






❤️点击上方,选择星标或置顶,每天给你送上干货❤️
作者 | godweiyang
出品 | 公众号:算法码上来(ID:GodNLP)
- BEGIN -
上周突然发现公众号后台很多人私信我,我感到很奇怪。打开一看,把我震惊到了,一篇3年前写的文章,当时才200多阅读量吧,现在竟然6.8万了。。。而我的粉丝也才一万啊。

文章链接在这里,是关于如何用小米手机导出微信聊天记录并进行分析的:
看了一下数据趋势,大概是11.4这天开始慢慢涨起来的,前两天终于降下去了。估计是平台推荐到了吧,虽然我也不知道为啥会推荐一篇三年前的老文章。。。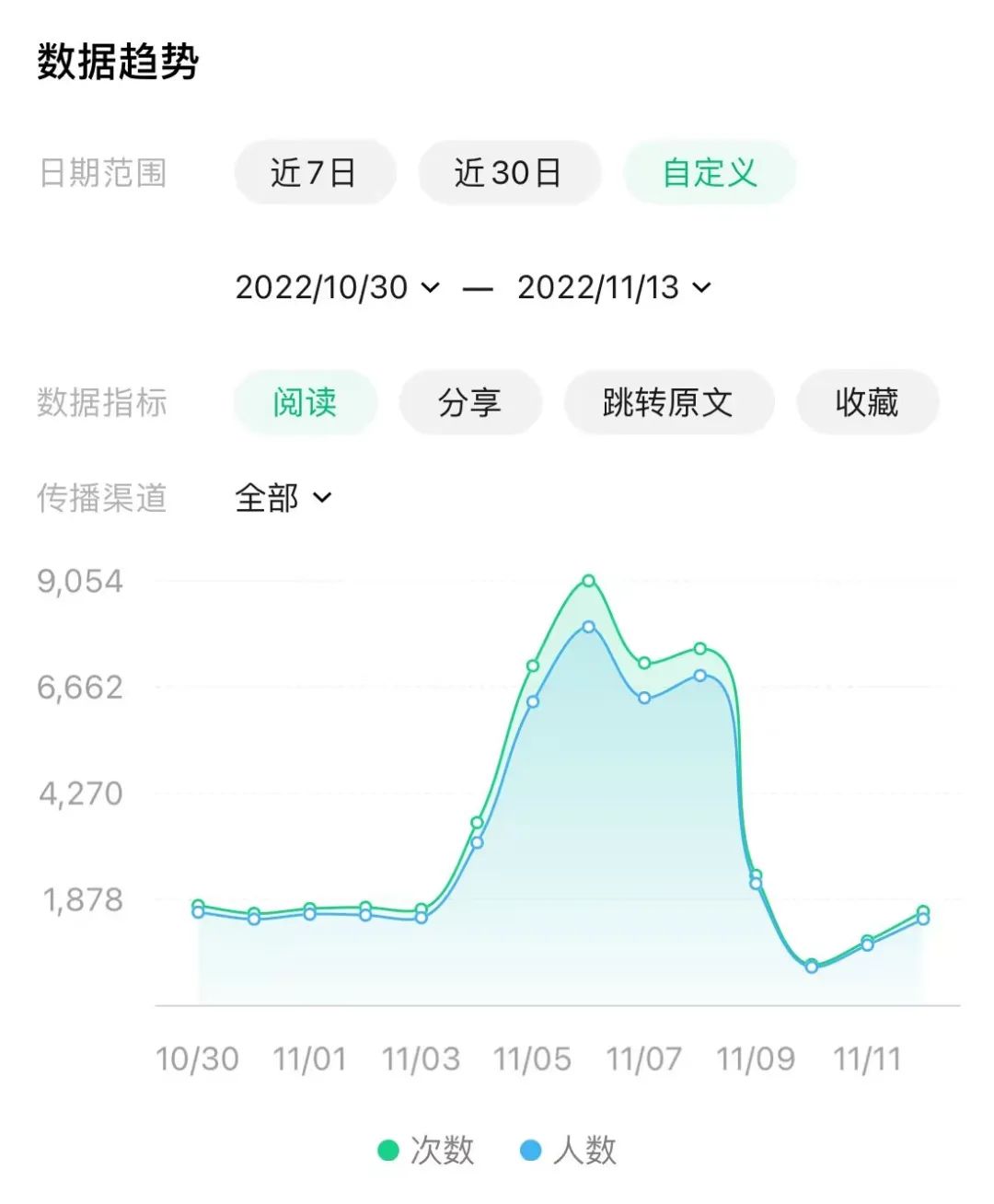
去年这个时候还写过另一篇更简单的方法,用mac电脑导出,我现在主要用这个方法导出:
下面就分析一下2022年我的微信聊天情况,只看了私聊,不看群聊。
和谁聊天最多?
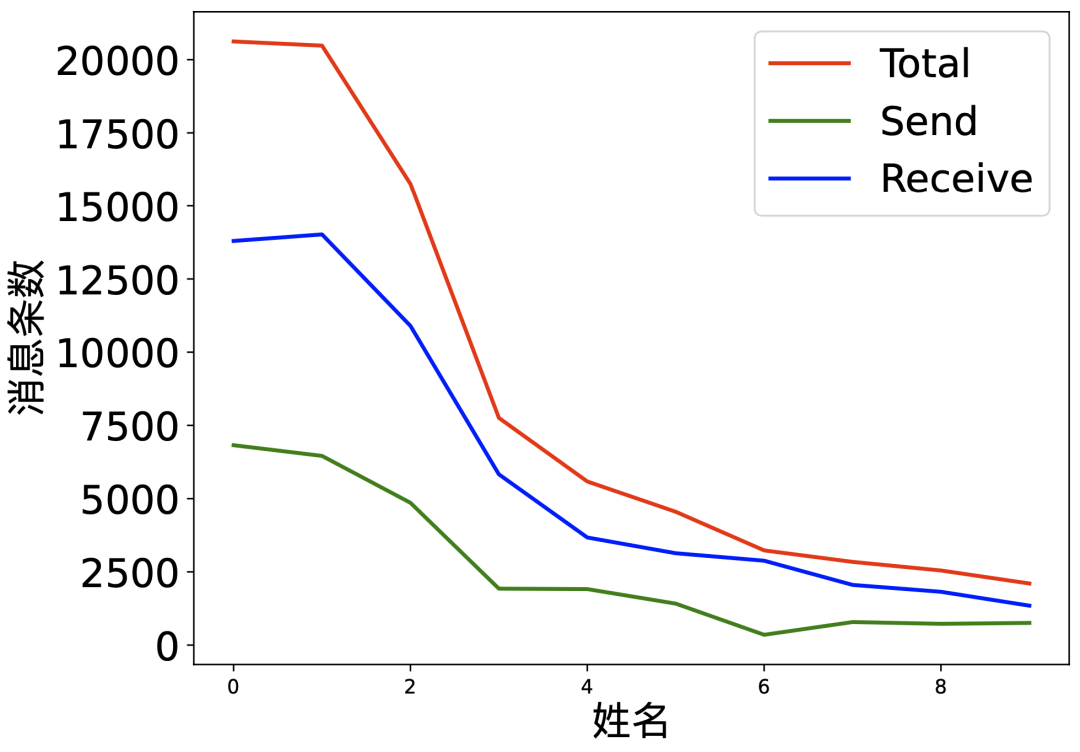 这里统计了互发消息条数前十名的好友,出于隐私就不放名字了。
这里统计了互发消息条数前十名的好友,出于隐私就不放名字了。
可以看出几点信息:
常聊天的好友主要有3位,再后面的就出现断崖式下降了。
今年我回复的消息远远不及接收的消息多,对比前两年,我是回复大于接收的。(难道说今年我变高冷了?)
相比前两年,前三名是新面孔,很多之前的老面孔都退出了前10名,工作了之后确实聊的少了。
好友6的回复条数尤其少,大概接收10条才回复1条,在我粉丝群的老粉应该都能猜出这是谁。
一年中聊天数量趋势
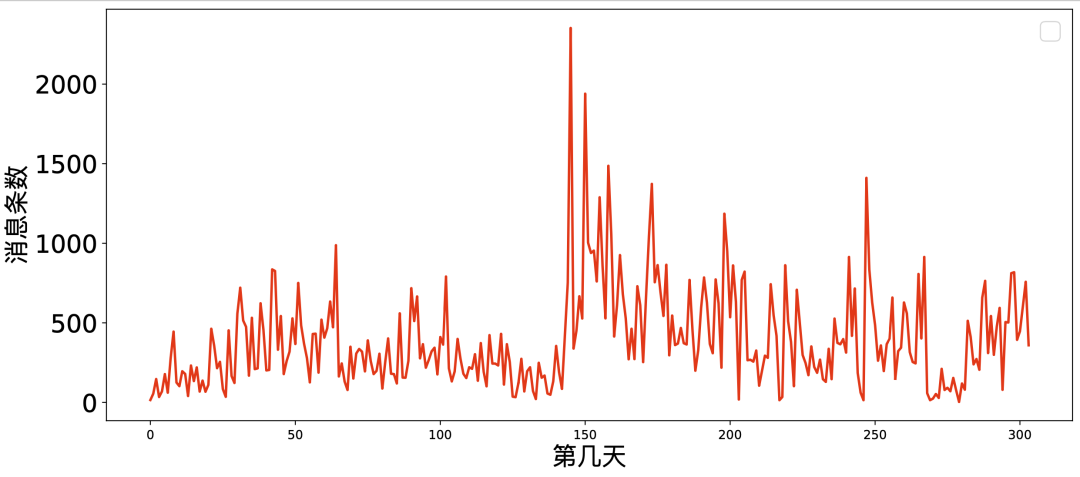 从2022.1.1开始统计到2022.11.11为止,我画出了每一天私聊互发消息条数的趋势图。
从2022.1.1开始统计到2022.11.11为止,我画出了每一天私聊互发消息条数的趋势图。
这张图有很大的信息量:
年初到过年期间(0-60天)越聊越多,可能过年在家无聊吧。
上海封城期间(60-140天)越聊越少,封城后期天天打游戏,都快自闭了吧可能。
5月底(140天)开始,消息量急速上升,因为遇见了一个改变了我许多的人。
678三个月(140-230天),消息量急速下降直到正常,毕竟不可能一直维持刚开始的热情的,那不得累死。
9月份(230-270天),消息量又上升了一点,可能是因为要回了吧。
10月份(270-300天),消息量降到全年最低,因为不需要网聊了吧。
再往后又上升至正常,因为又回到上半年的状态了吧。
这里不深入分析了,等一个月后的年终总结吧。不管怎么样,感谢吧。
一天中几点聊的最多?
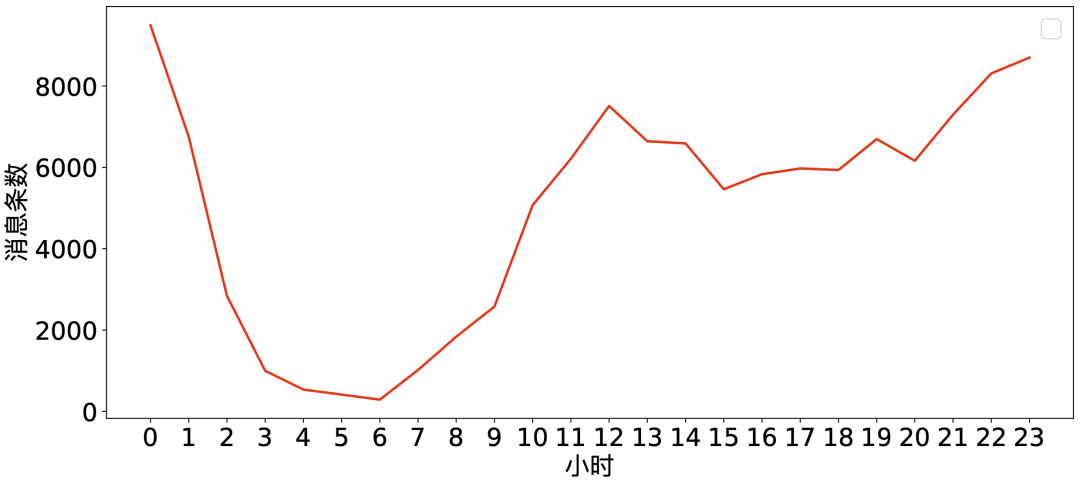 这个趋势和前两年是一样的,我仍然是一个夜猫子。夜越深,聊的越嗨,半夜12点是我聊的最嗨的时候。而中午和下午是聊的最少的时候,因为要上班。
这个趋势和前两年是一样的,我仍然是一个夜猫子。夜越深,聊的越嗨,半夜12点是我聊的最嗨的时候。而中午和下午是聊的最少的时候,因为要上班。
我最喜欢发什么词?
 可以看出发的最多的词是:肯定、确实、哦哦哦、喜欢、感觉。
可以看出发的最多的词是:肯定、确实、哦哦哦、喜欢、感觉。
实现方法
首先你得有一个mac电脑,然后用下面方法导出聊天记录,并且都存放在jsons目录下:
然后用下面的代码导出你所有的私聊记录,保存到output.txt文件中。
import json
import os
files = os.listdir("jsons")
fout = open("output.txt", "w")
for f in files:
with open(f"jsons/{f}", "r") as fin:
print(f)
results = json.load(fin)
is_group = 1
for dic in results:
if (
dic["messageType"] == 1
and dic["msgCreateTime"] >= 1640966434
and dic["msgStatus"] != 2
and dic["mesDes"] == 1
and ":" not in dic["msgContent"]
):
is_group = 0
break
if not is_group:
for dic in results:
if (
dic["messageType"] == 1
and ":" not in dic["msgContent"]
and dic["msgCreateTime"] >= 1640966434
and dic["msgStatus"] != 2
):
content = "".join(dic["msgContent"].strip().split())
if dic["mesDes"] == 1:
fout.write(
"{} 1 {} {}\n".format(f, str(dic["msgCreateTime"]), content)
)
else:
fout.write(
"{} 0 {} {}\n".format(f, str(dic["msgCreateTime"]), content)
)
fout.close()最后用下面代码分析本文中提到的几点要素,注意改一下中文字体路径。最后还会生成me.txt,可以用来生成词云,生成方法参考之前的文章。
python生成词云教程(附带QQ聊天记录生成词云实战)
import datetime
from collections import defaultdict
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
import matplotlib.font_manager
def getChineseFont():
# 去你电脑的字体库找一个中文字体,把文件路径粘贴过来
return FontProperties(fname="/System/Library/Fonts/PingFang.ttc", size=20)
matplotlib.rcParams["pdf.fonttype"] = 42
matplotlib.rcParams["ps.fonttype"] = 42
# 2022.1.1 00:00
start = 1640966434
def process_time(end):
t = datetime.datetime(2022, 1, 1, 0, 0, 0) + datetime.timedelta(seconds=end - start)
return (t.month, t.day, t.hour, t.minute, t.second)
"""跟谁聊的最多
姓名 总共 发送 接收
"""
name_count = defaultdict(int)
send_count = defaultdict(int)
rece_count = defaultdict(int)
with open("output.txt", "r") as fin:
for line in fin:
name = line.strip().split(" ")[0]
des = int(line.strip().split(" ")[1])
name_count[name] += 1
if des == 0:
send_count[name] += 1
else:
rece_count[name] += 1
nc = sorted(name_count.items(), key=lambda x: x[1], reverse=True)
for k in nc[:10]:
print(k[0], k[1], send_count[k[0]], rece_count[k[0]])
c1 = [x[1] for x in nc[:10]]
c2 = [send_count[x[0]] for x in nc[:10]]
c3 = [rece_count[x[0]] for x in nc[:10]]
r = np.arange(len(c1))
plt.figure(figsize=(8, 6))
plt.plot(r, c1, color="red", label="Total", linewidth=2.0)
plt.plot(r, c2, color="green", label="Send", linewidth=2.0)
plt.plot(r, c3, color="blue", label="Receive", linewidth=2.0)
plt.yticks(fontsize=20)
plt.xlabel("姓名", fontproperties=getChineseFont(), fontsize=20)
plt.ylabel("消息条数", fontproperties=getChineseFont(), fontsize=20)
plt.legend(fontsize=20)
plt.savefig("./name_count.pdf", bbox_inches="tight")
plt.show()
"""哪个月份聊的最多
月份 数量
"""
month_count = defaultdict(int)
with open("output.txt", "r") as fin:
for line in fin:
time = int(line.strip().split(" ")[2])
t = process_time(time)
month_count[t[0]] += 1
mc = sorted(month_count.items(), key=lambda x: x[1], reverse=True)
for k in mc:
print(k[0], k[1])
mc = sorted(month_count.items(), key=lambda x: x[0], reverse=False)
x_ticks = [x[0] for x in mc]
c = [x[1] for x in mc]
r = np.arange(len(c))
plt.figure(figsize=(8, 6))
plt.plot(r, c, color="red", linewidth=2.0)
plt.xticks([r for r in range(len(c))], x_ticks, fontsize=20)
plt.yticks(fontsize=20)
plt.xlabel("月份", fontproperties=getChineseFont(), fontsize=20)
plt.ylabel("消息条数", fontproperties=getChineseFont(), fontsize=20)
plt.legend(fontsize=20)
plt.savefig("./month_count.pdf", bbox_inches="tight")
plt.show()
"""哪个时间点聊的最多
几点 数量
"""
hour_count = defaultdict(int)
with open("output.txt", "r") as fin:
for line in fin:
time = int(line.strip().split(" ")[2])
t = process_time(time)
hour_count[t[2]] += 1
hc = sorted(hour_count.items(), key=lambda x: x[1], reverse=True)
for k in hc:
print(k[0], k[1])
hc = sorted(hour_count.items(), key=lambda x: x[0], reverse=False)
x_ticks = [x[0] for x in hc]
c = [x[1] for x in hc]
r = np.arange(len(c))
plt.figure(figsize=(14, 6))
plt.plot(r, c, color="red", linewidth=2.0)
plt.xticks([r for r in range(len(c))], x_ticks, fontsize=20)
plt.yticks(fontsize=20)
plt.xlabel("小时", fontproperties=getChineseFont(), fontsize=20)
plt.ylabel("消息条数", fontproperties=getChineseFont(), fontsize=20)
plt.legend(fontsize=20)
plt.savefig("./hour_count.pdf", bbox_inches="tight")
plt.show()
"""哪一天聊的最多
"""
day_count = defaultdict(int)
with open("output.txt", "r") as fin:
for line in fin:
time = int(line.strip().split(" ")[2])
t = process_time(time)
day_count[t[0] * 31 + t[1]] += 1
dc = sorted(day_count.items(), key=lambda x: x[0], reverse=False)
c = [x[1] for x in dc]
r = np.arange(len(c))
plt.figure(figsize=(14, 6))
plt.plot(r, c, color="red", linewidth=2.0)
plt.yticks(fontsize=20)
plt.xlabel("第几天", fontproperties=getChineseFont(), fontsize=20)
plt.ylabel("消息条数", fontproperties=getChineseFont(), fontsize=20)
plt.legend(fontsize=20)
plt.savefig("./day_count.pdf", bbox_inches="tight")
plt.show()
"""我最喜欢发什么词?
"""
with open("output.txt", "r", encoding="utf-8") as fin, open("me.txt", "w", encoding="utf-8") as fout:
for line in fin:
des = int(line.strip().split(" ")[1])
if des == 0:
content = line.strip().split(" ")[3]
fout.write(content + "\n")- END -
我是godweiyang,字节跳动AI Lab NLP算法工程师,华师计算机本硕均专业第一,擅长算法、模型优化和机器翻译。
回复【算法】
获取我面试时写过的100多道算法题解,刷完进大厂没问题。
回复【CUDA】
获取我为新手准备的CUDA入门系列教程。
回复【内推】
内推字节,通过率高,加我微信可随时查催进度、咨询问题。
回复【加群】
进我的技术交流(聊天)群和内推群,群内有字节HR答疑。

求求兄弟们点个在看吧,今天的阅读量靠你们了👇
















 330
330











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











