







 谷歌推出的Dataset Search是一个搜索引擎,旨在统一检索网络上的数据集。它利用schema.org元数据对数据集进行索引,目前包含了4600多个域名的3100多万个数据集,主要集中在地球科学、社会科学和生物学等领域。尽管存在数据集的可发现性和引用问题,但谷歌通过提供DOI和开放许可信息等方式提高了数据集的重用性。
谷歌推出的Dataset Search是一个搜索引擎,旨在统一检索网络上的数据集。它利用schema.org元数据对数据集进行索引,目前包含了4600多个域名的3100多万个数据集,主要集中在地球科学、社会科学和生物学等领域。尽管存在数据集的可发现性和引用问题,但谷歌通过提供DOI和开放许可信息等方式提高了数据集的重用性。

文 / Google Research 研究员 Natasha Noy 和软件工程师 Omar Benjelloun
网络上的数据集成千上万,涵盖了从传感器数据、政府记录到科学实验结果和业务报告等各种内容。事实上,几乎任何您能想象到的东西都有数据集,比方说帝企鹅的饮食,或者远程工作者的居住地。两年多前,我们着手设计了一个搜索引擎,为这些数据集和成千上万的存储库提供一个单一的入口点。最终成果就是 Dataset Search,此工具最初于 2018 年以测试版亮相,完整版在 2020 年 1 月全面推出。除了推进数据访问,Dataset Search 还直接利用来自数据集网页中使用 schema.org 结构的元数据描述对数据集进行调节和索引。
Dataset Search
https://datasetsearch.research.google.com/完整版
https://blog.google/products/search/discovering-millions-datasets-web/
截至目前,整个 Dataset Search 语料库包含来自 4600 多个互联网域名的 3100 多万个数据集。下图显示了过去两年中语料库的增长(虽然我们仍不清楚目前网络上的数据集在 Dataset Search 所占的比例,但这一数字始终在稳步上升)。
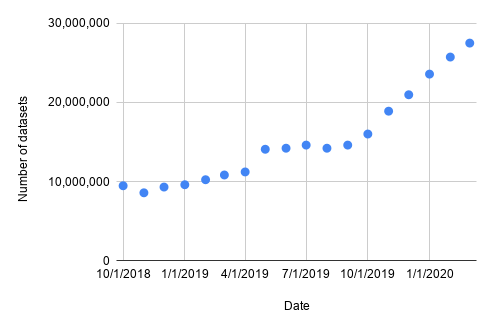
由 Dataset Search 索引的数据集的数量增长
为了更好地理解通过 Dataset Search 获得的数据集的广度和实用性,我们发表了“Google Dataset Search by the Numbers”,这篇论文被 2020 年 International Semantic Web Conference 收录。我们在此文中简述了可用数据集,介绍了来自其分析的指标和洞见,并提出了发布未来科学数据集的最佳做法。为了其他研究人员能够使用元数据来构建分析和工具,我们还公开了数据的一个子集。
Google Dataset Search by the Numbers
https://research.google/pubs/pub49385/数据的一个子集
https://www.kaggle.com/googleai/dataset-search-metadata-for-datasets
一系列数据集主题
为了确定数据集所涵盖主题的分布,我们根据
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 37
37

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









