







项目介绍
该项目实现服务器处理浏览器提交的不同请求,并返回给浏览器响应。项目要点在处理http请求、构建http响应、线程池提高服务器处理客户端连接任务的效率、CGI程序处理带参请求。整体逻辑,浏览器向服务器发起请求,tcpserver监听并建立连接,该连接被封装成任务加入线程池,根据请求是否带参决定是否启动CGI程序处理数据,最终构建响应返回给浏览器。
开发环境
Centos7 、C/C++、vim、g++、Makefile、postman
主要技术
网络编程(TCP/IP协议、socket套接字、http协议)、CGI技术、线程池
项目整体架构分析
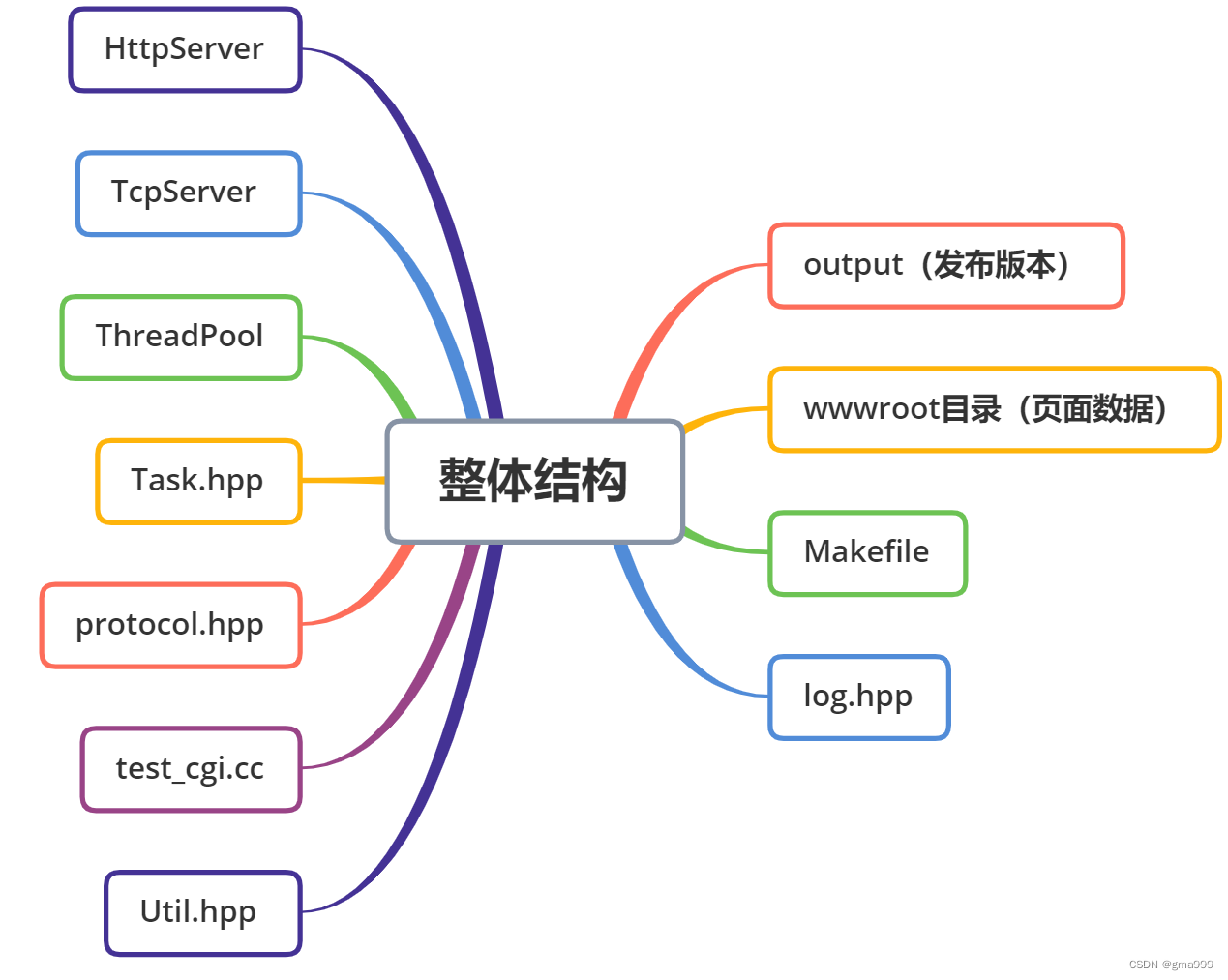
- wwwroot目录:服务器资源访问根目录。存放着请求正确以及请求错误返回的网页信息,以及CGI程序。当浏览器向服务器请求资源时,便从此处返回对应资源。
- Log.hpp:日志头文件,用来分析服务器是否正常处理请求,找到对应的错误点。
- Protocol.hpp:HTTP协议相应的类,协议请求类、协议处理类、协议响应类,回调类可以调用协议请求、处理、响应类。
- Httpserver.hpp:调用TcpServer和线程池组组件,服务器获取浏览器连接后,将其封装成任务,然后放入线程池的任务队列中,让线程池中的等待线程开始处理任务。
- Task.hpp:任务类,负责将浏览器的连接封装成任务,同时设置回调机制,设计任务处理方法。
- ThreadPool.hpp:线程池。
- TcpServer.hpp:绑定监听,设计单例模式。
- main.cc:启动http服务器,同时初始化。
项目演示
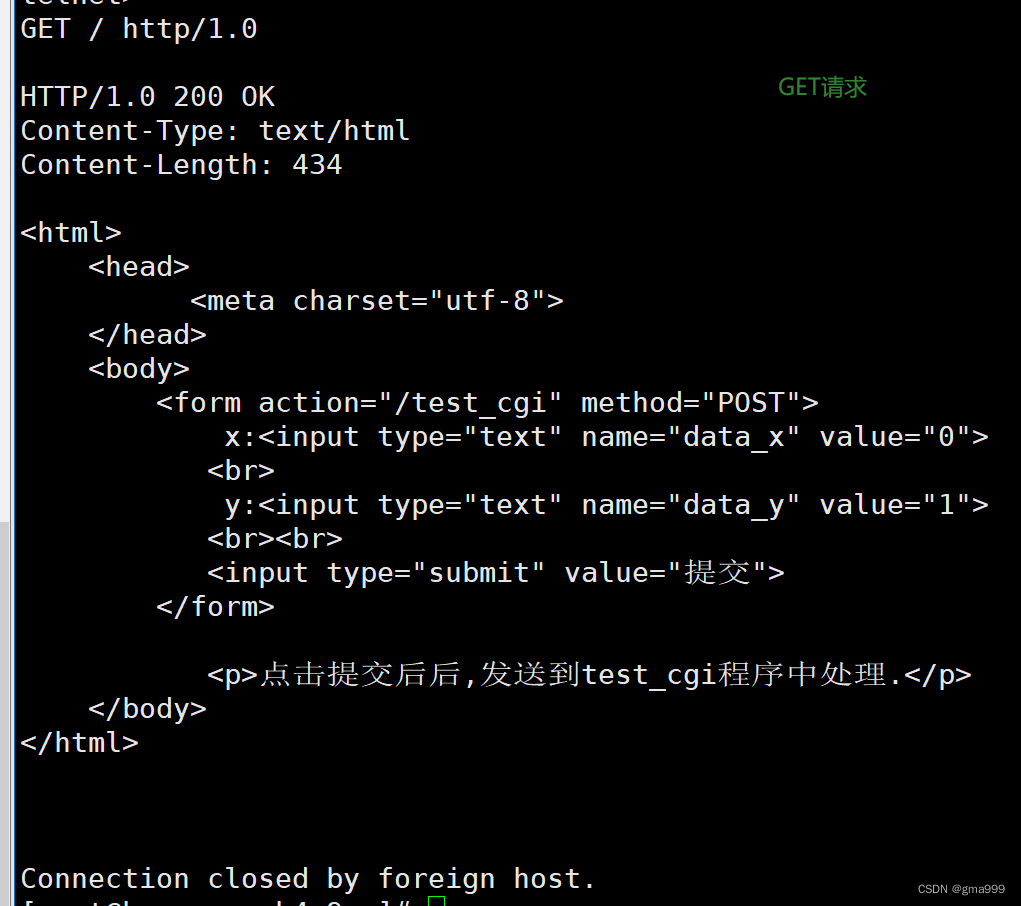
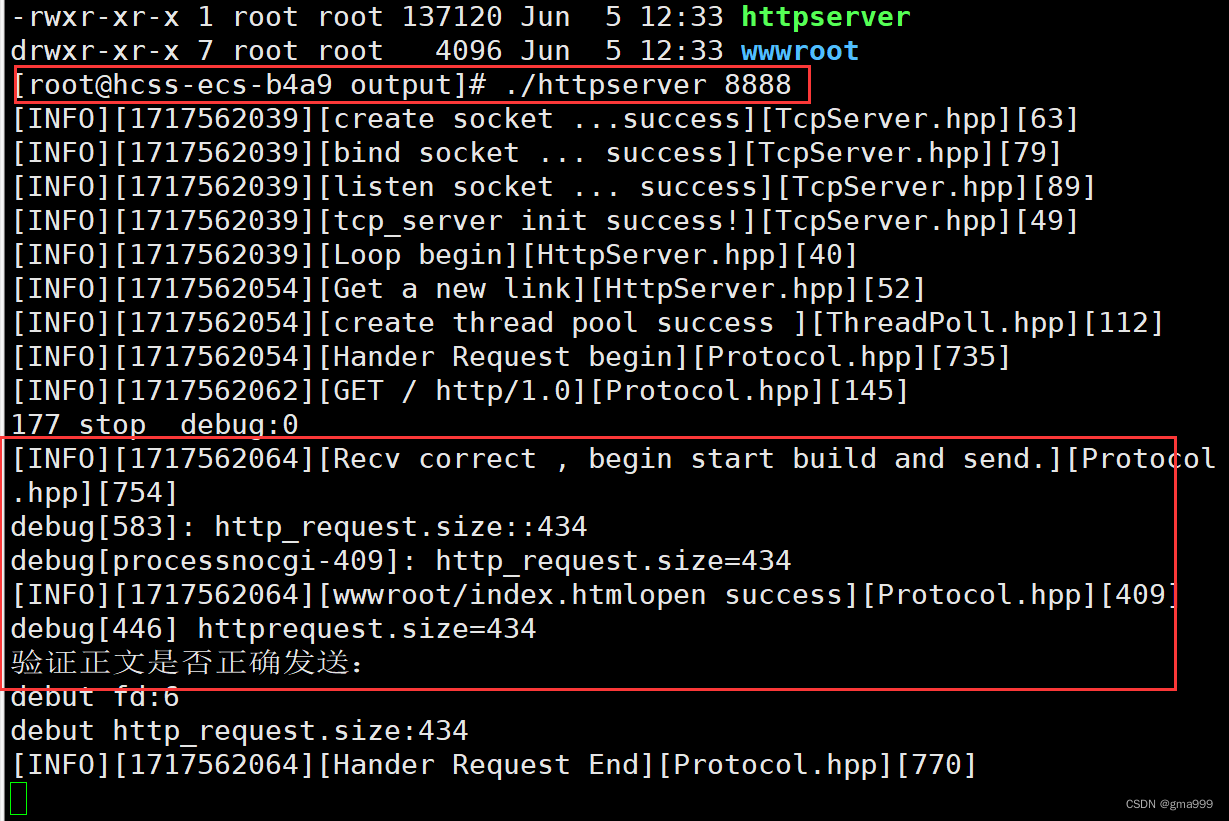
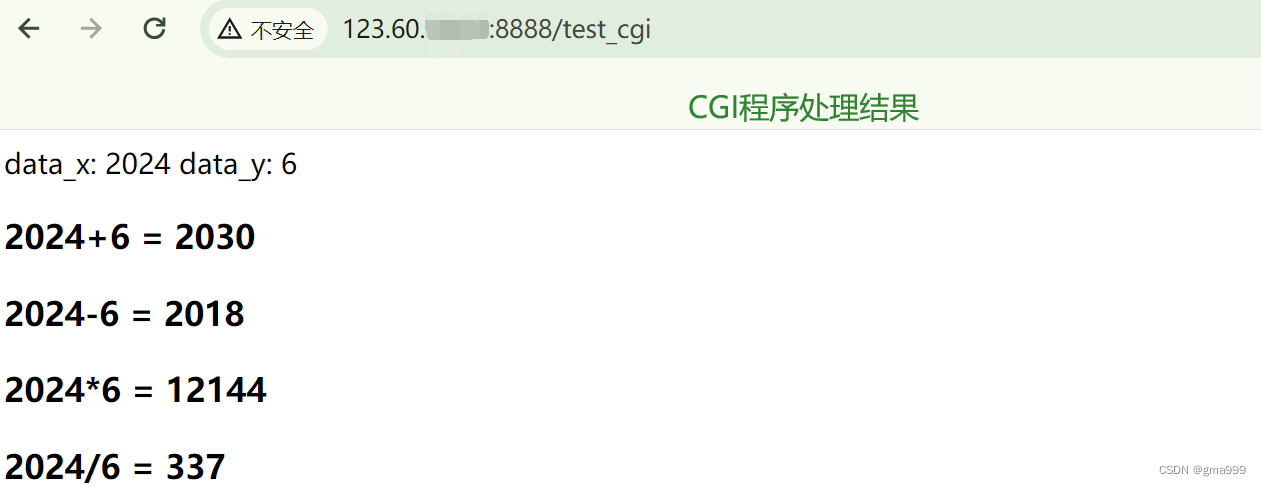
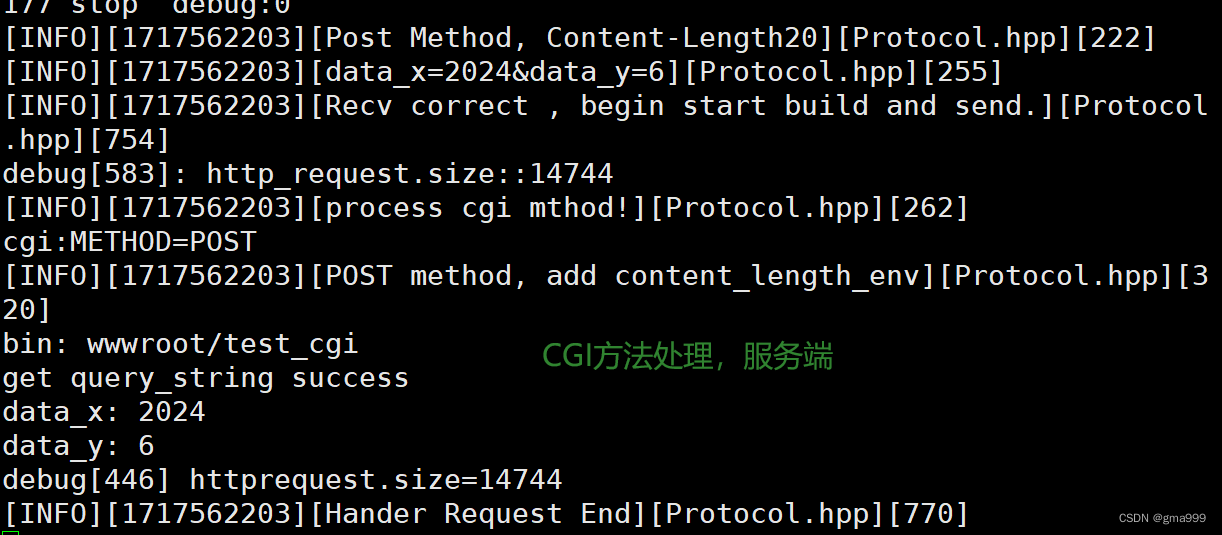

CGI技术分析
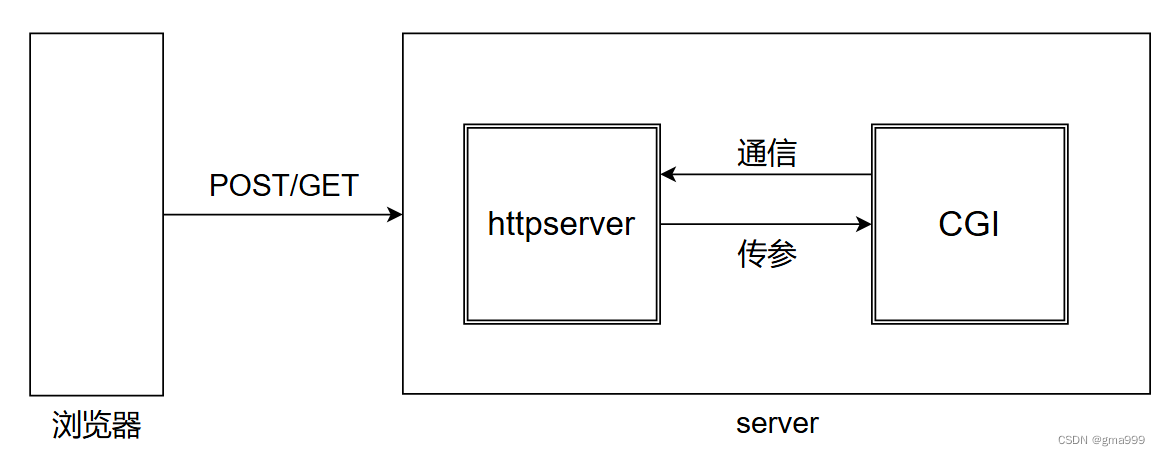
CGI原理抽象理解
浏览器和服务器通信过程简化为浏览器直接和服务器中搭建CGI程序通信。浏览器提交数据到CGI中处理,CGI返回数据的处理结果。
IO层面:子进程CGI程序的标准输入是浏览器,子进程CGI程序的标准输出是浏览器,从而抽象实现浏览器和CGI程序的直接交互。
数据提取:CGI程序利用http请求,从而拿到浏览器发送过来的数据。
浏览器和服务器通信分析
本质理解:浏览器和服务器之间通信,本质上是进程间的通信。
浏览器和服务器通信方式一:获取静态网页,浏览器向服务器发送不带参数的请求,服务器对浏览器发送的方法进行判断,根据其请求路径,返回静态网页。
浏览器和服务器通信方式二:POST\GET含参请求方法,此时服务器调用CGI执行逻辑,根据浏览器传入的方法服务器获取参数,父进程创建子进程对参数进行处理,并返回结果给父进程。
CGI逻辑下父进程和子进程交互分析:父进程(httpserver),子进程(cgi程序),子进程CGI程序的实现使用进程替换实现。父进程将数据交给子进程,子进程重定向自己进程文件描述符。子进程CGI处理好数据后,将处理好的结果放入到重定向的文件描述符中,也就是放入到http_request_body中,子进程再构建http响应后,交给父进程,父进程再将处理好的数据进行发送。
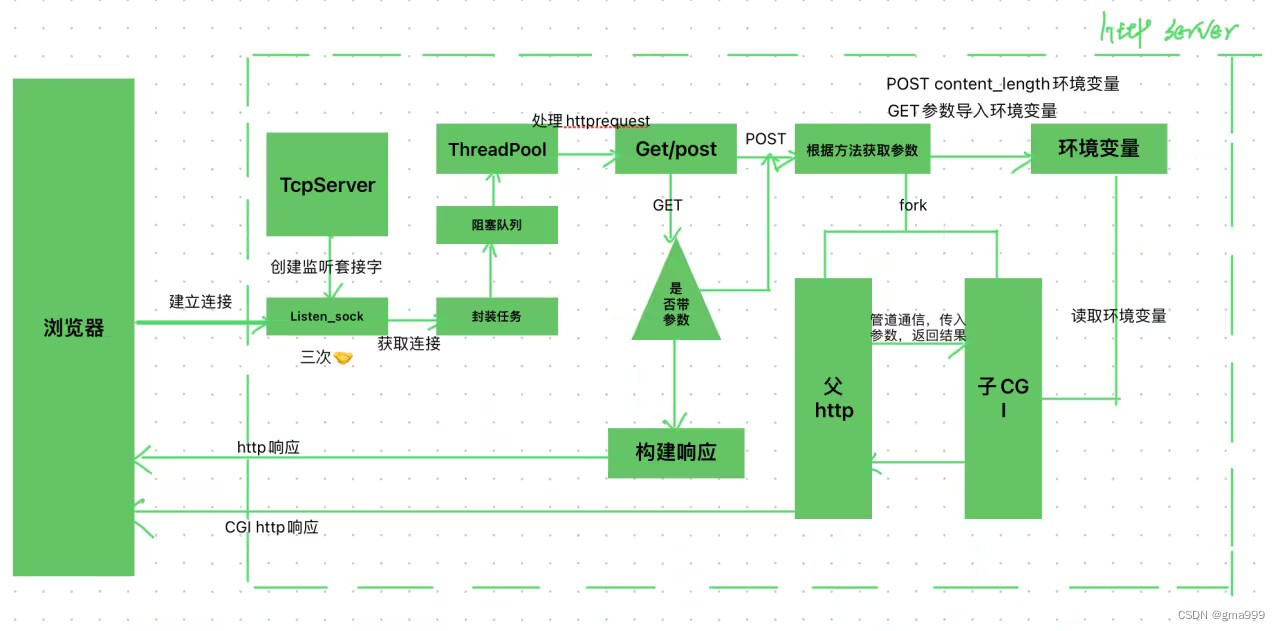
CGI处理机制分析( ProcessCgi() )
- 父子进程通信原理分析
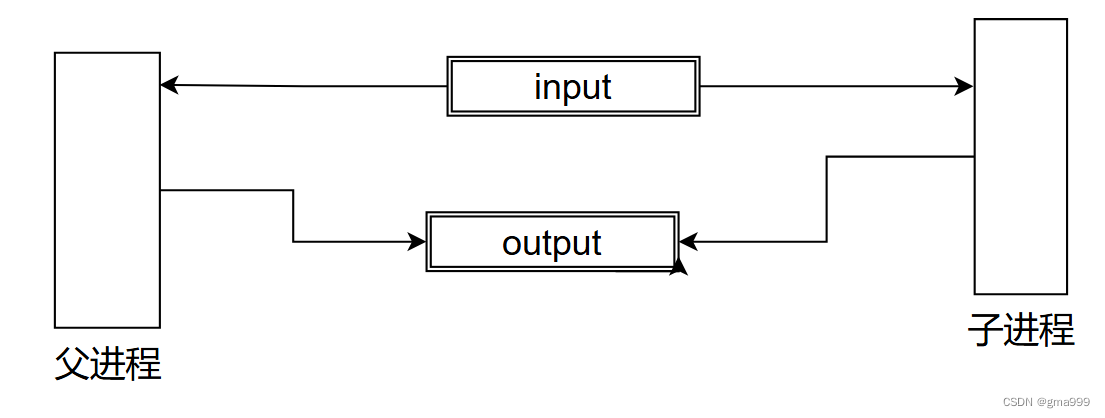
- 子进程执行CGI程序,子进程创建后复制父进程的代码,通过子进程程序替换。
int ProcessCgi()
{
LOG(INFO,"process cgi mthod!");
int code = OK;
//父进程的数据
auto&method = http_request.method;
auto&query_string = http_request.query_string; //GET
auto&body_text = http_request.request_body; //POST
//新线程执行对应代码,进程是httpserver
auto&bin = http_request.path;//get/post可执行程序
int content_length = http_request.content_length;
auto&response_body = http_response.response_body;
//利用环境变量将其导给子进程
std::string query_string_env;
std::string method_env;
std::string content_length_env;
//使用管道实现父子进程之间的双向通信
int input[2];
int output[2];
if(pipe(input)<0)
{
LOG(ERROR,"pipe input error");
code = SERVER_ERROR;
return code;
}
if(pipe(output)<0)
{
LOG(ERROR,"pipe output error");
code = SERVER_ERROR;
return code;
}
pid_t pid = fork();
if(pid == 0)
{
close(input[0]);
close(output[1]);
//子进程程序替换过后拿到方法,然后根据方法判断从哪里拿取数据
method_env = "METHOD=";
method_env += method;
std::cout<<"cgi:"<<method_env<<std::endl;
putenv((char*)method_env.c_str());
if(method == "GET")
{
query_string_env = "QUERY_STRING=";
query_string_env += query_string;
putenv((char*)query_string_env.c_str());//设置环境变量到进程中,实现父子进程都可以使用
LOG(INFO,"get method , addd query_string env");
}
else if (method == "POST")
{
content_length_env = "CONTENT_LENGTH=";
content_length_env += std::to_string(content_length);
putenv((char*)content_length_env.c_str());
LOG(INFO,"POST method, add content_length_env");
}
else
{
}
std::cout<<"bin: "<<bin<<std::endl;
//文件描述符重定向
dup2(output[0],0);
dup2(input[1],1);
//child 执行程序替换
execl(bin.c_str(),bin.c_str(),nullptr);
exit(1);//替换失败直接退出
}
else if (pid < 0)
{
LOG(ERROR,"create fork error");
}
else
{
close(input[1]);
close(output[0]);
//父进程将数据交付给子进程
if(method == "POST")
{
//将数据写入到管道
// int size = body_text.size();
int size =0;
const char*start = body_text.c_str();
int total =0;//已经写入的数据总数
while(total<content_length&&(size = write(output[1],start+total,body_text.size()-total)>0))
{
total += size;
}
}
//父进程读取子进程处理完的结果,并放入响应报文中
char ch =0;
while(read(input[0],&ch,1)>0)
{
response_body.push_back(ch);
}
//父进程等待
int status = 0;
pid_t ret = waitpid(pid,&status,0);
if(ret == pid)
{
//检测子进程是否正确退出
if(WIFEXITED(status))
{
if(WEXITSTATUS(status)==0)
{
code = OK;
}
else
{
//正常退出但是结果不正确
code = BAD_REQUEST;
}
}
else
{
//不正确退出时
code = SERVER_ERROR;
}
}
close(input[0]);
close(output[1]);
}
return code;
std::cout<<"debug:"<<"Use cgi model process"<<std::endl;
return OK;
}细节问题1:父进程传参使用管道和环境变量的原因
GET/POST传递参数的长度不一致,GET方法传递参数较短,能够实现环境变量向子进程中传入参数;POST参数长度比较大,所以需要借助管道向子进程写入数据。
GET:导入环境变量METHOD/QUERY_STRING
POST:正文从管道中写入,导入环境变量METHOD/CONTENT_LEGTH
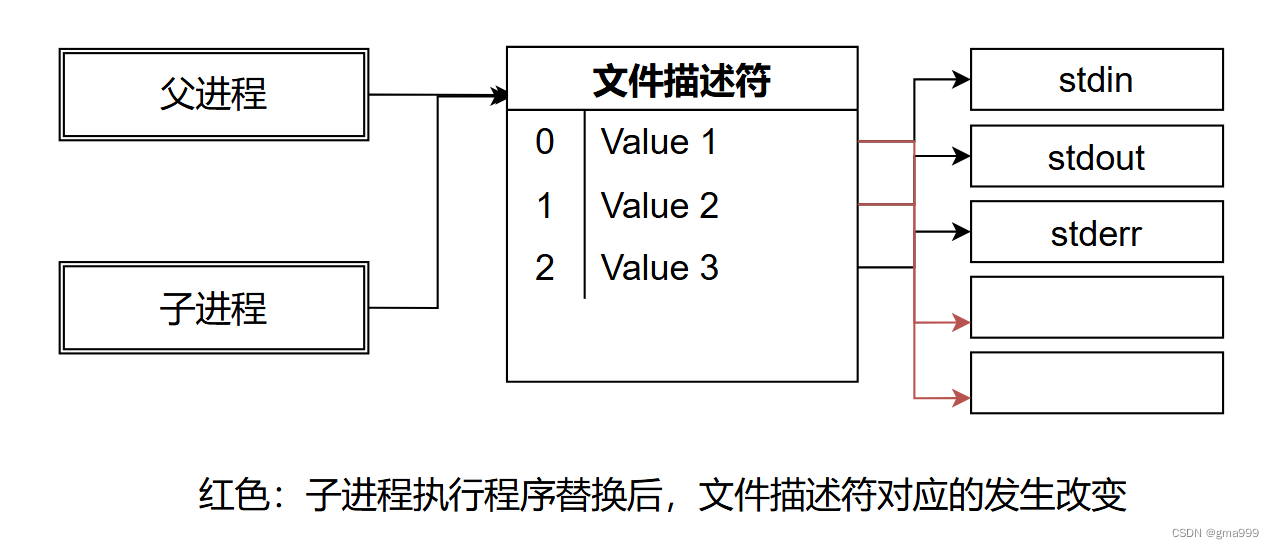
细节问题2:子进程CGI如何获得管道读写文件描述符
父子进程共享一张文件描述符表,在程序程序替换后,对读写端进行重定向即可实现。参考上图文件描述符的转变。
线程池技术分析
项目引用线程池原因分析
多线程创建会导致系统的运行变慢,线程以链表的形式在进程下创建的同时占用内存空间以及CPU资源,如果线程运行中出现的错误,则会导致内存泄漏、CPU使用超负荷等问题,从而导致服务器运行崩溃。
浏览器每次获取链接都会创建一个线程处理对应的任务;当浏览器请求变多的时候,则会加服务器的压力,使用线程池提前准备好对应线程供浏览器请求时使用。
线程池优点
使用线程池技术,预先在http服务器中预设线程,等待任务队列中填充任务,等任务填充后,便唤醒线程进行处理。从而提高线程的复用效率,同时保证处理任务的线程量。
线程池的本质结构是消费者生产者模型,最大限度的保证任务的处理的质量和效率。
本项目中线程池使用分析
浏览器提交任务到服务器,服务器将任务填充到任务队列中,此时查看线程池中是否有空余线程等待,如果有线程在等待,则直接调用该进程从任务队里中拿取任务进行处理;如果没有现成,判断线程数量是否已经超过最大的线程创建数量,此时如果没有超过最大线程数量,则创建新线程从任务队列中拿取任务处理;如果线程数量已经超过最大线程创建数量,任务队列等待线程池中有线程准备好后再执行。
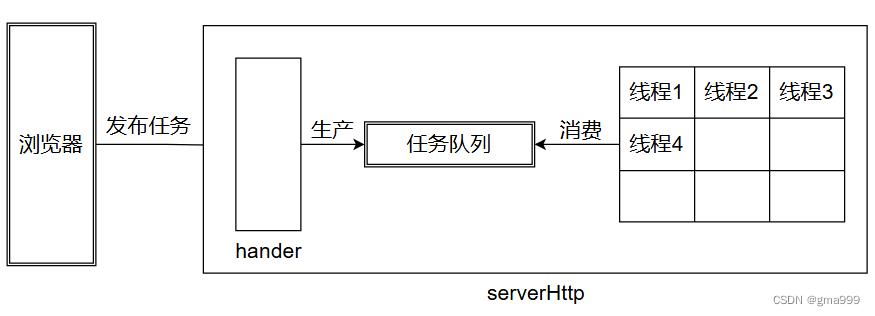
class ThreadPoll
#define NUM 6
class ThreadPoll
{
private:
int num;//线程池中线程个数
bool stop;//错误处理标志
std::queue<Task> task_queue;//任务队列
pthread_mutex_t lock;//互斥量
pthread_cond_t cond;//条件变量
ThreadPoll(int _num = NUM):num(_num),stop(false)
{
pthread_mutex_init(&lock,nullptr);
pthread_cond_init(&cond,nullptr);
}
ThreadPoll(const ThreadPoll&){}
static ThreadPoll*single_instance;
public:
//线程池单例设计
static ThreadPoll*getinstance()
{
static pthread_mutex_t _mutex = PTHREAD_MUTEX_INITIALIZER;
if(single_instance == nullptr)
{
pthread_mutex_lock(&_mutex);
if(single_instance == nullptr)
{
//类内创建线程池并完成初始化
single_instance = new ThreadPoll();
single_instance->InitThreadPoll();
}
pthread_mutex_unlock(&_mutex);
}
return single_instance;
}
//判断线程是否退出
bool IsStop()
{
return stop;
}
bool TaskQueueIsEmpty()
{
return task_queue.size()==0?true:false;
}
void Lock()
{
pthread_mutex_lock(&lock);
}
void Unlock()
{
pthread_mutex_unlock(&lock);
}
void ThreadWait()
{
//使用条件变量,条件变量满足时唤醒线程继续执行任务
pthread_cond_wait(&cond,&lock);
}
void ThreadWakeup()
{
pthread_cond_signal(&cond);
}
static void *ThreadRoutine(void*args)
{
ThreadPoll*tp = (ThreadPoll*)args;
while(true)
{
Task t;
tp->Lock();
//如果任务队列中没有任务,则让线程进行休眠;防止伪唤醒的出现,使用while循环
while (tp->TaskQueueIsEmpty())
{
tp->ThreadWait();
}
tp->PopTask(t);
tp->Unlock();
t.ProcessOn();
}
}
bool InitThreadPoll()
{
for(int i =0;i<num;i++)
{
pthread_t tid;
//线程从线程池中拿取任务执行,需要通过this指针
if(pthread_create(&tid,nullptr,ThreadRoutine,this)!=0)
{
LOG(FATAL,"create thread pool error ");
return false;
}
}
LOG(INFO,"create thread pool success ");
return true;
}
void PushTask(const Task&task)
{
Lock();
task_queue.push(task);//将任务放到任务队列中
Unlock();
ThreadWakeup();
}
void PopTask(Task&task)
{
task = task_queue.front();
task_queue.pop();
}
~ThreadPoll()
{
pthread_mutex_destroy(&lock);
pthread_cond_destroy(&cond);
}
};
ThreadPoll*ThreadPoll::single_instance = nullptr;项目模块
任务处理类(EndPoint)
功能:读取请求、分析请求、处理请求、构建请求、返回响应。
成员变量分析:
- http_request: http请求对象
- http_response: http响应对象
- sock: 通信套接字
- stop: 任务停止标志
读取请求处理逻辑:
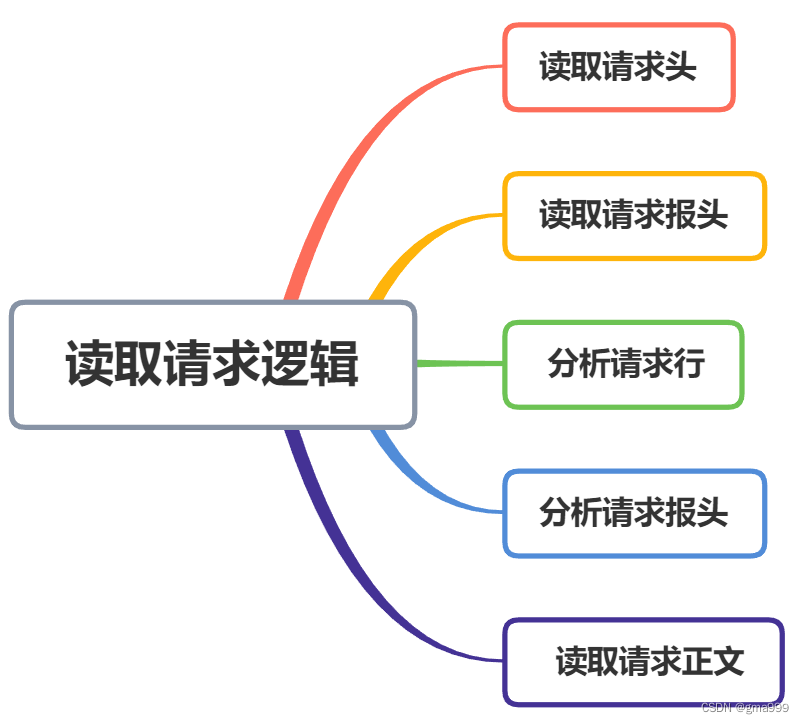
读取http请求
void RcvHttpRequest():读取请求逻辑,如果请求行和请求头读取失败(没内容或者请求错误),则后续没必要继续处理请求以及读取正文。
//读取请求
void RcvHttpRequest()
{
//如果请求行和请求头出错,便没有必要继续向下执行
if((!RecvHttpRequestLine())&&( !RecvHttpRequestHeader()))
{
ParseHttpRequestLine();
ParseHttpRequestHeader();
RecvHttpRequestBody();
}
}读取http请求行
bool RecvHttpRequestLine() :工具类ReadLine对读取内容统一分割转换成‘\n’。读取出错时,将错误表示stop设置为真,否则就保持其初始化状态。
bool RecvHttpRequestLine()
{
auto &line = http_request.request_line;
//读取首行到http_request的首行中去
if(Util::ReadLine(sock,line)>0)
{
line.resize(line.size()-1);
LOG(INFO,http_request.request_line);
}
else
{
//读取出错
stop = true;
}
return stop;
} 读取http请求报头
bool RecvHttpRequestHeader():读取请求报头,请求报头以\n为分割,划分为多行,分行读取,读取后放入vector容器存储,如果读取错误,设置错误标志为真,并开始相应的错误处理。
bool RecvHttpRequestHeader()
{
std::string line;
while(true)
{
//读取前保证缓冲Line为空
line.clear();
//读取发送消息出错
if(Util::ReadLine(sock,line)<=0)
{
stop = true;
break;
}
if(line == "\n")
{
http_request.blank = line;
break;
}
line.resize(line.size()-1);
http_request.request_header.push_back(line);
}
return stop;
}
解析请求逻辑
处理http请求行
void ParseHttpRequestLine():处理请求行,分解请求行,将请求方法、请求URI、http版本存放在http_request的变量成员中。
void ParseHttpRequestLine()
{
auto & line = http_request.request_line;
std::stringstream ss(line);
ss>>http_request.method>>http_request.url>>http_request.version;
//将请求全部转化为大写
auto&method = http_request.method;
std::transform(method.begin(),method.end(),method.begin(),::toupper);
}
transform函数的使用 
处理请求报头
void ParseHttpRequestHeader():分析请求报头,按照分隔符进行分割,然后将内容存入到哈希表中。
void ParseHttpRequestHeader()
{
std::string key;
std::string value;
for(auto & iter:http_request.request_header)
{
if(Util::CutString(iter,key,value,SEP))
{
http_request.header_kv.insert({key,value});
}
}
}
判断是否需要读取正文
bool IsNeedRecvHttpRequestBody():判断是否需要读取请求正文,只有POST方法而且报文的确含有内容的时候才进行读取。同时填充Content_length的大小。
bool IsNeedRecvHttpRequestBody()
{
auto &method = http_request.method;
if(method == "POST")
{
auto &header_kv = http_request.header_kv;
auto iter = header_kv.find("Content-Length");
if(iter != header_kv.end())
{
LOG(INFO,"Post Method, Content-Length"+iter->second);
//转换成整数存储到content_length中
http_request.content_length = atoi(iter->second.c_str());
//确认使用POST方法,并且报文有相应长度的时候,下面便可以开始报文的读取
return true;
}
}
return false;
}
读取http正文内容
void RecvHttpRequestBody():读取http请求正文。按照请求正文的具体长度,依次读取http请求正文的内容。将http请求正文中的数据存放到请求类中http_request_body成员中。
bool RecvHttpRequestBody()
{
if(IsNeedRecvHttpRequestBody())
{
int content_length = http_request.content_length;//读取内容的长度
auto &body = http_request.request_body;//内容
char ch =0;
while (content_length)
{
ssize_t s = recv(sock,&ch,1,0);
if(s>0)
{
body.push_back(ch);
content_length--;
}
else
{
//读取请求报文时出错
stop = true;
break;
}
}
LOG(INFO,body);
}
return stop;
}CGI方法处理传入参数
int ProcessCgi():使用CGI方法处理数据。利用环境变量实现父子进程之间的传递变量的目的。管道实现的父子进程之间的通信。替换程序接口使得子进程可以执行自己的程序,然后根据具体请求方法,处理传入的数据。具体实现分析参考CGI技术的实现。
非CGI方法处理传入参数
int ProcessNonCgi():使用非CGI方法处理请求,如果浏览器传入的请求不是CGI方法,则使用该程序实现请求的处理。打开对应的文件资源,文件打开失败设置状态码NOT_FOUND,打开成功时,返回状态码OK。
int ProcessNonCgi()
{
http_response.fd = open(http_request.path.c_str(),O_RDONLY);
std::cout<<"debug[processnocgi-409]: http_request.size="<<http_request.size<<std::endl;
//只有打开文件成功,才构建以下属性
if(http_response.fd >= 0)
{
LOG(INFO,http_request.path+"open success");
return OK;
}
return NOT_FOUND;
}
构建响应逻辑:
正确响应构建的实现思路
- 响应必须包含Content-Length 和 Content-Type
- Content-Length:是否调用CGI影响其大小
- CGI机制:正文在response_body中,所以此处填充response_body的大小。
- 非CGI机制:等价于目标资源文件的大小。
构建正确响应代码分析
void BuildHttpResponse()
- 判断请求方法
- GET方法:判断是否含有参数,通过判断是否有'?’判断
- 含参数:URI字符串分割,将其变成uri_path和uri_query,此时有数据上传所以需要启动CGI方法进行处理。
- 不含参数:path等价于URI,则调用非CGI机制方法。
- POST方法:使用CGI机制进行吹了
- GET方法:判断是否含有参数,通过判断是否有'?’判断
- 资源路径分析
- 没有指定的访问路径,则返回首页信息
- 访问资源路径存在
- 访问资源是一个目录文件,需要加上对应的网页路径信息,同时更新请求的路径(因为路径在该局部区域中被更改了,如果不更新则会导致后续的文件路径出现错误)。
- 访问资源是可执行文件,调用CGI机制进行处理。
- 文件资源路径正确
- 找到文件具体后缀,.html,如果没有找到对应的后缀,则自动加上后缀。
- 访问资源路径不存在
- 将状态改为NOT_FOUND。
- 判断请求是否是CGI方法
- 如果是CGI方法则调用CGI机制进行相应的处理。
- 如果非CGI机制,则调用非CGI机制处理任务。
//构建响应
void BuildHttpResponse()
{
//请求读完,构建响应
std::string _path;
// int size=0;
struct stat st;//获取文件属性的结构体
std::size_t found = 0;
auto&code = http_response.status_code;
if(http_request.method !="GET" && http_request.method!="POST")
{
//非法请求处理
LOG(WARNING,"http method is not found");
code = BAD_REQUEST;
goto END;
}
//GET方法下确认请求报文是否带参,然后进行相应的处理
if(http_request.method == "GET")
{
size_t pos = http_request.url.find('?');
if(pos!=std::string::npos)
{
Util::CutString(http_request.url ,http_request.path,http_request.query_string,"?");
//get方法带参处理同样使用cgi
http_request.cgi = true;
}
else
{
//不带参数情况,路径就是初始只
http_request.path = http_request.url;
}
}
else if(http_request.method=="POST")
{
//POST方法处理
http_request.cgi = true;
//设置POST方法的请求路径
http_request.path = http_request.url;
}
else
{
}
//给请求加上自己的根目录
_path = http_request.path;
http_request.path = WEB_ROOT;
http_request.path+=_path;
//如果没有指定访问资源,则返回首页信息
if(http_request.path[http_request.path.size()-1]=='/')
{
http_request.path+=HOME_PAGE;
}
//如果获取请求路径资源成功,则证明资源是存在的,否则资源不存在
if(stat(http_request.path.c_str(),&st)==0)
{
//资源存在
if(S_ISDIR(st.st_mode))
{
//此时访的是一个目录,需要对其进行处理(上述请求的路径中不带/,所以此时需要加上)
http_request.path +="/";
http_request.path +=HOME_PAGE;
//重新获取其属性信息
stat(http_request.path.c_str(),&st);
}
//如果三种文件属性任意一个存在,则表示文件是可执行的
if((st.st_mode&S_IXUSR)||(st.st_mode&S_IXGRP)||(st.st_mode&S_IXOTH))
{
http_request.cgi = true;
}
// size = st.st_size;
std::cout<<"debug[583]: http_request.size::"<< http_request.size<<std::endl;
}
else
{
LOG(WARNING,http_request.path +"Not Found");
code = NOT_FOUND;
goto END;
}
//此时文件一定存在path中,提取文件的后缀
found = http_request.path.rfind(".");
if(found == std::string::npos)
{
//没找到默认将其后缀设置成.html
http_request.suffix = ".html";
}
else
{
http_request.suffix = http_request.path.substr(found);
}
if(http_request.cgi)
{
//cgi方式处理请求;执行目标程序,拿到结果放到http_response.response_body中
code = ProcessCgi();
}
else
{
//非cgi方式处理请求,返回静态网页(构建http响应)
code = ProcessNonCgi();//CGI只需要将网页打开即可
}
END:
BuildHttpResponseHelper();
return;
}细节问题1:系统调用stat,判断文件属性。
- 作用:根据文件路径找到文件并提取文件属性,判断文件是否存在。
- 返回值:0成功,-1文件未找到。
- 标志位判断:S_IXUSR / S_IXGRP / S_IXOTH满足其中一个则是可执行文件。
- 函数原型: int stat(const char *pathname, struct stat *buf);
细节问题2:npos
- 作用:表示string的结束位置,此处也就是遍历到最后。
错误码处理
void BuildHttpResponseHelper():错误码处理,构建状态行和响应正文。
//错误码处理
void BuildHttpResponseHelper()
{
//错误码都在响应的状态码中
auto&code = http_response.status_code;
//构建响应的状态行
auto&status_line = http_response.status_line;
status_line += HTTP_VERSION;
status_line += " ";
status_line += std::to_string(code);
status_line += " ";
status_line += Code2Desc(code);
status_line += LINE_END;
//构建响应正文
std::string path = WEB_ROOT;
path +="/";
switch(code)
{
case OK:
BuildOKResponse();
break;
case NOT_FOUND:
path+=PAGE_404;
HandlerError(path);//返回404错误码网页
break;
case BAD_REQUEST:
path+=PAGE_404;
HandlerError(path);
break;
case SERVER_ERROR:
path+=PAGE_404;
HandlerError(path);
break;
//case 502
// HandlerError(PAGE_502);
default:
break;
}
}根据后缀获取文本类型
static std::string Suffix2Desc(const std::string &suffix):根据文件后缀得到文本的类型
static std::string Suffix2Desc(const std::string &suffix)
{
static std::unordered_map<std::string,std::string> suffix2desc =
{
{".html","text/html"},
{".css" , "text/css"},
{".js" , "application/javascript"},
{".jpg","application/x-jpg"},
{".xml","application/xml"},
};
auto iter = suffix2desc.find(suffix);
if(iter != suffix2desc.end())
{
//找到了目标后缀
return iter->second;
}
//没找到则使用默认值
return "text/html";
}构建正确响应
void BuildOKResponse():构建正确响应,根据http请求是否CGI方法,构建对应的响应报头响应正文
void BuildOKResponse()
{
// struct stat st;
std::string line = "Content-Type: ";
line+=Suffix2Desc(http_request.suffix);
line+=LINE_END;
http_response.response_header.push_back(line);
line = "Content-Length: ";
if(http_request.cgi)
{
line += std::to_string(http_response.response_body.size());//post方法
}
else
{
line += std::to_string(http_request.size);//GEt
}
line += LINE_END;
http_response.response_header.push_back(line);
}构建错误响应
void HandlerError(std::string page) :构建错误响应,将CGI标志位设置为false,构建文件返回错误页面,同时向响应报头中填充对应的数据以供发送。
void HandlerError(std::string page)
{
std::cout<<"[414]debug : "<<page<<std::endl;
//如果出现错误,则将cgi设置成为false
http_request.cgi = false;
//构建文件,返回404页面
http_response.fd = open(page.c_str(),O_RDONLY);
if(http_response.fd>0)
{
//获取页面属性验证是否成功
struct stat st;
stat(page.c_str(),&st);
http_request.size = st.st_size;
//响应报头中填写数据
std::string line = "Content-Type: text/html";
line += LINE_END;
http_response.response_header.push_back(line);
line += "Content-Length: ";
line += std::to_string(st.st_size);
line+= LINE_END;
http_response.response_header.push_back(line);
}
}
发送响应逻辑
void SendHttpResponse():状态行发送、响应报头发送、空行发送、正文发送。
void SendHttpResponse()
{
//发送状态行
send(sock,http_response.status_line.c_str(),http_response.status_line.size(),0);
//发送响应报头
for(auto iter : http_response.response_header)
{
send(sock,iter.c_str(),iter.size(),0);
}
//发送空行
send(sock,http_response.blank.c_str(),http_response.blank.size(),0);
//正文发送,根据不同请求的类型判断从 fd/response_body 发送数据
if(http_request.cgi)
{
auto&response_body = http_response.response_body;
size_t size =0;
size_t total =0;
const char*start = response_body.c_str();
while (total < response_body.size()&&(size=send(sock,start+total,response_body.size() - total,0)>0))
{
/* code */
total += size;
}
}
else
{
sendfile(sock,http_response.fd,nullptr,http_request.size);
close(http_response.fd);
}
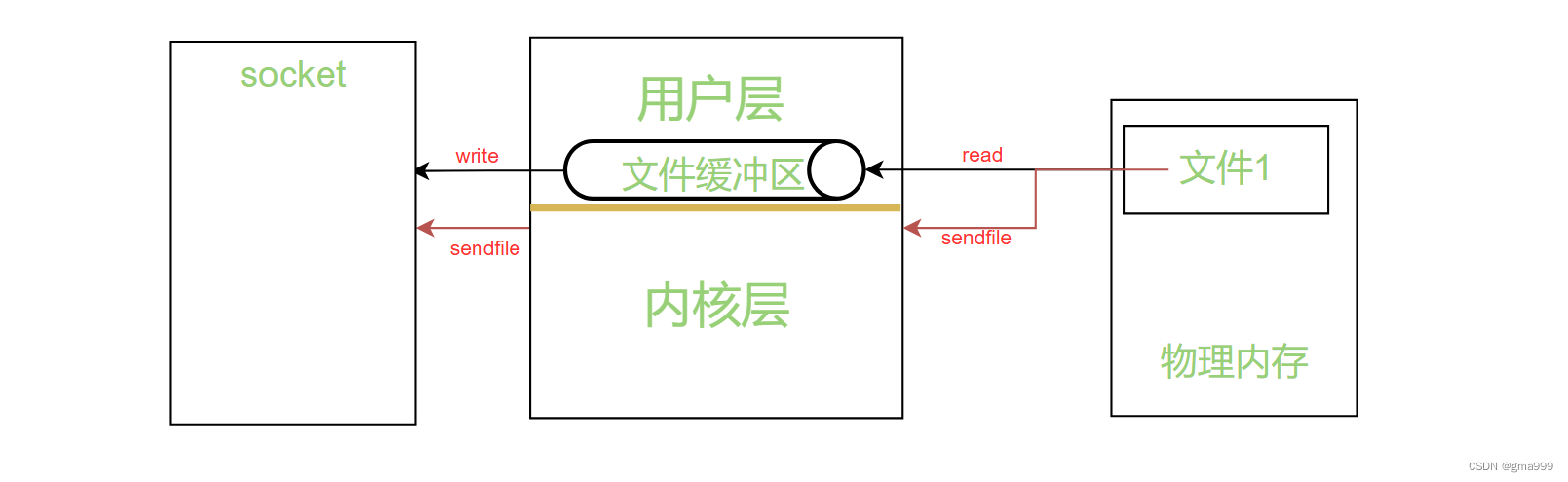
}细节理解1:sendfile系统接口提高文件拷贝效率。
- CGI机制下,正文内容存放在response_body中;非CGI机制,发送资源文件到浏览器。
- write/read接口实现:从磁盘中读取文件的到用户层缓冲区中,然后再从用户层缓冲区写入到到sock内核的缓冲区中。
- 原型:#include <sys/sendfile.h>
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count); - 作用:将一个文件描述符中存储的内容,直接拷贝到的另一个文件描述符中,直接通过内核完成该操作。
- 参数:out_fd(写入文件描述符); in_fd(读取文件描述符); Offset(偏移量,记录读取文件的位置);count(拷贝内容的大小)
- 返回值:失败返回-1,成功返回写入数据的大小。
回调类设计
任务总结回调类服务于任务类,处理Http请求和Http响应,依次调用方法类EndPoint类中的方法,Http请求方法读取完成后,对stop标志位进行分析,如果标记位为真则继续构建响应,如果stop标记位为假则不构建响应。
class CallBack
{
public:
CallBack()
{}
//设计仿函数
void operator()(int sock)
{
HandlerRequest(sock);
}
void HandlerRequest(int sock)
{
LOG(INFO,"Hander Request begin");
char buffer[4096];
recv(sock,buffer,sizeof(buffer),0);
EndPoint*ep = new EndPoint(sock);
ep->RcvHttpRequest();
// ep->ParseHttpRequest();
//读取请求内容正确时,才需要继续向下执行
if(!ep->IsStop())
{
//出错点:ture代表出错,只有!true时才代表没有出错,向后运行才行
LOG(INFO,"Recv correct , begin start build and send.")
ep->BuildHttpResponse();
ep->SendHttpResponse();
}
else
{
LOG(WARNING,"Recv error, stop build and send.");
}
delete ep;
LOG(INFO,"Hander Request End");
}
~CallBack()
{}
};日志打印
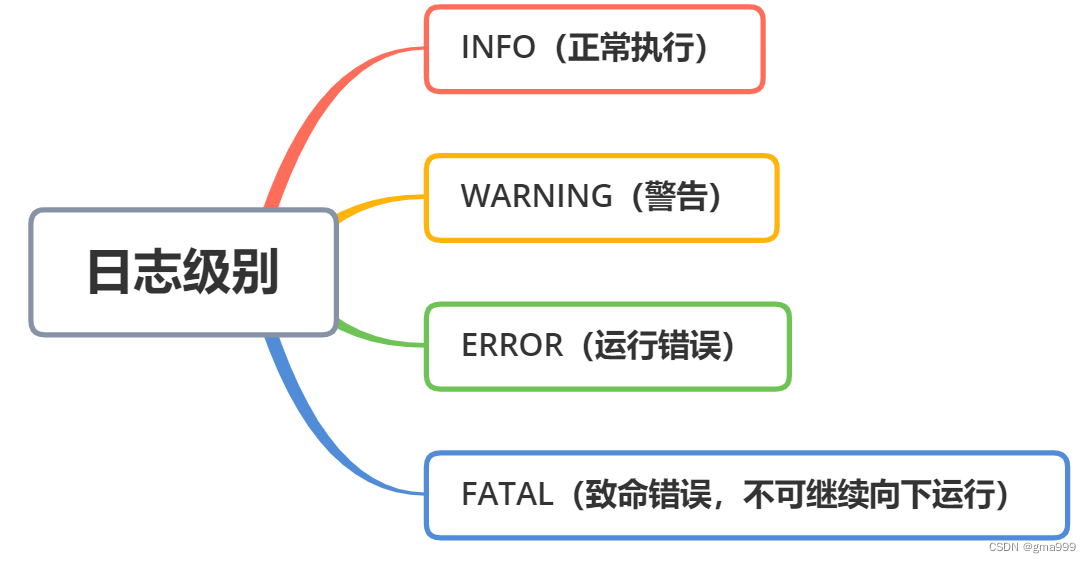
日志打印的基本格式:【日志级别】【日志信息】【错误文件名称】【错误行】
日志四个级别:INFO(正常执行);WARNING(警告);ERROR(运行错误);FATAL(致命错误,不可继续向下运行)
实现方式
- 用宏实现后面两个参数的替换
- 错误文件名称通过__FILE__获得
- 错误行信息通过__LINE__获得
- 使用时,仅需要输入日志级别和日志信息即可
#include<iostream>
#include<string>
#include<ctime>
#define INFO 1
#define WARNING 2
#define ERROR 3
#define FATAL 4
#define LOG(level,message) Log(#level,message,__FILE__,__LINE__);
//日志级别;日志信息;时间戳;错误文件名称;错误文件的行数
void Log(std::string level,std::string message,std::string file_name,int line)
{
std::cout<<"["<<level<<"]"<<"["<<time(nullptr)<<"]"
<<"["<<message<<"]"<<"["<<file_name<<"]"<<"["<<line<<"]"<<std::endl;
}TcpServer类
#define BACKLOG 5
class TcpServer
{
private:
int port;
int listen_sock;
static TcpServer*svr;
private:
TcpServer(int _port):port(_port),listen_sock(-1)
{}
TcpServer(const TcpServer&s){}
public:
//单例模式
static TcpServer*getinstance(int port)
{
static pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
if(nullptr == svr)
{
pthread_mutex_lock(&lock);
if(nullptr == svr)
{
svr = new TcpServer(port);
svr->InitServer();
}
pthread_mutex_unlock(&lock);
}
return svr;
}
void InitServer()
{
Socket();
Bind();
Listen();
LOG(INFO,"tcp_server init success!");
}
void Socket()
{
listen_sock = socket(AF_INET,SOCK_STREAM,0);
if(listen_sock<0)
{
LOG(FATAL,"socket error");
exit(1);//套接字创建失败
}
//socket地址复用
int opt =1;
setsockopt(listen_sock,SOL_SOCKET,SO_REUSEADDR,&opt,sizeof(opt));
LOG(INFO,"create socket ...success");
}
void Bind()
{
struct sockaddr_in local;
memset(&local,0,sizeof(local));
local.sin_family = AF_INET;
local.sin_port = htons(port);
local.sin_addr.s_addr = INADDR_ANY;//云服务器是无法直接绑定公网IP的
if(bind(listen_sock,(struct sockaddr*)&local,sizeof(local))<0)
{
LOG(FATAL,"bind error");
exit(2);//绑定失败
}
LOG(INFO,"bind socket ... success");
}
void Listen()
{
if(listen(listen_sock,BACKLOG)<0)
{
LOG(FATAL,"listen socket error");
exit(3);//监听失败
}
LOG(INFO,"listen socket ... success");
}
int Sock()
{
return listen_sock;
}
~TcpServer()
{}
};
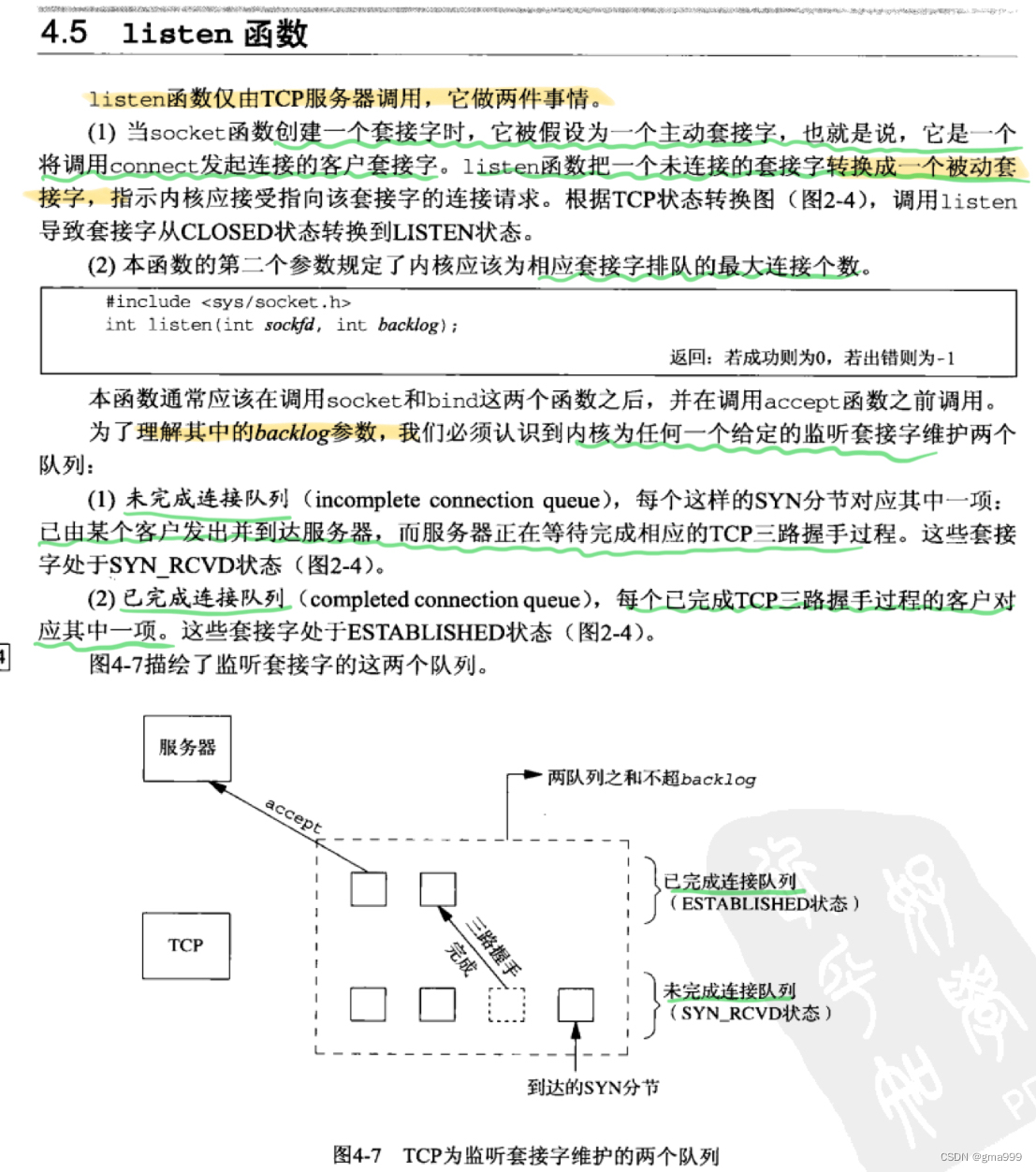
TcpServer*TcpServer::svr = nullptr;细节问题1:listen实现理解
listen在socket内核结构中找到一块空间,申请全连接和半连接队列,同时对其初始化。其中全连接队列是链表结构,半连接队列是的哈希表结构。
Tcp连接过程分析(三次握手)
- 服务器设置监听,申请并初始化接收队列,初始化的接收队列包括半连接队列和全连接队列。
- 客户端connect(),客户端选择本地可用的端口用于连接服务端;客户端向服务端发出SYN握手请求;启动超时重传计时器。
- 服务端接收到客户端的SYN请求后,服务端给客户端发送SYN ACK确认信息,并将该连接放入半连接队列,启动定时器。
- 客户端收到服务端的SYN ACK确认后,清除重传定时器,将连接状态设置成为已连接状态,客户端向服务端发送ACK确认。
- 服务端收到客户端ACK信号后,服务端创建新的sock,将之前加入的半连接队列的连接删除;并将该连接放入全连接队列中。
- Accept():从全队列中取走socket
细节问题2: 单例模式的实现
单例模式理解:内存中仅且只会创建一次对象的设计模式。进程运行调用该对象功能时,不需要重复创建该对象浪费内存资源,只需在内存中创建一个, 其他所有对象都可以共享该对象的内容。
工具类Util
作用: 分析协议时,对字符串进行处理函数。
ReadLine
功能:不同浏览器发送请求的换行符不同,利用该函数将不同的换行符换成统一的'\n'形式。
具体实现:
- 逐个读取字符,如果不是 \r \n ,则将其直接加入out中。
- 读取字符时\r时,可能出现\r\n的情况,使用MSG_PEEK窥探选项,实现只读不拷贝的方式,确认\r后面的字符是什么。
- 如果后面的字符时 \n ,则直接将 \n拿走即可
- 如果不是,则要手动添加 \n
- 上述步骤完成后,检验ch字符是否为 \n ,如果是则表示该行信息已经读取完成,将该字符加入out中,停止读取动作返回其大小。
//将读取的行内容拿走
static int ReadLine(int sock, std::string&out)
{
char ch = 'X';
while (ch!='\n')
{
//以阻塞方式将sock缓冲区中的数据读到ch中
ssize_t s = recv(sock,&ch,1,0);
if(s>0)
{
//\r->\n | \r\n -> \n
if(ch == '\r')
{
//利用recv的MSG_PEEK向后窥探功能,查看后面是否还存在数据
recv(sock,&ch,1,MSG_PEEK);
if(ch=='\n')
{
//窥探成功,字符一定存在
recv(sock,&ch,1,0);
}
else
{
ch = '\n';
}
}
out.push_back(ch);
}
else if(s==0)
{
return 0;
}
else
{
return -1;
}
}
return out.size();
}CutString
功能:HTTP报头信息以kv方式存储。将kv模型分割成两个字符串,然后进行存储。
//字符串按照特定的符号进行切割(目标,个数,输出,分隔符)
static bool CutString(const std::string&target , std::string & sub1_out,std::string&sub2_out,std::string sep)
{
size_t pos = target.find(sep);//找到分隔符的下标
if(pos!=std::string::npos)
{
sub1_out = target.substr(0,pos);
sub2_out = target.substr(pos+sep.size());
return true;
}
return false;
}Httpserver类
作用:服务器启动后,HttpServer将TcpServer和线程池加入到这个类中,该服务主要负责获取浏览器连接,将浏览器的连接封装成任务放入线程池,线程池调用线程处理该任务。
成员变量和成员方法: port(绑定端口号);stop(服务器停止运行标志);InitServer(初始化服务器);Loop(服务器运行)
细节问题:防止浏览器断开连接后导致服务器崩溃
浏览器和服务器连接后,向服务器中写入数据,此时关闭连接,操作系统会向服务器发送SIGPIPE信号给服务器,从而导致服务器的崩溃。
综上为了防止该问题的出现,在服务器初始化的时候忽略其信号,将SIGPIPE信号忽略掉。
#define PORT 8888
class HttpServer
{
private:
int port;
// TcpServer*tcp_server;
// ThreadPoll thread_poll;
bool stop; //标记服务状态
public:
// HttpServer(int _port=PORT)
// :port(_port),tcp_server(nullptr),stop(false)
// {}
HttpServer(int _port=PORT)
:port(_port),stop(false)
{}
void InitServer()
{
//避免写入时,server崩溃,忽略SIGPIPE信号
signal(SIGPIPE,SIG_IGN);
// tcp_server = TcpServer::getinstance(port);
}
//启动服务
void Loop()
{
TcpServer*tsvr = TcpServer::getinstance(port);
LOG(INFO,"Loop begin")
// int listen_sock = tcp_server->Sock();
while(!stop)
{
struct sockaddr_in peer;
socklen_t len = sizeof(peer);
// int sock = accept(listen_sock ,(struct sockaddr*)&peer,&len);
int sock = accept(tsvr->Sock(),(struct sockaddr*)&peer,&len);
if(sock<0)
{
continue;
}
LOG(INFO,"Get a new link");
//构建任务
Task task(sock);
//向线程池中传入任务z
ThreadPoll::getinstance()->PushTask(task);
}
}
~HttpServer()
{}
};协议请求
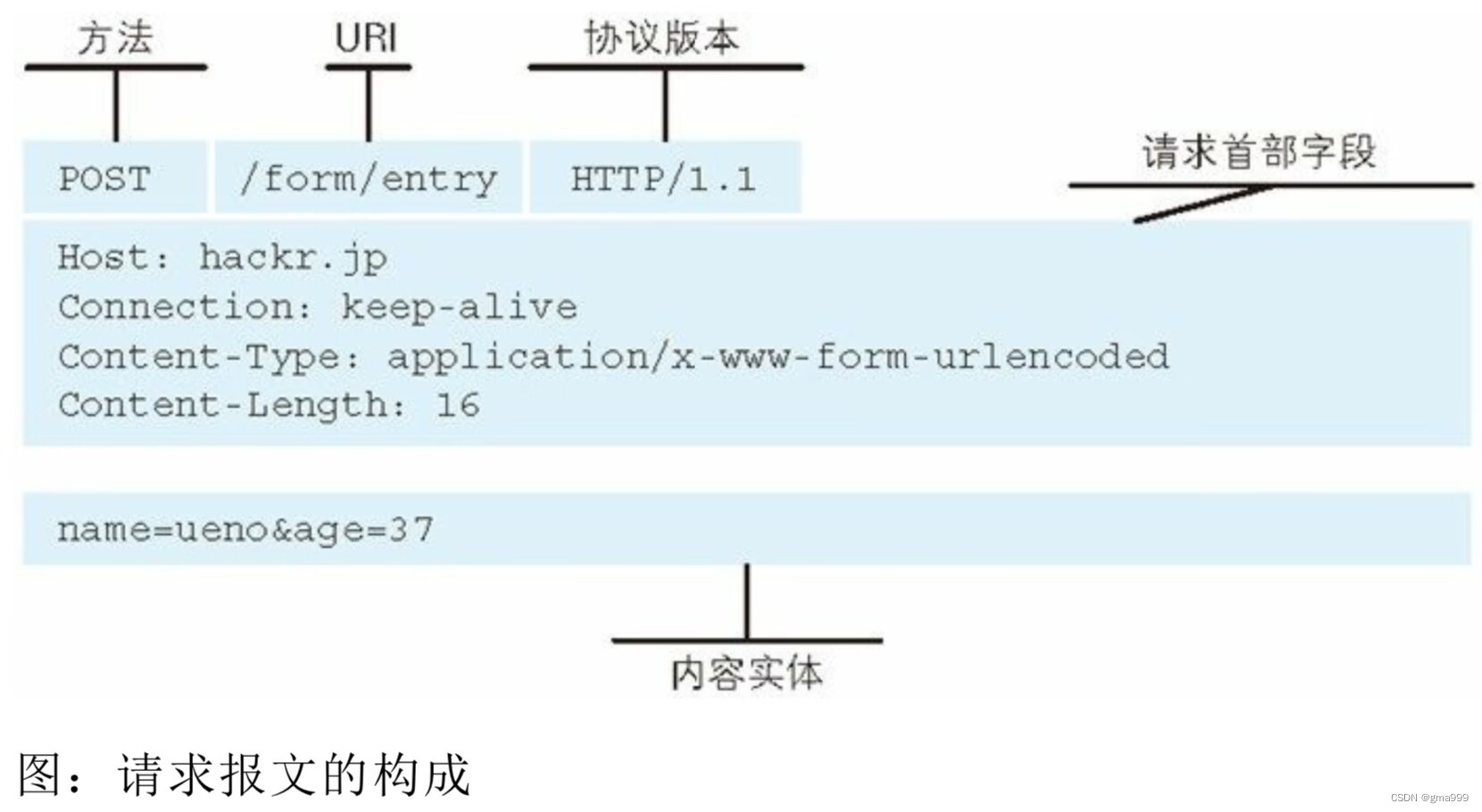
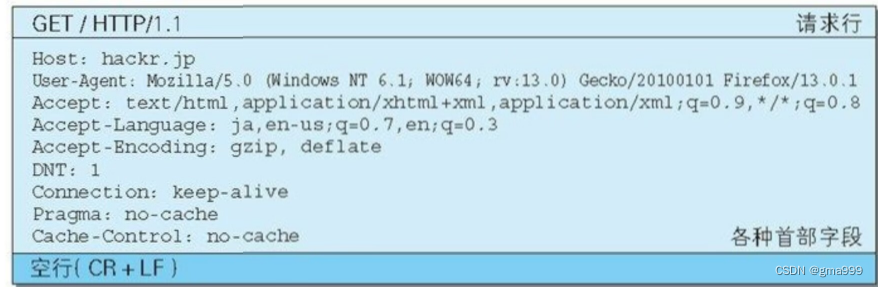
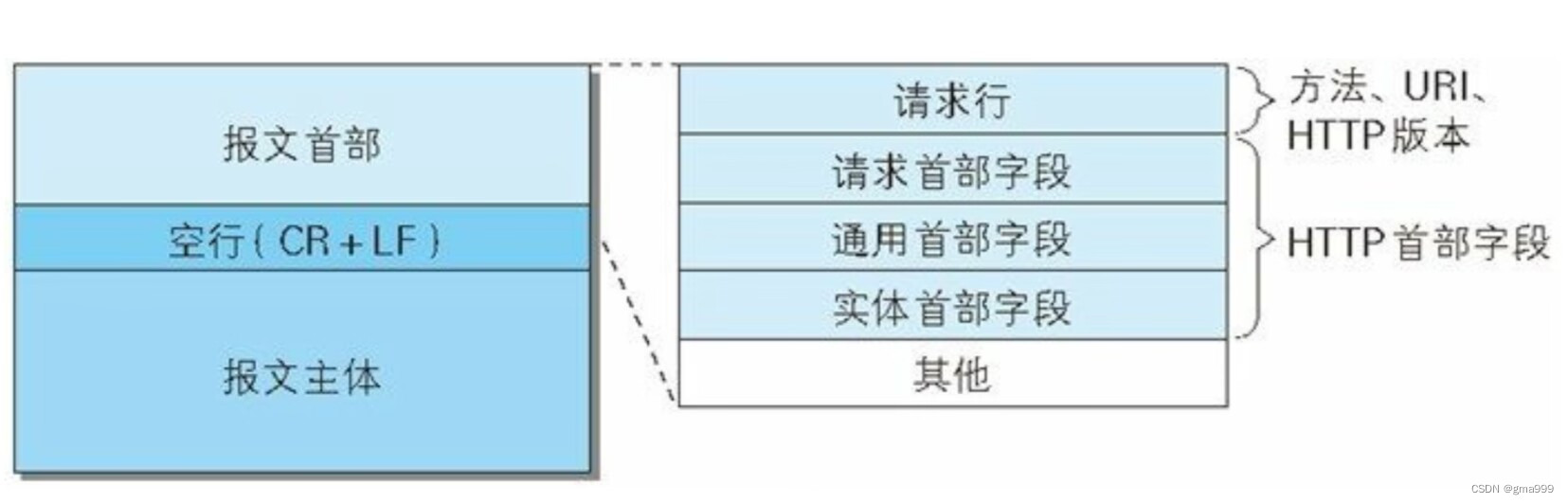
请求的两种类型
GET请求方法:获取服务器的静态网页或者其他服务器资源,上传数据的时候需要在URI中?后添加对应参数。
POST请求方法:通过正文内容向服务器传入对应的数据。报头中Content-Length标记正文的大小。
请求成员设计
- Request_line:请求行
- Request_header:请求报头,vector分行存储
- Blank:空行
- Request_body:请求正文,只有POST方法才需要读取该内容信息
- Method:请求方法,GET还是POST方法请求
- URI:请求资源地址
- Version: http协议版本
- Http_header_kv:存储请求报头,哈希表结构。
- Conten_length:POST方法下,记录请求正文的长度
- URI_path:从URI中分离出path到该变量中
- Uri_query:POS T方法不需要初始化,GET方法需要分析是否带参再决定是否初始化。
- CGI:cgi程序启动标识,如果上传数据含有参数或者调用文件中的可执行程序时,标记cgi调用cgi程序运行。
class HttpRequest
{
public:
std::string request_line;//请求行
std::vector<std::string> request_header;
std::string blank;
std::string request_body;
//解析后的结果(方法、URL、版本)
std::string method;
std::string url;
std::string version;
//解析后结果放入kv中
std::unordered_map<std::string , std::string> header_kv;
int content_length;
std::string suffix;//后缀
std::string path;//访问的资源路径
std::string query_string;
bool cgi;//cgi标志位
int size;
public:
HttpRequest():content_length(0),cgi(false){}
~HttpRequest(){}
};协议响应

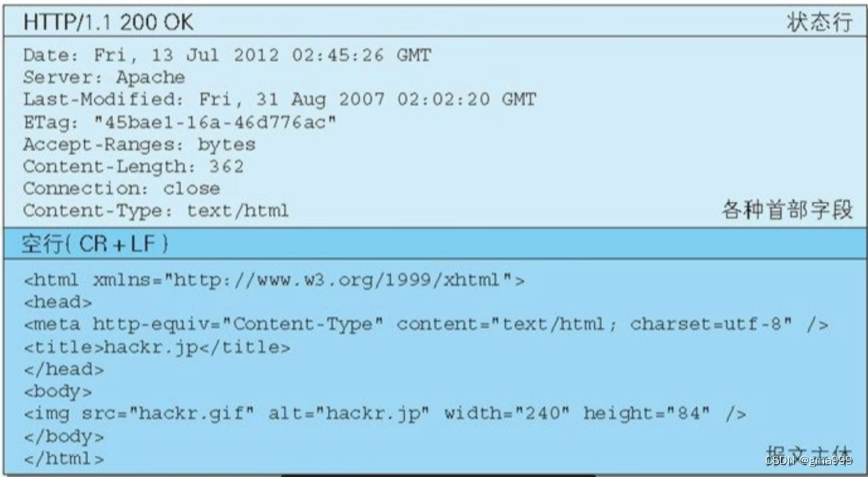
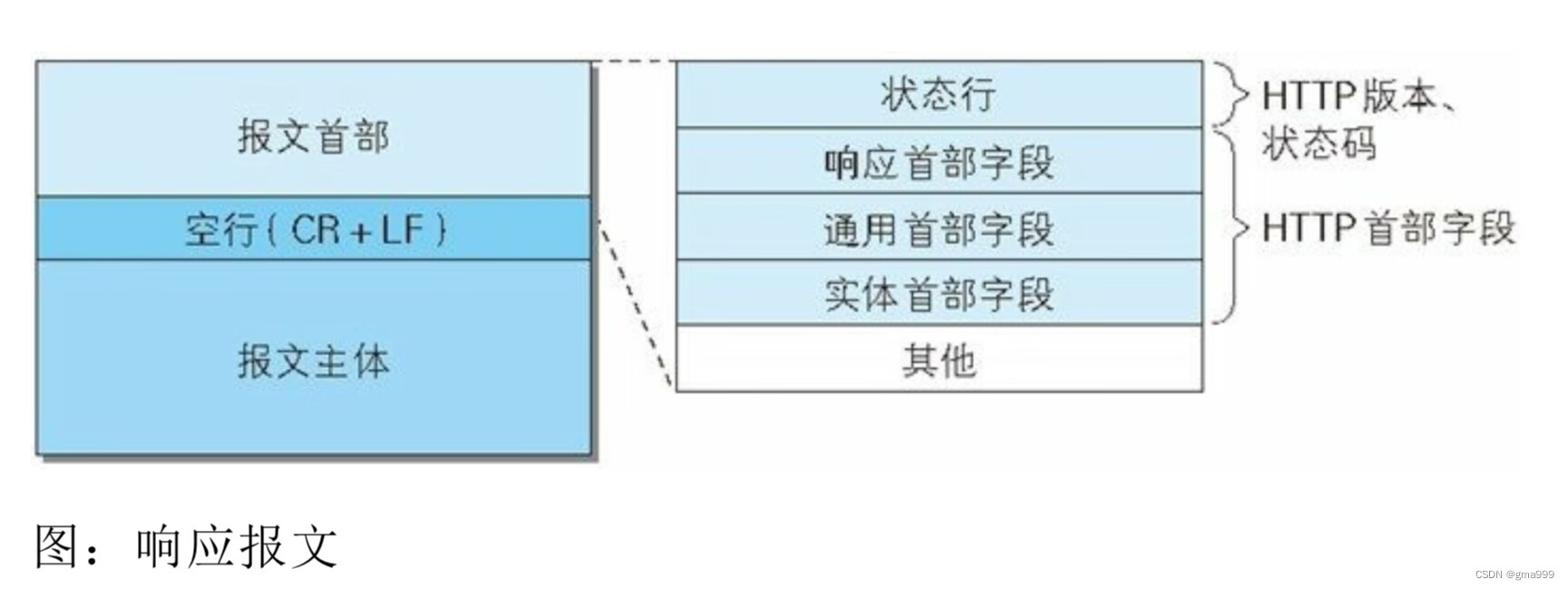
协议响应成员设计
- Status_line:状态行
- Response_header:响应报头
- Blank:空行
- Response_body:响应正文
- Status_code:状态码
- FD:返回资源的文件描述符
- Body_size:资源的大小
- Suffix:文件后缀分析
class HttpResponse
{
public:
std::string status_line;
std::vector<std::string>response_header;
std::string blank;
std::string response_body;
int status_code;//状态码
int fd;
// int size;//正文资源的大小-万恶!
public:
HttpResponse():blank(LINE_END),status_code(OK),fd(-1){}
~HttpResponse(){}
};单例模式设计分析
单例模式指内存中只会创建一次对象,减少对应被频繁创建从而导致内存泄漏。本项目使用饿汉式创建单例对象方法,首先调用线程池,判断线程池是否实例化,如果没有实例化,则调用线程池的实例化,然后返回实例化对象,如果已经实例化,则直接返回实例化对象即可。
如果仅仅参照上述方法设计单例模式则会导致线程安全问题,因为两个线程可能同时访问该单例模式,如果此时两个线程都判断线程池需要实例化,那么同时就返回了两个实例化对象。本项目中的解决该方法的方式则是加锁,如果一个线程判断线程池对象为空,则先对临界区代码加锁,创建并完成线程池初始化。
如果每一次获取对象都要加锁,那么会导致线程的并发性差,最终也会影响性能,所以为了进一步的优化性能,在加锁之前先判断线程池对象是否为空,如果存在则直接返回线程池即可。如果线程池不存在,此时才需要加锁,创建并初始化线程池。从而解决并发安全和性能低效问题。
本项目中为满足单例的创建条件,自然需要将构建和拷贝函数私有化,方式类对象的多次构造和拷贝,从而保证满足单例的设计准则。
private:
int num;
bool stop;
std::queue<Task> task_queue;
pthread_mutex_t lock;
pthread_cond_t cond;
ThreadPoll(int _num = NUM):num(_num),stop(false)
{
pthread_mutex_init(&lock,nullptr);
pthread_cond_init(&cond,nullptr);
}
ThreadPoll(const ThreadPoll&){}
static ThreadPoll*single_instance;
public:
//线程池单例设计
static ThreadPoll*getinstance()
{
static pthread_mutex_t _mutex = PTHREAD_MUTEX_INITIALIZER;
if(single_instance == nullptr)
{
pthread_mutex_lock(&_mutex);
if(single_instance == nullptr)
{
//类内创建线程池并完成初始化
single_instance = new ThreadPoll();
single_instance->InitThreadPoll();
}
pthread_mutex_unlock(&_mutex);
}
return single_instance;
}RAII
RAII(Resource Acquisition Is Initialization)是由c++之父Bjarne Stroustrup提出的,中文翻译为资源获取即初始化,他说:使用局部对象来管理资源的技术称为资源获取即初始化;这里的资源主要是指操作系统中有限的东西如内存、网络套接字等等,局部对象是指存储在栈的对象,它的生命周期是由操作系统来管理的,无需人工介入;
为了避免程序员申请对象后忘记销毁,导致内存泄漏,最后导致系统变慢。实现RAII机制,也就是对自己需要申请资源封装进一个类中,然资源自动初始化和析构。首先需要设计一个类封装资源,然后设计构造函数在初始化列表中对其进行初始化,然后使用析构函数将其申请的资源进行销毁,最后在使用的时候只要声明一个该对象的类即可。
本项目中的编写始终遵循RAII的设计原则,例如HttpRequest类、HttpResonse类、TcpServer、线程池等,项目中只要涉及内存获取,都将其进行了封装。















 11万+
11万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









