行条件过滤时,不能使用WHERE 语句,需要用HAVING语句。
select role,max(salary),min(salary),avg(salary) from emp
group by role having avg(salary)<1500;
2 联表查询
多张表之间进行查询,不加筛选条件,出现的结果就是多张表的笛卡儿积。
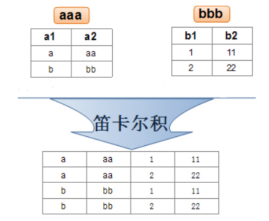
参考博客:笛卡儿积
2.1 连接查询
当查询结果的列来源于多张表时,需要将多张表连接成一个大的数据集,再选择合适的列返回
mysql支持三种类型的连接查询,分别为:
1)内连接查询: 查询的结果为两个表匹配到的数据
2)右连接查询: 查询的结果为两个表匹配到的数据,右表特有的数据,对于左表中不存在的数据使用null填充,以右表为基准
3)左连接查询: 查询的结果为两个表匹配到的数据,左表特有的数据,对于右表中不存在的数据使用null填充,以左表为基准。
内连接查询:
select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其他条件;
等价于:
select 字段 from 表1 别名1, 表2 别名2 where 连接条件 and 其他条件;
select classes.name, student.name from classes, student where classes.id = student.classes_id;
select clssses.name, student.name from classes join student on classes.id = student.classes_id;
select clssses.name, student.name from student join 。。。 on 。。。
join 。。。 on 。。。;
SELECT c.name, s.name, co.name, sc.score FROM classes c, student s, course co, score sc
WHERE c.id = s.classes_id AND s.id = sc.student_id AND co.id = sc.course_id;
外连接查询:
select 字段名 from 表名1 left join 表名2 on 连接条件;
select 字段from 表名1 right join 表名2 on 连接条件;
4)自连接查询: 自连接是指在同一张表连接自身进行查询,因为是同一张表联表,所以必须起不同的别名以作区分。
select s1.* from score s1, score s2 where s1.course_id = 1 and s2.course_id=3 and s1.score<s2.score;
3 子查询:
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询。
先通过一个 SELECT 查询,得到一组结果集。利用这个结果集做第二次查询。
1).把第一次的结果集看作一张表做新的查询(返回多行记录)。
2).把第一次的结果集作为过滤条件查询(返回单行记录)。
select * from student where classes_id = (select classes_id from student where name = “Li”);
in 、not in 关键字
select * from score where course_id in (4, 6);
select * from score where course_if in (select id from course where name in (‘语文’,‘数学’));
exists、not exists 关键字
select * from score sco where exists (
select sco.score from course cou where (name='语文' or name='英文') and cou.id = sco.course_id
);
EXISTS用于检查子查询是否至少会返回一行数据,该子查询实际上并不返回任何数据,而是返回值True或False,EXISTS 指定一个子查询,用来检测 行 的存在。
可以理解为:如果内查询返回的结果取非空值,则EXISTS子句返回TRUE。
注意:
-
exists 与 in 最大的区别在于 in引导的子句只能返回一个字段,比如:
select name from student where sex = 'm' and mark in (select 1,2,3 from grade where ...)
,in子句返回了三个字段1,2,3,这是不正确的,exists子句允许返回多个字段,但in只允许有一个字段返回,在1,2,3中随便去了两个字段即可。 -
EXISTS 等价于 IN,意思相同,但在语法上有点区别,使用IN效率要差点,应该是不会执行索引的原因。
1)IN查询在内部表和外部表上都可以使用到索引。
2)Exists查询仅在内部表上可以使用到索引。
3).在from子句中使用子查询:
子查询语句出现在from子句中。这里要用到数据查询的技巧,把一个子查询当做一个临时表使用。
SELECT * FROM score sco, (SELECT avg( sco.score ) score FROM score sco
JOIN student stu ON sco.student_id = stu.id
JOIN classes cls ON stu.classes_id = cls.id
WHERE cls.NAME = '中文系2019级3班') tmp
WHERE sco.score > tmp.score;
4 合并查询:
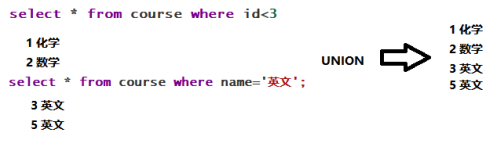
为了合并多个select的执行结果,可以使用集合操作符union,union all。使用UNION和UNION ALL时,前后查询的结果集中,字段需要一致。
select * from course where id<3 union select * from course where name='英文';
注意:
UNION 会进行合并重复项。而UNION ALL 不会合并重复项。
完整的select语句
select distinct *from 表名where ....group by ... having ...order by ...limit start,count















 4026
4026











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









