






#include <regex> //我选择了std::tr1::regex 主要是vs2010集成
#include <string>
#include <fstream> //文件读取
#include <sstream> //stringstream,方式二,文件辅助读取
using namespace std;匹配一个html(网易.htm,我已打包)文件中的所有图片,然后添加到listbox中。
实现方式一:
sregex_token_iterator
CString strFile;GetDlgItem(IDC_EDIT_HTML)->GetWindowText(strFile);//读取html文件名
//一次性读取 网易.htm 到strHtm中
ifstream file(strFile);
string strHtml;
strHtml.assign(istreambuf_iterator<char>(file.rdbuf()),istreambuf_iterator<char>());file.close();
const std::tr1::regex pattern("http://[^\\\"\\>\\<]+?\\.(png|jpg|bmp)");//简单的匹配正则
const std::tr1::sregex_token_iterator end;
for (std::tr1::sregex_token_iterator i(strHtml.begin(),strHtml.end(), pattern); i != end;++i)
{
//m_clbRegex.AddString((CString)(*i).str().c_str());//两种操作均可
m_clbRegex.AddString((CString)i->str().c_str());//m_clbRegex 为listbox的control变量
}
实现方式二:
regex_search是返回单项匹配结果,所以我们需要循环多次匹配
CString strFile;
GetDlgItem(IDC_EDIT_HTML)->GetWindowText(strFile);
ifstream file(strFile);
string strHtml;
stringstream ss;
ss<<file.rdbuf();
file.close();
strHtml=ss.str();//读取html文件到字符串
std::regex_constants::syntax_option_type fl = std::regex_constants::icase;
const std::tr1::regex pattern("http://[^\\\"\\>\\<]+?\\.(png|jpg|bmp)",fl);
std::tr1::smatch result;
std::string::const_iterator itS = strHtml.begin();
std::string::const_iterator itE = strHtml.end();
while(regex_search(itS,itE, result, pattern))//如果匹配成功
{
//m_clbRegex.AddString((CString)result[0].str().c_str());
m_clbRegex.AddString((CString)(string(result[0].first,result[0].second)).c_str());
itS=result[0].second;//新的位置开始匹配
}
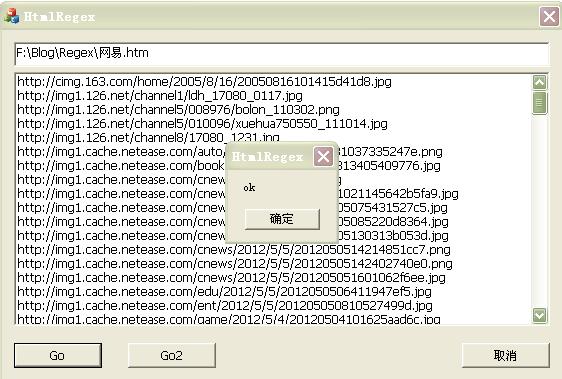
执行结果















 4334
4334











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









