







 本文介绍了ID3决策树的基本流程、划分选择(信息增益、增益率、基尼指数)、剪枝处理(预剪枝、后剪枝)、连续值与缺失值处理,并提供了Python代码实现。通过西瓜挑选的例子阐述了决策树的工作原理,探讨了如何避免过拟合和处理连续及缺失值的情况。
本文介绍了ID3决策树的基本流程、划分选择(信息增益、增益率、基尼指数)、剪枝处理(预剪枝、后剪枝)、连续值与缺失值处理,并提供了Python代码实现。通过西瓜挑选的例子阐述了决策树的工作原理,探讨了如何避免过拟合和处理连续及缺失值的情况。
本文实现的是ID3决策树。一开始是想实现一下adaboost算法,但是弱分类器选择的是决策树桩,因此干脆先实现决策树。本文基于周志华老师的《机器学习》第四章
目录
- 基本流程
- 划分选择
- 信息增益
- 增益率
- 基尼指数
- 剪枝处理
- 预剪枝
- 后剪枝
- 连续与缺失值
- 连续值处理
- 缺失值处理
- 代码
- 代码说明
- 完整代码
正文
1. 基本流程
决策树对某个样本进行分类实际上是模拟人们思维的一种决策过程。以买西瓜为例,人们在挑选西瓜时的决策过程大致为如下过程,首先看一看西瓜的色泽,如果是青绿的,那么这个瓜可能是好瓜,如果这个瓜外表已经泛黄甚至是黑的,就几乎可以判定这个瓜不好吃。是不是颜色是青绿的一定是好瓜呢?显然也未必,人们还要继续看看其他的一些属性,比如根蒂,根据经验,如果根蒂是硬挺的,说明瓜可能刚采摘不久,还比较新鲜,如果是蜷缩柔软的,说明已经摘下很长时间了。那么根据我们的经验,可能根蒂硬挺的瓜是好瓜。这样继续判断别的属性,直到我们可以断定这个瓜是好瓜还是坏瓜为止。
这个决策过程可以用如下的决策流程图来表示:
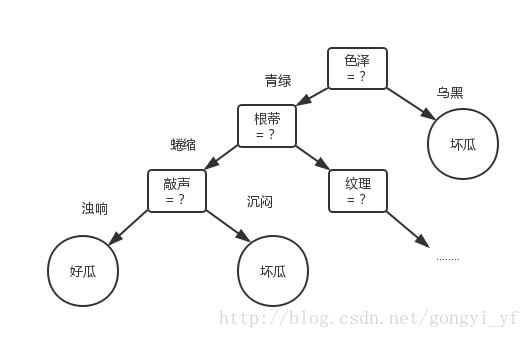
这是西瓜问题的一种可能的决策过程。这个树形的结构就是所说的决策树。特殊一点,我在买瓜的时候没有什么经验,看着别人买瓜的时候听一听瓜的敲声,我也会装作很懂的敲一敲,最后挑个长的好看的。那么显然此时我的决策树只有一层,就叫做决策树桩。
决策树的生成过程大致如下:首先选择一个“好的属性”,根据该属性的所有取值为这个节点生成孩子节点,如上图中的色泽属性有“青绿”和“乌黑”2种可能的取值,于是色泽节点就有两个孩子节点,将所有色泽为“青绿”的样本划入第一个节点,所有色泽为“乌黑”的样本划入第二个节点。这样递归生成决策树。
这里有两个问题:(1)什么时候递归返回?(2)什么是“好的属性”?
首先看第一个问题。递归返回一个有3种情况,(1)当前节点包含的样本全部属于一个类别。(2)当前已经使用了样本的所有属性,或者样本在所有属性上的取值相同,无法区分。(3)当前节点包含的样本集合为空,不能划分。
第一种情况下,叶节点的类别就是这些样本的类别。第二种情况下,叶节点的类别是样本集中所属样本数量最多的类别。第三种情况下,取父节点中所含样本最多的类别。
这是第一个问题,那么什么是“好的属性”呢?
2. 划分选择
2.1 信息增益
直观上来看,我们在做出决策时,希望当前选择的属性能够把尽可能多的样本分对,即按照每个取值,子样本集的“纯度”尽可能高。在信息学上,经常用信息熵来度量集合的纯度。
假定当前样本集合 D中第 κ κ 类样本中所占的比例为 pκ(κ=1,2,3,…,∣γ∣) p κ ( κ = 1 , 2 , 3 , … , ∣ γ ∣ ) ,则D的信息熵定义为:
Ent(D)的值越小,则D的纯度越高。
假定离散属性a有V可能的取值 { a1,a2,…,aV} { a 1 , a 2 , … , a V } ,若使用a来对样本集合D进行划分,则会产生V个分枝节点,其中第 ν ν 个分枝节点包含了D中所有在属性a上取值为 aν a ν 的样本,记为 Dν D ν 。根据式(1)计算出 Dν D ν 的信息熵,再考虑到不同的分枝节点所包含的样本数不同,给分枝节点赋予权重 ∣Dν∣/∣D∣ ∣ D ν ∣ / ∣ D ∣ ,即样本数越多的分支节点的影响越大,于是可以计算出属性a对样本集D记性划分所获得的“信息增益”:
一般而言,信息增益越大,则意味着使用属性a来进行划分所获得的“纯度提升”越大,也可以理解为在划分的过程中获取的信息越多。因此,我们就优先选择使得 Gain(D,a) G a i n ( D , a ) 最大的属性a。
用机器学习中的数据集为例:
| 编号 | 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 好瓜? |
|---|---|---|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | Y |
| 2 | 1 | 0 | 1 | 0 | 0 | 0 | Y |
| 3 | 1 | 0 | 0 | 0 | 0 | 0 | Y |
| 4 | 0 | 0 | 1 | 0 | 0 | 0 | Y |
| 5 | 2 | 0 | 0 | 0 | 0 | 0 | Y |
| 6 | 0 | 1 | 0 | 0 | 1 | 1 | Y |
| 7 | 1 | 1 | 0 | 1 | 1 | 1 | Y |
| 8 | 1 | 1 | 0 | 0 | 1 | 0 | Y |
| 9 | 1 | 1 | 1 | 1 | 1 | 0 | N |
| 10 | 0 | 2 | 2 | 0 | 2 | 1 | N |
| 11 | 2 | 2 | 2 | 2 | 2 | 0 | N |
| 12 | 2 | 0 | 0 | 2 | 2 | 1 | N |
| 13 | 0 | 1 | 0 | 1 | 0 | 0 | N |
| 14 | 2 | 1 | 1 | 1 | 0 | 0 | N |
| 15 | 1 | 1 | 0 | 0 | 1 | 1 | N |
| 16 | 2 | 0 | 0 | 2 | 2 | 0 | N |
| 17 | 0 | 0 | 1 | 1 | 1 | 0 | N |
对于上表中数字和字母的说明:
| 数字 | 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 好瓜? |
|---|---|---|---|---|---|---|---|
| 0 | 青绿 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | |
| 1 | 乌黑 | 稍蜷 | 沉闷 | 稍糊 | 稍凹 | 软粘 | |
| 2 | 浅白 | 硬挺 | 清脆 | 模糊 | 平坦 | ||
| Y | 是 | ||||||
| N | 否 |
数据集正例(好瓜)的比例为 p1=817
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 109
109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









