







我们在对数据进行预处理时,常常需要对数据做一些可视化的工作,以便能更清晰的认识数据内部的规律。
这里我们以kaggle案例泰坦尼克问题的数据做一些常用的可视化的工作。首先看下这个数据集:
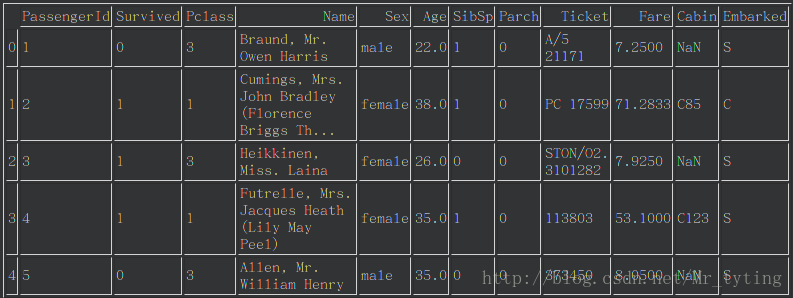
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
sorted([f.name for f in matplotlib.font_manager.fontManager.ttflist])
data_train=pd.read_csv('train.csv')
plt.plot(data_train.Age)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
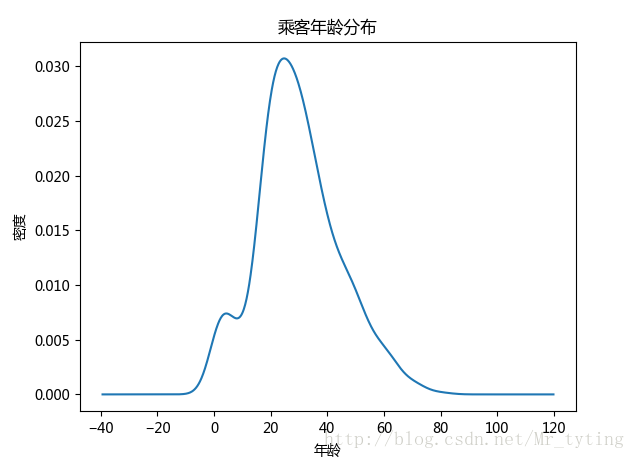
##现在我们想看看乘客年龄分布,kde就是密度分布,类似于直方图,数据落在在每个bin内的频率大小或者是密度大小
data_train.Age.plot(kind='kde')
plt.xlabel(u"年龄")# plots an axis lable
plt.ylabel(u"密度")
plt.title(u"乘客年龄分布")
- 1
- 2
- 3
- 4
- 5
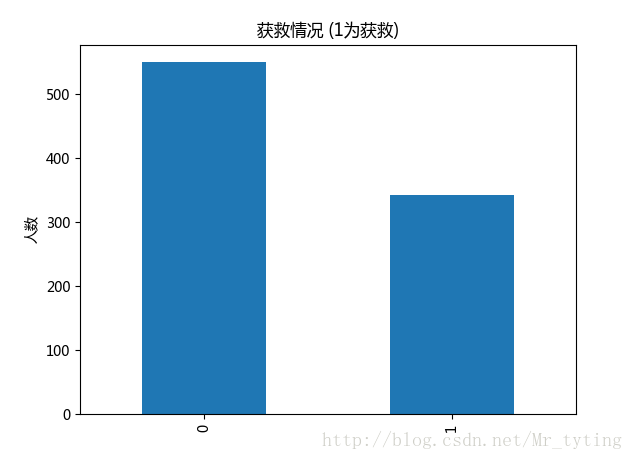
##现在看看获救人数和未获救人数对比
#plt.subplot2grid((2,3),(0,0))
data_train.Survived.value_counts().plot(kind='bar')# plots a bar graph of those who surived vs those who did not.
plt.title(u"获救情况 (1为获救)") # puts a title on our graph
plt.ylabel(u"人数")
- 1
- 2
- 3
- 4
- 5
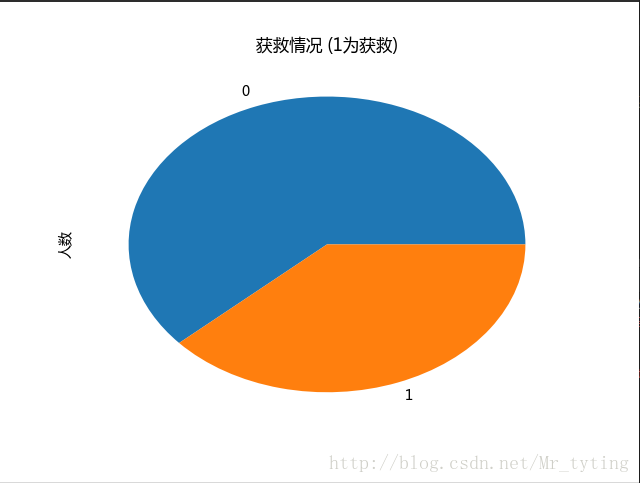
##也可以以饼状图看看获救人数和未获救人数对比
#plt.subplot2grid((2,3),(0,0))
data_train.Survived.value_counts().plot(kind='pie')# plots a bar graph of those who surived vs those who did not.
plt.title(u"获救情况 (1为获救)") # puts a title on our graph
plt.ylabel(u"人数")
- 1
- 2
- 3
- 4
- 5
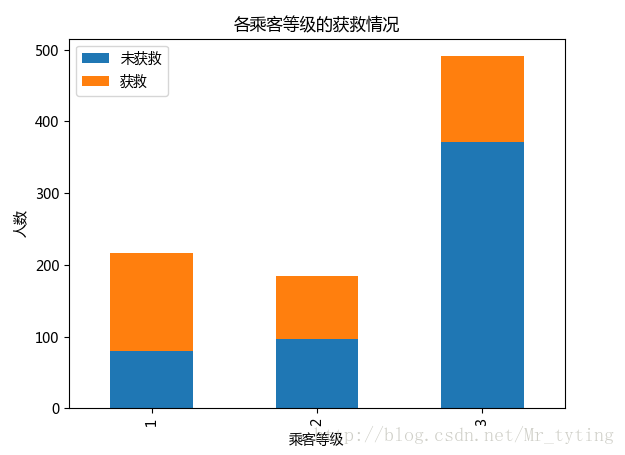
## 常看各乘客等级的获救情况
Survived_0 = data_train.Pclass[data_train.Survived == 0].value_counts()
Survived_1 = data_train.Pclass[data_train.Survived == 1].value_counts()
df=pd.DataFrame({
u'获救':Survived_1, u'未获救':Survived_0})
df.plot(kind='bar', stacked=True)
plt.title(u"各乘客等级的获救情况")
plt.xlabel(u"乘客等级")
plt.ylabel(u"人数")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
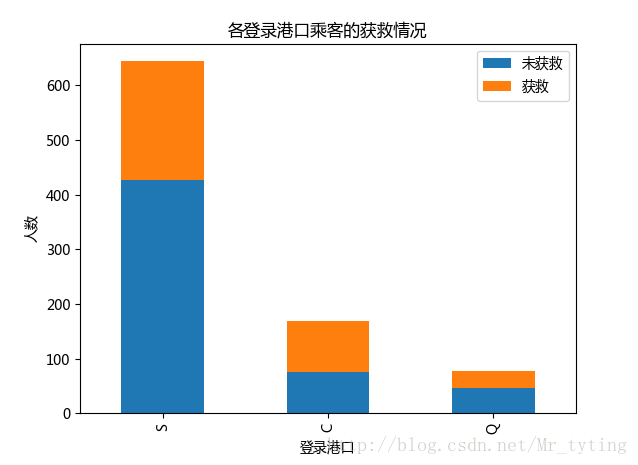
##查看各登录港口获救情况
Survived_0 = data_train.Embarked[data_train.Survived == 0].value_counts()
Survived_1 = data_train.Embarked[data_train.Survived == 1].value_counts()
df=pd.DataFrame({
u'获救':Survived_1, u'未获救':Survived_0})
df.plot(kind='bar', stacked=True)
plt.title(u"各登录港口乘客的获救情况")
plt.xlabel(u"登录港口")
plt.ylabel(u"人数")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
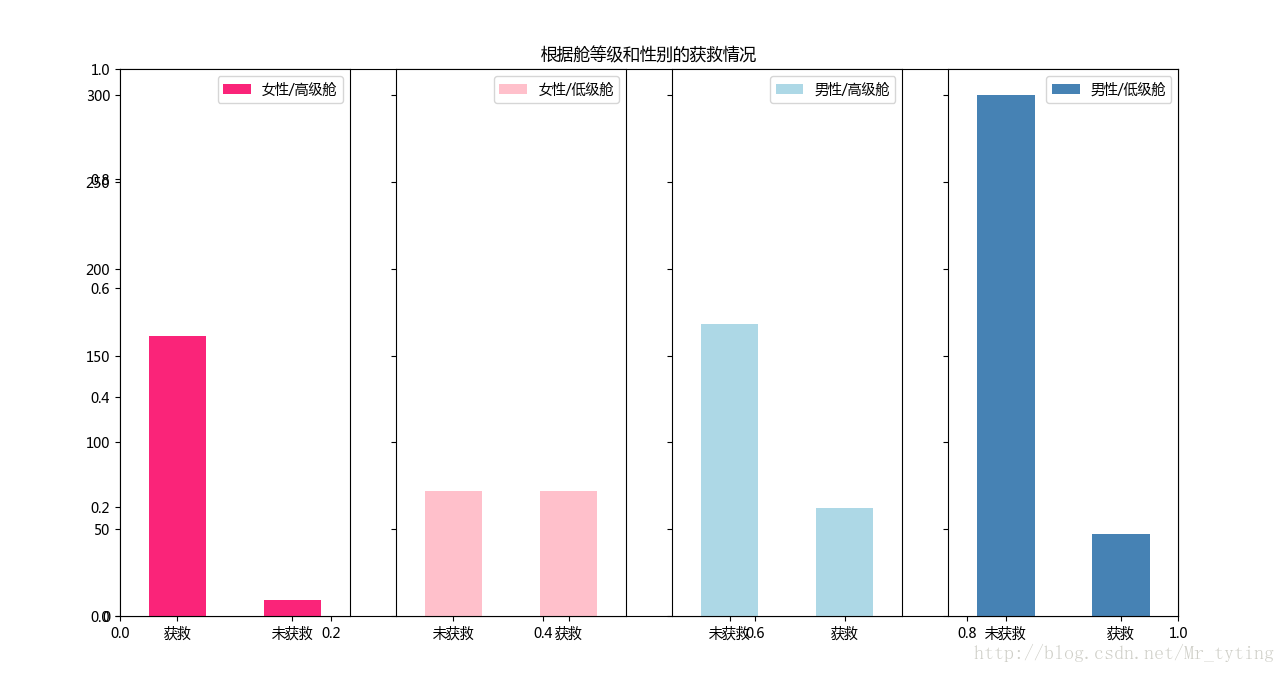
##再来看看各种级别舱情况下性别的获救情况
fig=plt.figure()
fig.set(alpha=0.65) # 设置图像透明度,无所谓
plt.title(u"根据舱等级和性别的获救情况")
ax1=fig.add_subplot(141)
data_train.Survived[data_train.Sex == 'female'][data_train.Pclass != 3].value_counts().plot(kind='bar', label="female highclass", color='#FA2479')
ax1.set_xticklabels([u"获救", u"未获救"], rotation=0)
ax1.legend([u"女性/高级舱"], loc='best')
ax2=fig.add_subplot(142, sharey=ax1)
data_train.Survived[data_train.Sex == 'female'][data_train.Pclass == 3].value_counts().plot(kind='bar', label='female, low class', color='pink')
ax2.set_xticklabels([u"未获救", u"获救"], rotation=0)
plt.legend([u"女性/低级舱"], loc='best')
ax3=fig.add_subplot(143, sharey=ax1)
data_train.Survived[data_train.Sex == 'male'][data_train.Pclass != 3].value_counts().plot(kind='bar', label='male, high class',color='lightblue')
ax3.set_xticklabels([u"未获救", u"获救"], rotation=0)
plt.legend([u"男性/高级舱"], loc='best')
ax4=fig.add_subplot(144, sharey=ax1)
data_train.Survived[data_train.Sex == 'male'][data_train.Pclass == 3].value_counts().plot(kind='bar', label='male low class', color='steelblue')
ax4.set_xticklabels([u"未获救", u"获救"], rotation=0)
plt.legend([u"男性/低级舱"], loc='best')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
ax.plot(np.arange(0,100,10),np.random.randn(10).cumsum(),marker='o')
ax.set_xticks([0,10,20,30,40,50,60,70,80,90]) ##设置x轴上显示的刻度
ax.grid()## 显示方格
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
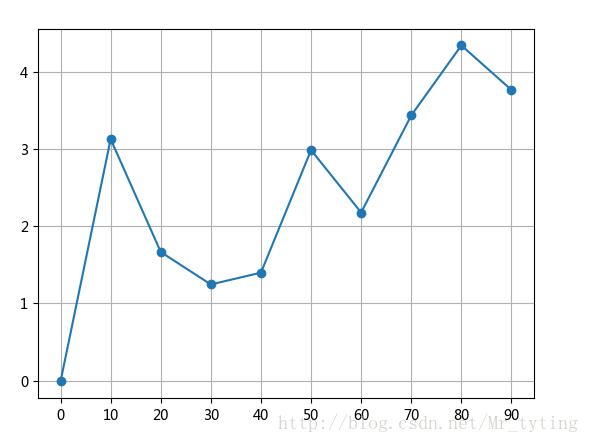
##现在我们想看看每个等级的舱的乘客的平均年龄
data_train.groupby('Pclass').mean().plot(y='Age',marker='o')
##注意参数marker='o'强调实际的数据点,会在实际的数据点上加一个实心点。如果要显示方格可在plot里面设置参数grid=True
plt.xlabel(u"舱级别")
plt.ylabel(u"平均年龄")
- 1
- 2
- 3
- 4
- 5
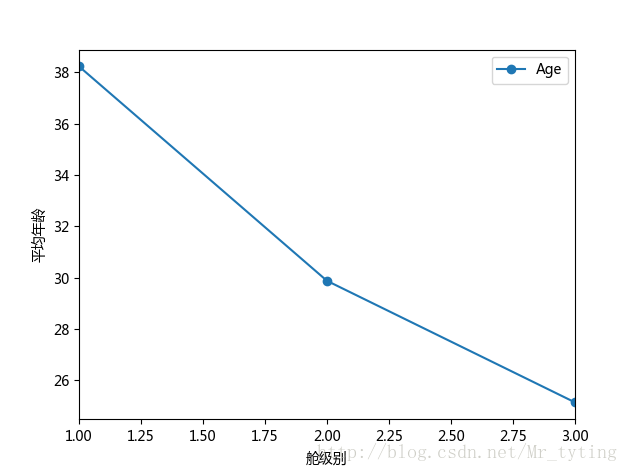
##也可以这样看看年龄和所在舱级别的关系
data_train.plot(x='Pclass',y='Age',kind='scatter')
plt.xlabel(u"舱级别")
plt.ylabel(u"年龄")
plt.show()
- 1
- 2
- 3
- 4
- 5
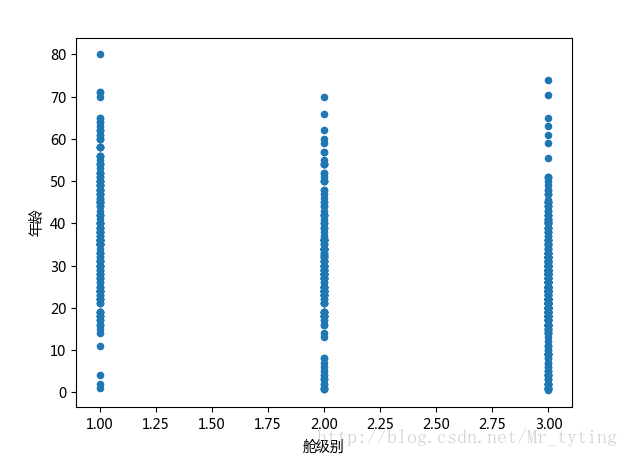
我们换一个连续性变量多的数据集,看看特征直接相关度。
corr = df_train_origin[['temp','weather','windspeed','day', 'month', 'hour','count']].corr()
# 用颜色深浅来表示相关度
plt.figure()
plt.matshow(corr)
plt.colorbar()
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
下面我们看看高维数据如何做可视化分析,首先咱们造个高维数据集
#numpy科学计算工具箱
import numpy as np
#使用make_classification构造1000个样本,每个样本有20个feature
from sklearn.datasets import make_classification
X, y = make_classification(1000, n_features=20, n_informative=2,
n_redundant=2, n_classes=2, random_state=0)
#存为dataframe格式
from pandas import DataFrame
df = DataFrame(np.hstack((X, y[:, None])),columns = range(20) + ["class"])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
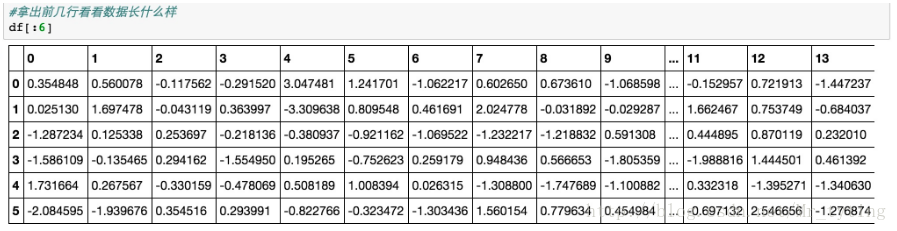
数据的可视化有很多工具包可以用,比如下面我们用来做数据可视化的工具包Seaborn。最简单的可视化就是数据散列分布图和柱状图,这个可以用Seanborn的pairplot来完成。以下图中2种颜色表示2种不同的类,因为20维的可视化没有办法在平面表示,我们取出了一部分维度,两两组成pair看数据在这2个维度平面上的分布状况,代码和结果如下:
#存为dataframe格式
from pandas import DataFrame
df = DataFrame(np.hstack((X, y[:, None])),columns = range(20) + ["class"])
import seaborn as sns
#使用pairplot去看不同特征维度pair下数据的空间分布状况
## vars表示把里面的特征两两做个可视化
_ = sns.pairplot(df[:50], vars=[8, 11, 12, 14, 19], hue="class", size=1.5)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
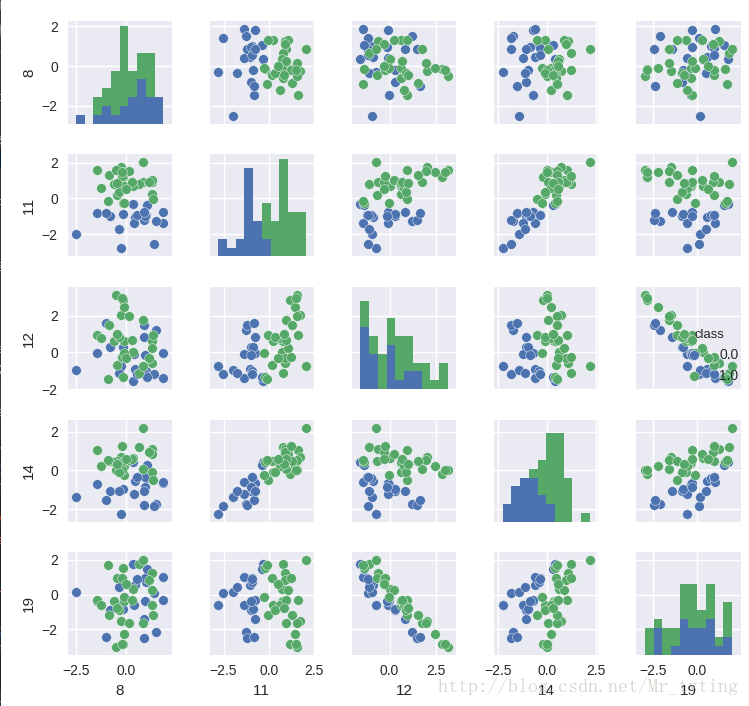
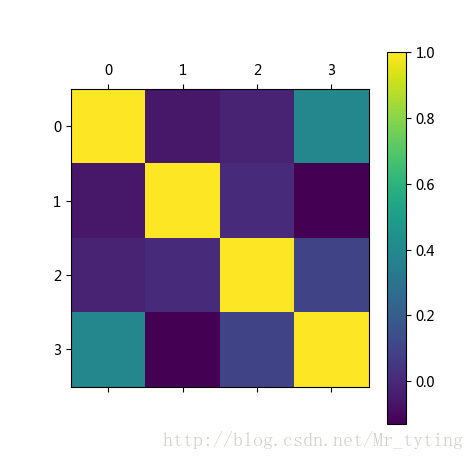
我们从散列图和柱状图上可以看出,确实有些维度的特征相对其他维度,有更好的区分度,比如第11维和14维看起来很有区分度。这两个维度上看,数据点是近似线性可分的。而12维和19维似乎呈现出了很高的负相关性。接下来我们用Seanborn中的corrplot来计算计算各维度特征之间(以及最后的类别)的相关性。代码和结果图如下:
import matplotlib.pyplot as plt
plt.figure(figsize=(12, 10))
_ = sns.linearmodels.corrplot(df, annot=False)
plt.show()
- 1
- 2
- 3
- 4
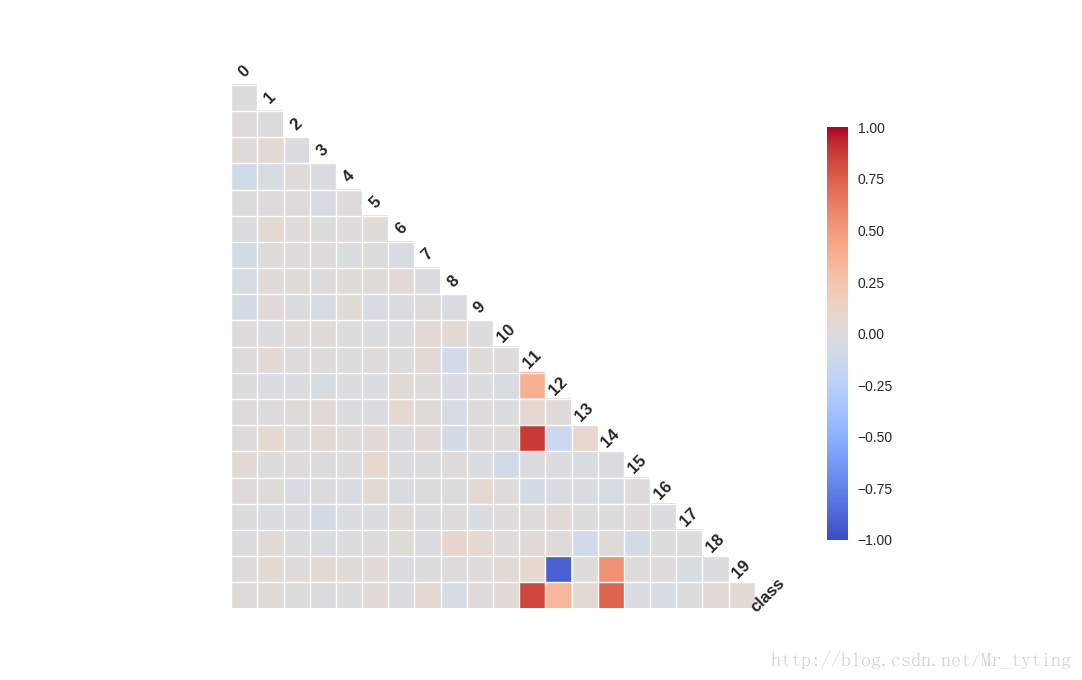
相关性图很好地印证了我们之前的想法,可以看到第11维特征和第14维特征和类别有极强的相关性,同时它们俩之间也有极高的相关性。而第12维特征和第19维特征却呈现出极强的负相关性。强相关的特征其实包含了一些冗余的特征,而除掉上图中颜色较深的特征,其余特征包含的信息量就没有这么大了,它们和最后的类别相关度不高,甚至各自之间也没什么先惯性。
新增部分
绘制正态分布概率密度函数代码如下
mu = 0##均值为0
sigma = 1##方差为1
x = np.linspace(mu - 3 * sigma, mu + 3 * sigma, 51)
y = np.exp(-(x - mu) ** 2 / (2 * sigma ** 2)) / (math.sqrt(2 * math.pi) * sigma)
print x.shape
print 'x = \n', x
print y.shape
print 'y = \n', y
# plt.plot(x, y, 'ro-', linewidth=2)
plt.figure(facecolor='w') ## 背景颜色取白色
## 'r-':表示实线绘制,然后再画x,y,'go'表示用圆圈绘制,linewidth=2表示实线宽度2,markersize= 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









