







爬取中国大学排名
# -*- coding: utf-8 -*-
"""
Spyder Editor
This is a temporary script file.
"""
#程序的结构设计
#步骤一:从网络中获取大学排名网页内容
# getHTMLText()
#步骤二:提取网页内容中信息到合适的数据集结构
# fillUnivList()
#步骤三:利用数据集输出结果
# printUnivList()
import requests
from bs4 import BeautifulSoup
import bs4
# @url URL
# @return url中的内容
def getHTMLText(url):
try:
r = requests.get(url,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
# 将html页面放到ulist数据中
# @ulist two list
def fillUnivList(ulist,html):
soup = BeautifulSoup(html,"html.parser")
pass
for tr in soup.find('tbody').children:
#childer也可能包含字符串(也就是只留下tr标签):
if isinstance(tr,bs4.element.Tag):
#将所有的td标签存为一个列表类型,叫tds
tds = tr('td')
ulist.append([tds[0].string, tds[1].string, tds[3].string ])
# 将ulist信息打印出来
#
#@num int 表示想要打印出多少条
def printUnivList(ulist,num):
print("{:^10}\t{:^20}\t{:^10}".format("排名","学校名称","总分"))
for i in range(num):
u = ulist[i]
print("{:^10}\t{:^20}\t{:^10}".format(u[0],u[1],u[2]))
print("Suc" + str(num))
def main():
uinfo = []
url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html'
html = getHTMLText(url)
fillUnivList(uinfo,html)
printUnivList(uinfo,20) # 20 univs
main()
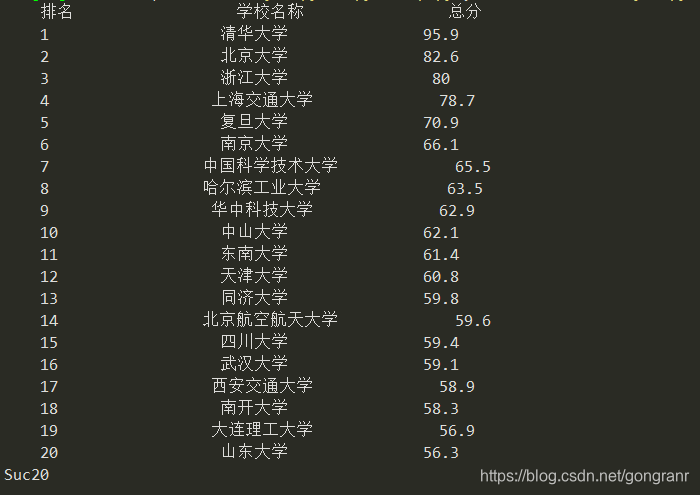
爬取中国大学优化
以上输出存在如下问题
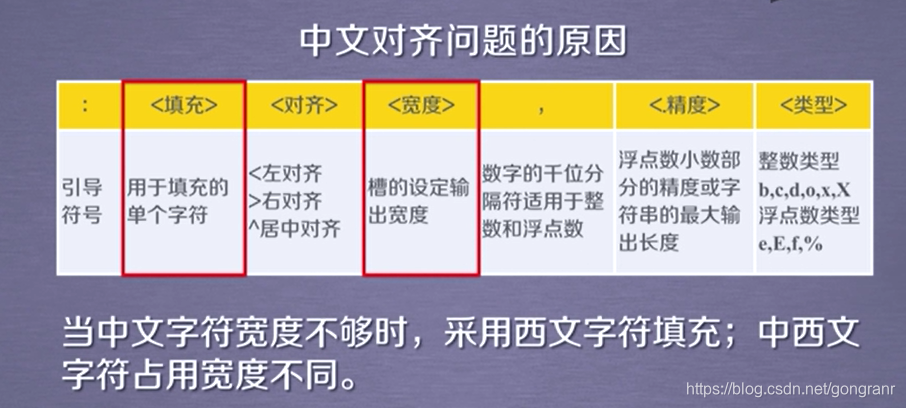
解决思路
将 西文的字符填充改为中文字符填充

解决方法,对printUnivList做如下更改















 1315
1315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









