







Elasticsearch的关键就是倒排索引,而倒排索引依赖于对文档内容的分词,而分词则需要高效、精准的分词算法,IK分词器就是这样一个中文分词算法。
安装IK分词器
方案一:在线安装
运行一个命令即可:
docker exec -it es ./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip然后重启es容器:
docker restart es方案二:离线安装
如果网速较差,也可以选择离线安装。
首先,查看之前安装的Elasticsearch容器的plugins数据卷目录:
docker volume inspect es-plugins结果如下:
[
{
"CreatedAt": "2024-11-06T10:06:34+08:00",
"Driver": "local",
"Labels": null,
"Mountpoint": "/var/lib/docker/volumes/es-plugins/_data",
"Name": "es-plugins",
"Options": null,
"Scope": "local"
}
]可以看到elasticsearch的插件挂载到了/var/lib/docker/volumes/es-plugins/_data这个目录。我们需要把IK分词器上传至这个目录。
然后重启es
使用IK分词器
IK分词器包含两种模式:
- ik_smart:智能语义切分
- ik_max_word:最细粒度切分
我们在Kibana的DevTools上来测试分词器,首先测试Elasticsearch官方提供的标准分词器:
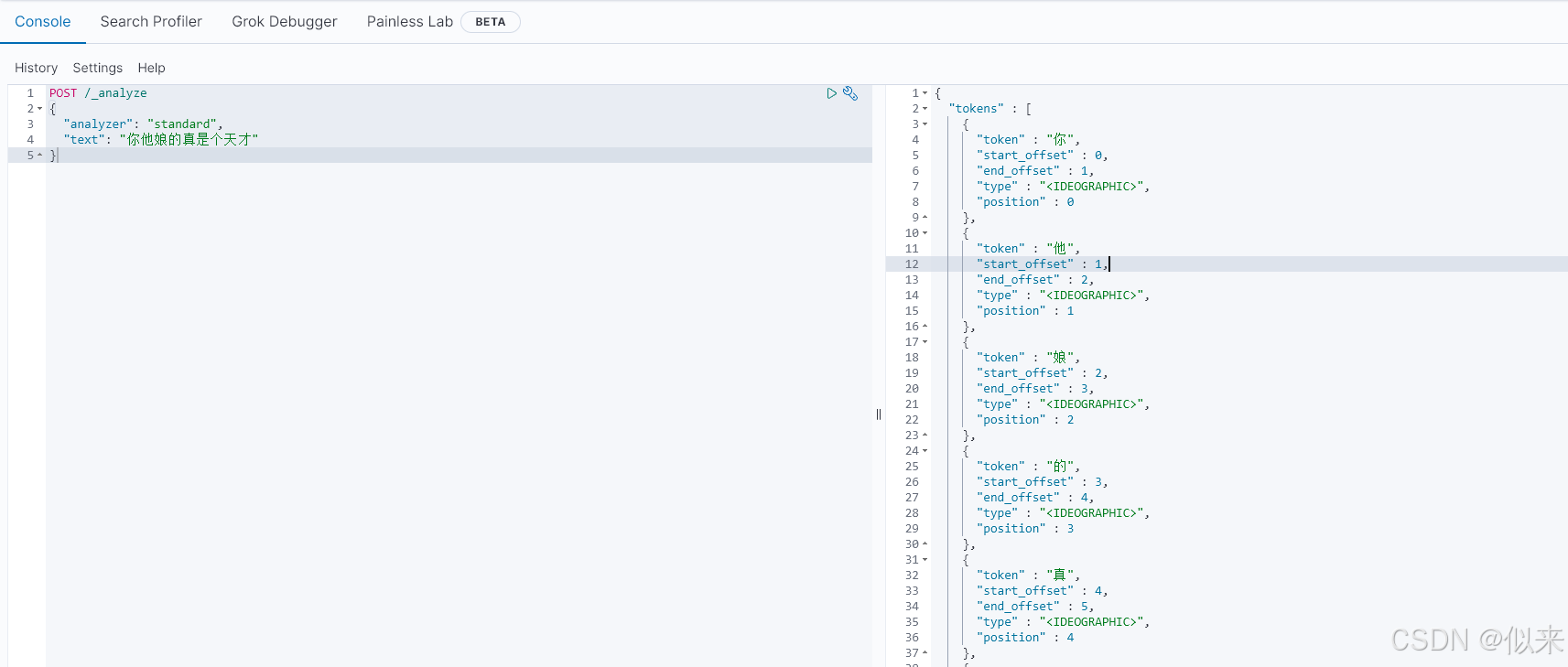
POST /_analyze
{
"analyzer": "standard",
"text": "你他娘的真是个天才"
}
{
"tokens" : [
{
"token" : "你",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<IDEOGRAPHIC>",
"position" : 0
},
{
"token" : "他",
"start_offset" : 1,
"end_offset" : 2,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "娘",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "的",
"start_offset" : 3,
"end_offset" : 4,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "真",
"start_offset" : 4,
"end_offset" : 5,
"type" : "<IDEOGRAPHIC>",
"position" : 4
},
{
"token" : "是",
"start_offset" : 5,
"end_offset" : 6,
"type" : "<IDEOGRAPHIC>",
"position" : 5
},
{
"token" : "个",
"start_offset" : 6,
"end_offset" : 7,
"type" : "<IDEOGRAPHIC>",
"position" : 6
},
{
"token" : "天",
"start_offset" : 7,
"end_offset" : 8,
"type" : "<IDEOGRAPHIC>",
"position" : 7
},
{
"token" : "才",
"start_offset" : 8,
"end_offset" : 9,
"type" : "<IDEOGRAPHIC>",
"position" : 8
}
]
}可以看到原本的分词器对中文分词是不太友好的
我们使用Ikun分词器看看
POST /_analyze
{
"analyzer": "ik_smart",
"text": "你他娘的真是个天才"
}执行结果如下:

可以看到明显的差别,更符合我们国内自己人的使用
拓展词典
随着互联网的发展,“造词运动”也越发的频繁。出现了很多新的词语,在原有的词汇列表中并不存在。比如:“Ikun”,“鸡你太美” 等。
IK分词器无法对这些词汇分词,测试一下:
POST /_analyze
{
"analyzer": "ik_max_word",
"text": "中分头背带裤,我是Ikun你记住,鸡你太美"
}
可以看到我们后面暗藏玄坤的词语并没有被分到一起。
所以要想正确分词,IK分词器的词库也需要不断的更新,IK分词器提供了扩展词汇的功能。
1)打开IK分词器config目录:
注意,如果采用在线安装的通过,默认是没有config目录的
2)在IKAnalyzer.cfg.xml配置文件内容添加:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 *** 添加扩展词典-->
<entry key="ext_dict">ext.dic</entry>
</properties>3)在IK分词器的config目录新建一个 ext.dic,可以参考config目录下复制一个配置文件进行修改
Ikun
鸡你太美4)重启elasticsearch
docker restart es
# 查看 日志
docker logs -f elasticsearch再次测试,可以发现Ikun和鸡你太美都正确分词了:

总结
分词器的作用是什么?
- 创建倒排索引时,对文档分词
- 用户搜索时,对输入的内容分词
IK分词器有几种模式?
- ik_smart:智能切分,粗粒度
- ik_max_word:最细切分,细粒度
IK分词器如何拓展词条?如何停用词条?
- 利用config目录的IkAnalyzer.cfg.xml文件添加拓展词典和停用词典
- 在词典中添加拓展词条或者停用词条

















 2454
2454

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









