







[‘class’, ‘delattr’, ‘dict’, ‘dir’, ‘doc’, ‘eq’, ‘format’, ‘ge’, ‘getattribute’, ‘getstate’, ‘gt’, ‘hash’, ‘init’, ‘init_subclass’, ‘le’, ‘lt’, ‘module’, ‘ne’, ‘new’, ‘reduce’, ‘reduce_ex’, ‘repr’, ‘setattr’, ‘setstate’, ‘sizeof’, ‘sklearn_is_fitted’, ‘str’, ‘subclasshook’, ‘weakref’, ‘_can_use_inplace_predict’, ‘_check_n_features’, ‘_configure_fit’, ‘_early_stopping_attr’, ‘_estimator_type’, ‘_get_iteration_range’, ‘_get_param_names’, ‘_get_tags’, ‘_get_type’, ‘more_tags’, ‘repr_html’, ‘repr_html_inner’, ‘repr_mimebundle’, ‘set_evaluation_result’, ‘validate_data’, ‘apply’, ‘base_score’, ‘best_iteration’, ‘best_ntree_limit’, ‘best_score’, ‘booster’, ***'coef’, ‘***colsample_bylevel’, ‘colsample_bynode’, ‘colsample_bytree’, ‘enable_categorical’, ‘evals_result’, 'feature_importances’, ‘fit’, ‘gamma’, ‘get_booster’, ‘get_num_boosting_rounds’, ‘get_params’, ‘get_xgb_params’, ‘gpu_id’, ‘importance_type’, ‘interaction_constraints’, 'intercept’, ‘learning_rate’, ‘load_model’, ‘max_delta_step’, ‘max_depth’, ‘min_child_weight’, ‘missing’, ‘monotone_constraints’, ‘n_estimators’, 'n_features_in’, ‘n_jobs’, ‘num_parallel_tree’, ‘objective’, ‘predict’, ‘predict_proba’, ‘predictor’, ‘random_state’, ‘reg_alpha’, ‘reg_lambda’, ‘save_model’, ‘scale_pos_weight’, ‘score’, ‘set_params’, ‘subsample’, ‘tree_method’, ‘use_label_encoder’, ‘validate_parameters’, ‘verbosity’]
Traceback (most recent call last):
File “D:/AllExploreDownloads/IDM/ExtraCode/feature_selection.py”, line 682, in
filter_features(rectified_unrepeated_save_path, ‘./merged_features/filtered_features.csv’)
File “D:/AllExploreDownloads/IDM/ExtraCode/feature_selection.py”, line 626, in filter_features
is_remaining_list = xgboost_rfe_filtered_features(df_feat_data, df_label_data, df_columns_list[3:], is_remaining_list)
File “D:/AllExploreDownloads/IDM/ExtraCode/feature_selection.py”, line 457, in xgboost_rfe_filtered_features
print(“model coef:”, selector.estimator.coef_)
File “D:\Anaconda3\lib\site-packages\xgboost\sklearn.py”, line 1064, in coef_
raise AttributeError(
AttributeError: Coefficients are not defined for Booster type None
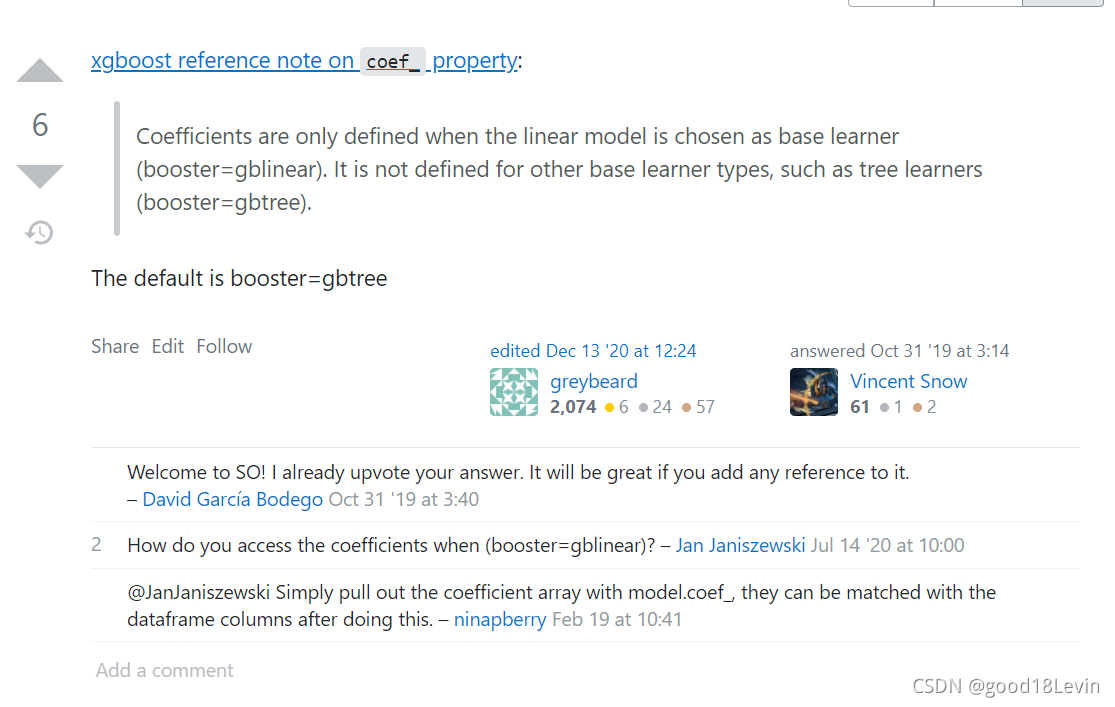
上方是dir(XGBoostClassifier对象)的输出以及获取其coef_时的报错,可以发现dir的属性和方法并不一定是该类的对象就一定可以使用。

















 29万+
29万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









