







0 问题描述
问题:如何取多个表中某一字段不为空且时间最新的值?
举个例子,多张表(其中人会有重复)中都有电话号码这个字段,我需要取每个人最新的电话号码。
表1,命名为t1
| name | contact_phone | update_time |
|---|---|---|
| 111 | 2019 | |
| 张三 | 123 | 2019 |
| 李四 | 642 | 2020 |
表2,命名为t2
| name | contact_phone | update_time |
|---|---|---|
| 王二 | 222 | 2022 |
| 张三 | NULL | 2021 |
| 李四 | 753 | 2010 |
表3,命名为t3
| name | contact_phone | update_time |
|---|---|---|
| 张三 | 789 | 2012 |
| 李四 | 864 | 2021 |
最后需要的结果为
| name | contact_phone | update_time |
|---|---|---|
| 王二 | 222 | 2022 |
| 张三 | 123 | 2019 |
| 李四 | 864 | 2021 |
1 数据准备
-- 创建表 t1
CREATE TABLE t1 (
name STRING,
contact_phone STRING,
update_time INT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',';
-- 创建表 t2
CREATE TABLE t2 (
name STRING,
contact_phone STRING,
update_time INT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',';
-- 创建表 t3
CREATE TABLE t3 (
name STRING,
contact_phone STRING,
update_time INT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',';
-- 插入 t1 数据
truncate table t1 ;
INSERT INTO t1 VALUES
('王二', '111', 2019),
('张三', '123', 2019),
('李四', '642', 2020);
-- 插入 t2 数据
truncate table t2 ;
INSERT INTO t2 VALUES
('王二', '222', 2022),
('张三', NULL, 2021),
('李四', '753', 2010);
-- 插入 t3 数据
INSERT INTO t3 VALUES
('张三', '789', 2012),
('李四', '864', 2021);2 问题分析
将三张表合并,形成原始数据表
select * from t1union allselect * from t2union allselect * from t3
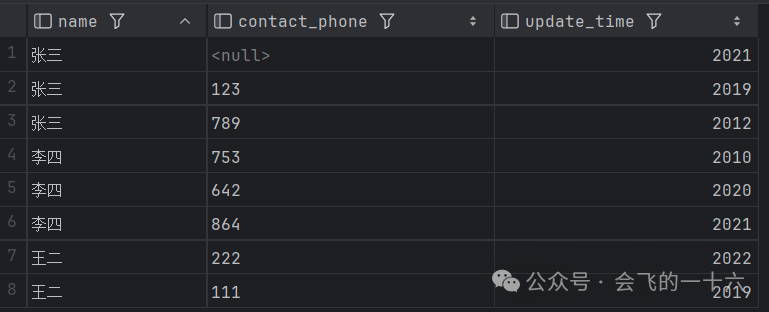
组内取最新时间点对应的值,我们一般用row_number()或first_value()函数,但如果直接使用分析函数会导致张三这一组数据取到最新的值为NULL,明显是不符合题意的,题目要求为字段不为NULL且最新。
方法1:利用order by nulls last特性求解
with temp as
(
select
a.*,
row_number() over(partition by name order by concat(update_time,contact_phone) desc nulls last) as rn
from
(
select * from t1
union all
select * from t2
union all
select * from t3
)a
)
select name
, contact_phone
, update_time
from temp where rn=1

方法2:底表直接过滤掉非法数据,然后使用row_number()函数
SELECTname,contact_phone,update_timeFROM (SELECTname,contact_phone,update_time,ROW_NUMBER() OVER (PARTITION BY nameORDER BY update_time DESC) AS rnFROM (-- 合并所有表并过滤空值SELECT name, contact_phone, update_timeFROM t1WHERE contact_phone IS NOT NULLUNION ALLSELECT name, contact_phone, update_timeFROM t2WHERE contact_phone IS NOT NULLUNION ALLSELECT name, contact_phone, update_timeFROM t3WHERE contact_phone IS NOT NULL) combined_data) ranked_dataWHERE rn = 1;
方法3:通过关联形式求解
with data as (-- 合并所有表并过滤空值SELECT name, contact_phone, update_timeFROM t1WHERE contact_phone IS NOT NULLUNION ALLSELECT name, contact_phone, update_timeFROM t2WHERE contact_phone IS NOT NULLUNION ALLSELECT name, contact_phone, update_timeFROM t3WHERE contact_phone IS NOT NULL)select t1.name, t1.contact_phone, t1.update_timefrom data t1join (select name, max(update_time) update_timefrom datagroup by name ) t2on t1.name = t2.nameand t1.update_time = t2.update_time

3 小结
通过上述方法,可高效解决多表合并、非空筛选与最新记录选取问题。核心在于:
- 数据清洗
严格过滤无效值;
- 排序控制
利用窗口函数和次级字段保证结果唯一性;
- NULL 处理
根据 Hive 版本选择
NULLS LAST或CASE表达式显式控制排序逻辑; - 类型安全
确保时间字段正确排序。
这些方法不仅适用于电话号码场景,还可推广至订单状态更新、用户行为日志等需提取最新有效记录的典型应用。
🚀 「SQL进阶实战技巧」专栏重磅上线! 🚀
🌟 从零到高手,解锁SQL的无限可能! 🌟
这里有SQL的终极进阶秘籍:
✅ 正则表达式精准提取数据、✅ Window函数玩转复杂分析、✅ Bitmap优化提速百倍查询
✅ 缺失值补全、✅ 分钟级趋势预测、✅ 非线性回归建模、✅ 逻辑推理破题、✅ 波峰智能检测
🛠️ 给数据工程师的超强工具箱:
👉 解决「电梯超载难题」👉 预测「商品零售增长」
👉 跳过「NULL值天坑」👉 拆解「JSON密钥迷宫」
👉 巧算「连续签到金币」👉 嗨翻「赛马趣味逻辑」
🔥 突破常规,用SQL实现Python级分析!
从线性回归到指数平滑预测,从块熵计算到TEO能量检测——原来SQL才是隐藏的科学计算利器!
📈 无论你是想优化千万级数据性能,还是用一句SQL破解公务员考题,这里都有答案!
🦅 让SQL飞越数据的天空,带你用代码写出商业洞见!
👉 点击探索,开启你的数据分析新次元!
👉专栏链接如下:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









