









使用嵌入(Embedding)来处理稀疏ID类特征在机器学习中非常常见,尤其是在推荐系统、自然语言处理和广告点击预测等领域。嵌入技术可以将稀疏、高维的ID类特征映射到低维的稠密向量空间中,便于模型学习。下面是对其底层原理和实现的详细解释。
一、嵌入的背景和动机
在实际场景中,很多特征是离散的类别特征(如用户ID、产品ID、地点ID等),这些特征可能具有非常大的类别数量,形成了稀疏、高维的特征。例如:
- 用户ID可能有上百万种不同的取值;
- 产品ID可能有成千上万种不同的取值。
如果直接使用One-Hot编码来表示这些特征,将会导致非常高维的稀疏向量,并且计算资源消耗巨大,不利于模型的训练和预测。嵌入技术通过学习一个映射关系,将每个ID映射到一个低维的稠密向量,从而解决了这个问题。
二、嵌入的基本原理
基本概念解释
1. 稀疏 ID 类特征
稀疏 ID 类特征通常具有以下特点:
- 高维稀疏:这些特征的维度非常高,但在每个样本中仅有少数维度为 1,大部分维度为 0。比如,一个电商数据集中的“用户 ID”特征可能会有数百万种不同取值,但每个样本对应的“用户 ID”只会激活其中一个维度。
- 离散性:这些特征的取值是离散的,通常没有数值上的连续性或顺序。例如,用户 ID 和商品 ID 不具有数值大小的意义。
- 稀疏矩阵:当将这些特征表示成矩阵时,结果是一个高维且大多数元素为零的稀疏矩阵,直接输入到模型中会导致效率低下。
2. Embedding 的基本概念
Embedding 是一种将稀疏、高维的离散特征转化为低维、密集连续向量的技术。Embedding 的目标是将每个离散特征值映射到一个固定长度的实数向量中,以便模型能更好地理解和利用这些特征。
常见的 Embedding 技术包括:
- Embedding 层:在深度学习中,Embedding 层通常用于学习这些稀疏 ID 类特征的表示。例如,在神经网络模型中,ID 特征会被映射为一个低维向量,然后在网络中进一步处理。
- 矩阵查找表:Embedding 可以表示为一个查找表(通常是一个矩阵),其中每个离散特征对应一个向量。这种查找表在模型训练过程中通过反向传播来更新。
3. Embedding 如何处理稀疏 ID 类特征
Embedding 的过程主要分为以下几步:
-
初始化 Embedding 矩阵:设每种离散特征的所有可能取值共有 N 个,每个特征值被映射到 d 维空间中,初始化一个 N×d 的矩阵,每行代表一个离散特征的低维向量。
-
查找和映射:在模型训练或推理时,对于每个样本中的稀疏特征(如某个特定的用户 ID),查找该特征在矩阵中的对应行,将其低维向量作为该特征的 Embedding 表示。
-
更新 Embedding:在模型训练过程中,这些 Embedding 向量会随着目标损失函数的优化而更新,逐渐学习到能更好反映特征间相似性的低维表示。
4. Embedding 和稀疏 ID 类特征的关系
Embedding 和稀疏 ID 类特征的关系可以概括为以下几点:
- 稀疏特征变密集特征:Embedding 是将高维稀疏的 ID 特征转化为低维密集表示的过程,使得模型可以高效地处理这些特征。
- 降维:Embedding 将每个高维 ID 特征映射到一个低维空间中,减少了特征维度,降低了计算成本。
- 学习特征表示:Embedding 通过模型的训练过程不断优化,使得映射后的低维向量可以更好地捕捉特征之间的语义相似性。这对于提高模型的表现非常重要。例如,相似的用户 ID 在低维向量空间中可能会更接近。
- 适用于深度学习:Embedding 层常用于深度学习模型中,将离散特征嵌入到网络中,以便与其他特征一起处理。
嵌入层(Embedding Layer)在数学上是一个查找表。假设有一个稀疏ID类特征,该特征包含 N 个可能的类别(即ID总数为 N),希望将这些类别映射到 d 维的稠密向量空间中。通过嵌入,得到一个 N×d 的矩阵 E,其中每一行表示一个ID在 d 维空间中的稠密向量表示。
具体操作可以表述如下:
-
嵌入矩阵的定义:
假设 E 是一个形状为 N×d 的矩阵。E 的第 i 行表示ID为 i 的类别对应的嵌入向量。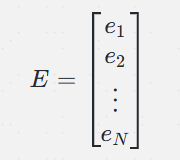
其中表示第 i 个ID的嵌入向量,形状为 1×d。
-
查找操作:
对于给定的类别ID,可以直接在嵌入矩阵 E 中查找第 i 行来得到对应的嵌入向量。
-
嵌入矩阵的学习:
嵌入矩阵 E 的每一行向量(即每个ID的嵌入向量)都是在模型训练过程中更新和学习的。在梯度下降优化过程中,嵌入矩阵的行向量作为参数被更新,从而使得不同类别的嵌入向量能够有效地表示它们在目标任务中的作用。
三、嵌入层的实现
在深度学习框架中,嵌入层通常由一个可学习的参数矩阵实现,并结合前向传播和后向传播进行训练。以Python中的PyTorch框架为例,以下代码展示了一个简单的嵌入层实现。
import torch
import torch.nn as nn
# 定义嵌入层
embedding_layer = nn.Embedding(num_embeddings=N, embedding_dim=d)
# 示例:随机选择一个ID,然后查看其嵌入向量
example_id = torch.tensor([42]) # 假设ID为42
embedding_vector = embedding_layer(example_id)
print("ID 42 的嵌入向量:", embedding_vector)
在上面的代码中:
num_embeddings是类别数量(ID的总数)。embedding_dim是嵌入向量的维度。
四、训练过程中的嵌入更新
嵌入矩阵 E 的行向量作为模型参数,使用反向传播和优化算法进行更新。对于给定的训练样本,模型计算损失,然后计算该损失对嵌入矩阵中相关行向量的梯度,并更新这些向量。
假设损失函数为 L,给定输入样本中有ID为 i 的类别,其对应的嵌入向量为 。在反向传播过程中,会计算 L 对
的梯度
,然后使用优化算法(如SGD)来更新
:
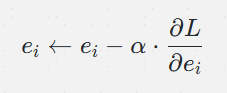
其中 α 为学习率。这个更新过程会随着训练逐步优化嵌入向量,使得它们在目标任务上表现良好。
五、嵌入的实现流程总结
- 初始化嵌入矩阵:随机初始化一个 N×d 的矩阵,每行对应一个类别ID的嵌入向量。
- 前向传播查找嵌入:对于输入样本中的ID,直接在嵌入矩阵中查找相应行向量,得到低维稠密向量表示。
- 反向传播更新嵌入:计算损失函数的梯度,并对嵌入矩阵中参与计算的行向量进行梯度更新。
- 重复训练:嵌入矩阵会逐渐学习到各个ID的合理向量表示,使得模型能够更好地利用稀疏ID类特征。
六、嵌入的应用
嵌入在很多实际场景中都非常有用,特别是在处理具有稀疏ID类特征的任务中,比如:
- 推荐系统:对用户和物品的ID进行嵌入,将其映射到相同的向量空间中,用于计算用户和物品之间的相似度。
- 自然语言处理:词嵌入(Word Embedding)是 NLP 领域中最常用的 Embedding 技术,将词汇表中的每个单词表示为嵌入向量,以捕捉单词之间的语义关系。
- 广告点击率预测:将用户特征(例如兴趣、历史行为)和广告特征(例如广告ID、类别)进行嵌入,形成低维表示,便于模型理解。
七、嵌入在生产环境中的考虑
在生产环境中使用嵌入时,还需要考虑以下几个因素:
-
嵌入矩阵的存储:ID类特征可能非常多,嵌入矩阵可能很大。可以考虑使用分布式存储或稀疏矩阵存储。
-
在线更新:在一些实时系统中,嵌入可能需要随时间动态更新,这时可以采用增量训练的方法来保持嵌入向量的时效性。
-
冷启动问题:对于从未见过的ID,系统需要进行特别处理,例如采用平均嵌入向量或者随机初始化等策略。
八、总结
使用嵌入处理稀疏ID类特征的核心在于将高维稀疏向量转换为低维稠密向量,方便模型处理并且提高训练效率。实现这一过程的关键是:
- 使用可学习的嵌入矩阵作为查找表;
- 利用前向传播和反向传播对嵌入进行优化;
- 在生产环境中合理处理存储和在线更新等问题。
通过嵌入层,将原本高维、稀疏的特征转换为低维、稠密的向量,使得机器学习模型能够高效地处理这些信息并挖掘出有用的模式。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









