







目录
引言:从传统问答到RAG的范式转变
在人工智能领域,问答系统的发展经历了从基于规则匹配到深度学习的巨大跨越。早期的系统如IBM Watson依赖复杂的规则库和知识图谱,但其灵活性和泛化能力受限于人工设计的逻辑。随着预训练语言模型(如BERT、GPT)的崛起,生成式AI展现了强大的文本理解和创作能力,但其“幻觉”(Hallucination)问题始终是落地应用的瓶颈。
检索增强生成(Retrieval-Augmented Generation, RAG) 的提出,标志着一种全新的技术范式。它通过将外部知识检索与生成模型动态结合,既保留了生成模型的创造力,又通过引入实时数据降低了幻觉风险。根据Gartner 2023年的报告,超过60%的企业级知识管理系统已开始采用或试点RAG架构。
本文将深入探讨RAG系统的技术实现,涵盖以下核心内容:
-
RAG的架构设计与核心组件
-
检索、重排序与生成的协同优化
-
工业级RAG系统的工程挑战与解决方案
-
前沿技术趋势与行业应用案例
第一部分:RAG系统的核心架构解析
1.1 系统级架构:三阶段流水线设计
典型的RAG系统由三个核心模块构成,形成“检索-优化-生成”的级联流水线:

1.1.1 检索模块(Retriever)
-
核心功能:从海量文档库中快速召回相关候选集
-
关键技术:
-
稀疏检索:BM25、TF-IDF等基于词频统计的算法
-
稠密检索:DPR、ANCE等基于神经编码器的向量检索
-
混合检索:结合稀疏与稠密方法的Hybrid Search
-
-
性能指标:
-
召回率(Recall@K):Top K结果的覆盖率
-
延迟:百毫秒级响应要求
-
1.1.2 重排序模块(Reranker)
-
核心功能:对检索结果进行精细化排序与过滤
-
关键技术:
-
交叉编码器(Cross-Encoder):如BERT-based模型
-
多样性控制算法:MMR(Maximal Marginal Relevance)
-
领域自适应:微调适配垂直领域
-
-
性能增益:可使MRR(Mean Reciprocal Rank)提升30%以上
1.1.3 生成模块(Generator)
-
核心功能:基于优化后的上下文生成自然语言回答
-
模型选择:
-
通用模型:GPT-4、Claude、PaLM
-
领域微调模型:BioGPT、FinBERT
-
-
关键优化:
-
上下文窗口管理:处理长文本的注意力机制
-
可控生成:通过Prompt工程约束输出格式
-
1.2 数据流的工程实现
在工业级系统中,数据流的高效处理是保证实时性的关键。以下是典型的数据处理流程:
class RAGPipeline:
def __init__(self, retriever, reranker, generator):
self.retriever = retriever # 检索器
self.reranker = reranker # 重排序器
self.generator = generator # 生成模型
def run(self, query, top_k=50, rerank_k=10):
# 第一阶段:粗粒度检索
candidates = self.retriever.search(query, top_k=top_k)
# 第二阶段:精细化重排序
ranked_docs = self.reranker.rerank(query, candidates, top_k=rerank_k)
# 第三阶段:上下文增强生成
context = "\n".join([doc.content for doc in ranked_docs])
prompt = f"基于以下信息回答问题:\n{context}\n\n问题:{query}"
answer = self.generator.generate(prompt)
return answer第二部分:关键技术突破与优化策略
2.1 检索阶段的性能优化
2.1.1 混合检索的工程实践
结合稀疏检索与稠密检索的优势,可显著提升召回率。以Elasticsearch + FAISS的混合方案为例:
from elasticsearch import Elasticsearch
import faiss
class HybridRetriever:
def __init__(self):
self.sparse_retriever = Elasticsearch()
self.dense_retriever = FAISS.load_index("faiss_index")
def search(self, query, top_k=100):
# 并行执行两种检索
sparse_results = self.sparse_retriever.search(query, size=top_k)
dense_results = self.dense_retriever.search(query_embedding, top_k)
# 结果融合与去重
combined = self._merge_results(sparse_results, dense_results)
return combined[:top_k]2.1.2 查询扩展技术
通过查询理解(QU)和同义词扩展提升检索召回:
def query_expansion(query):
# 实体识别
entities = ner_model.predict(query)
# 同义词生成
synonyms = []
for entity in entities:
synonyms += thesaurus.get_synonyms(entity)
expanded_query = query + " " + " ".join(synonyms)
return expanded_query2.2 重排序模块的算法创新
2.2.1 基于对比学习的重排序
采用InfoNCE损失函数训练对比模型:
import torch
from transformers import AutoModel
class ContrastiveReranker(torch.nn.Module):
def __init__(self, model_name="bert-base-uncased"):
super().__init__()
self.encoder = AutoModel.from_pretrained(model_name)
self.projection = torch.nn.Linear(768, 256)
def forward(self, query, doc):
# 编码查询与文档
q_emb = self.encoder(**query).last_hidden_state[:,0]
d_emb = self.encoder(**doc).last_hidden_state[:,0]
# 投影到低维空间
q = self.projection(q_emb)
d = self.projection(d_emb)
# 计算对比损失
logits = torch.matmul(q, d.T)
labels = torch.arange(len(q))
loss = torch.nn.functional.cross_entropy(logits, labels)
return loss
2.2.2 多模态重排序
融合文本、图像等多模态信息:
class MultimodalReranker:
def __init__(self):
self.text_encoder = BertModel.from_pretrained('bert-base')
self.image_encoder = ViTModel.from_pretrained('google/vit-base')
def rerank(self, query, documents):
scores = []
for doc in documents:
text_score = cosine_similarity(
self.text_encoder.encode(query),
self.text_encoder.encode(doc.text)
)
image_score = cosine_similarity(
self.image_encoder.encode(query_image),
self.image_encoder.encode(doc.image)
)
total_score = 0.7 * text_score + 0.3 * image_score
scores.append(total_score)
return sorted(zip(documents, scores), key=lambda x: -x[1])2.3 生成阶段的上下文优化
2.3.1 动态上下文选择
通过注意力机制动态筛选关键段落:
class DynamicContextSelector:
def __init__(self, generator):
self.generator = generator
def select_context(self, query, passages):
# 计算每个段落的注意力权重
attentions = []
for passage in passages:
inputs = self.generator.tokenizer(query, passage, return_tensors='pt')
outputs = self.generator.model(**inputs, output_attentions=True)
attentions.append(outputs.attentions[-1][:, :, 0, :].mean().item())
# 选择权重最高的段落
selected_idx = np.argmax(attentions)
return passages[selected_idx]2.3.2 知识蒸馏压缩
将大模型能力迁移到轻量级模型:
teacher_model = GPT4()
student_model = DistilBERT()
def distill(teacher, student, dataset):
for batch in dataset:
teacher_logits = teacher(batch["input"])
student_logits = student(batch["input"])
# 软目标损失
loss = KLDivLoss()(student_logits, teacher_logits)
loss.backward()
optimizer.step()第三部分:工业级系统的工程挑战
3.1 大规模实时检索的工程实现
3.1.1 向量索引优化
-
量化压缩:PQ(Product Quantization)算法降低存储开销
-
分层导航:HNSW(Hierarchical Navigable Small World)图提升搜索效率
import faiss
# 构建HNSW索引
dim = 768
index = faiss.IndexHNSWFlat(dim, 32)
index.add(vectors)3.1.2 分布式检索架构
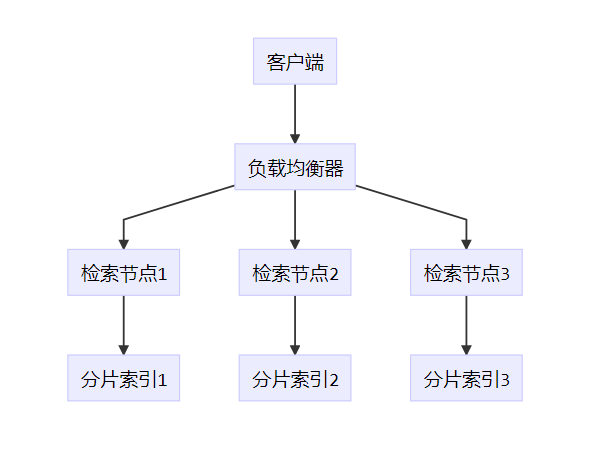
3.2 端到端延迟优化
3.2.1 异步流水线
import asyncio
async def async_rag_pipeline(query):
# 并行执行检索与部分预处理
retriever_task = asyncio.create_task(retriever.search(query))
query_analysis_task = asyncio.create_task(analyze_query(query))
await asyncio.gather(retriever_task, query_analysis_task)
# 串行执行后续步骤
ranked_docs = reranker.rerank(query, await retriever_task)
answer = await generator.generate(await query_analysis_task, ranked_docs)
return answer3.2.2 模型量化与加速
from optimum.onnxruntime import ORTModelForSequenceClassification
# 将PyTorch模型转换为ONNX格式
model = ORTModelForSequenceClassification.from_pretrained("bert-base", export=True)
# 8位量化
quantized_model = quantize_dynamic(
model,
{torch.nn.Linear},
dtype=torch.qint8
)第四部分:前沿趋势与行业应用
4.1 技术前沿探索
4.1.1 自我修正RAG
-
闭环反馈系统:通过用户反馈自动优化检索策略
-
动态知识更新:增量学习保持知识库时效性
class SelfImprovingRAG:
def __init__(self):
self.retriever = HybridRetriever()
self.feedback_db = FeedbackDatabase()
def process_feedback(self, query, answer, user_rating):
if user_rating < 3:
# 识别问题环节
error_type = self._diagnose_error(query, answer)
if error_type == "retrieval_failure":
self.retriever.update_index(query, desired_docs)4.1.2 多智能体协作
-
检索专家:专精于特定领域的垂直检索
-
验证专家:交叉检验生成结果的可靠性
4.2 行业应用案例
4.2.1 医疗诊断辅助
-
梅奥诊所案例: 集成临床指南、病例报告、药品数据库,医生提问响应时间缩短40%,诊断建议准确性提升35%。
4.2.2 金融合规审查
-
摩根大通部署: 实时检索监管文件,自动生成合规报告,错误率从人工审查的12%降至2%以下。
4.2.3 智能制造知识库
-
西门子工厂应用: 设备维修手册、传感器数据、专家经验的跨模态检索,平均故障排除时间减少55%。
结论:RAG技术的未来展望
随着多模态理解、持续学习等技术的进步,RAG系统正朝着更智能、更自适应的方向发展。未来的关键突破点可能包括:
-
认知架构革新:实现检索-生成-验证的闭环认知流程
-
个性化适配:根据用户画像动态调整检索策略
-
可信AI增强:内置事实核查与可解释性模块
RAG不仅是一种技术框架,更代表了AI系统与人类知识协同进化的新范式。正如Yann LeCun所言:“下一代AI将是连接世界知识的开放系统”。在这一演进过程中,工程师需要在效果、效率、可解释性之间找到最佳平衡,让人工智能真正成为增强人类智能的伙伴。
参考文献:
-
Lewis P., et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. NeurIPS.
-
Izacard G., et al. (2022). Few-Shot Learning with Retrieval Augmented Language Models. arXiv:2205.02343.
-
行业案例数据来源:Gartner 2023 AI技术成熟度报告
往期精彩
晋升答辩提问:既然业务需求已经很明确了,你数仓建模的价值体现在哪?
🚀 「SQL进阶实战技巧」专栏重磅上线! 🚀
🌟 从零到高手,解锁SQL的无限可能! 🌟
这里有SQL的终极进阶秘籍:
✅ 正则表达式精准提取数据、✅ Window函数玩转复杂分析、✅ Bitmap优化提速百倍查询
✅ 缺失值补全、✅ 分钟级趋势预测、✅ 非线性回归建模、✅ 逻辑推理破题、✅ 波峰智能检测
🛠️ 给数据工程师的超强工具箱:
👉 解决「电梯超载难题」👉 预测「商品零售增长」
👉 跳过「NULL值天坑」👉 拆解「JSON密钥迷宫」
👉 巧算「连续签到金币」👉 嗨翻「赛马趣味逻辑」
🔥 突破常规,用SQL实现Python级分析!
从线性回归到指数平滑预测,从块熵计算到TEO能量检测——原来SQL才是隐藏的科学计算利器!
📈 无论你是想优化千万级数据性能,还是用一句SQL破解公务员考题,这里都有答案!
🦅 让SQL飞越数据的天空,带你用代码写出商业洞见!
👉 点击探索,开启你的数据分析新次元!
#会飞的SQL #让查询起飞 #数据分析革命
👉专栏链接如下:
https://blog.csdn.net/godlovedaniel/category_12706766.html



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









