






活动介绍
谷歌开发者招募活动是专为 Google 技术的爱好者及开发者们开展的活动,旨在鼓励大家通过多种形式 (文章/视频/coding 等) 创作与 Google 技术相关的讲解分享、实践案例或活动感受等内容,展示代码、框架、平台在真实世界中的生动表现,以及分享您应用 AI 技术的故事经历与成果。
作者简介
本文作者 ZY,Datawhale 技术架构师,StateOfJS 调查中国区负责人,从事 Web 开发 6 年。
文章导读
本文作者借助 Gemini 强大的多模态能力研发了一款文案 "拍立得" 应用,大家可以在海外生活和工作时使用,通过简单操作即可快速生成文案,节省时间,提高创作效率。
*以下为投稿原文
引言
在日常生活中,你是否在看上一款好物想要种草给朋友时,因为不会写种草文案而苦恼?又是否会在出去吃饭写好评赠送菜品时,因为憋不出好评文案而烦躁?在工作场景中,你或许也需要抓人眼球的文案来为您的产品吸引更多用户,进一步将业务开拓至海外市场。而 Gemini 强大的多模态能力,让我一瞬间灵感迸发——使用 LLM 来帮助我们辅助生成文案,这不正好能解决上面这些问题嘛!
于是,我借助 Gemini 的 API*,完成了一款图像文案拍立得应用,有了它,你将不会因为想不出文案而烦恼!
如上面的演示视频所示,当你发现了一款好物想要在小红书上给朋友种草的时候,可以直接拍一下,生成种草文案。当你网购了点水果想拿个返现红包但又苦于写好评文案的时候,可以直接拍一下,生成好评文案。当你研发了一款产品想要推荐给海外用户,可以直接拍一下,生成推荐文案。你还可以直接把他复制到剪贴板,然后粘贴到对应的地方。
*Gemini API 仅适用于出海开发者
技术实现
接下来我会为大家介绍图像文案拍立得应用中重点功能的实现方式。
步骤一: 初始化项目
开发项目的第一步,当然是初始化项目——我们的项目是使用 Nuxt.js 框架搭建的全栈项目,并使用 Gemini-1.5-flash 提供底层的多模态能力。
为什么使用 Gemini-1.5-flash 呢?主要是因为它是免费的,而且速度非常快,快到你不使用流式输出都不会对交互体验有太大的影响。
回到初始化项目中来,首先,我们要确保我们拥有最新版本的 Node.js,然后,我们使用 npx nuxi@latest init gemini-pailido-demo 命令来初始化一个名为 gemini-pailido-demo 的项目,进入项目后使用 npm install 安装依赖。这样,我们的全栈项目就初始化完成了。
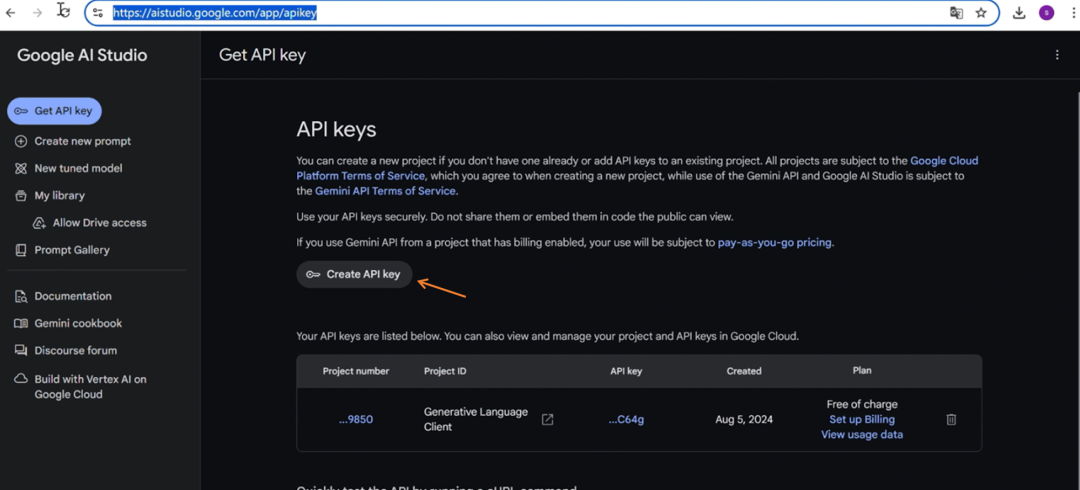
然后我们去 Google AI Studio (https://aistudio.google.com/app/apikey) 来申请一个 Gemini API KEY,用于后续请求大模型。可以参考下面这张图:
步骤二: 相机和视频流逻辑处理
初始化相机
为了调起相机并获取视频流,首先要在 <template> 中新建一个 <video> 标签 (注意必须要有 autoplay 和 playsinline 属性),并通过 videoElement 这个 ref 获取到,然后在 onMounted 这个生命周期钩子函数中使用 navigator.mediaDevices 获取到用户相机数据,再将 <video> 标签的流设置成摄像机的视频流。
当视频流加载完成后,也就是在 onloadedmetadata 函数中,使用 play 函数播放视频流。
另外不要忘记做一下异常处理,在 onMounted 之前,首先要停止之前的视频流 (如果有的话)。
<script>
const videoElement = ref()
const videoStream = ref()
onMounted(() => {
// 停止之前的流
if (videoStream.value) {
videoStream.value.getTracks().forEach((track) => track.stop());
}
// 获取用户媒体设备
navigator.mediaDevices
.getUserMedia({ video: { facingMode: "environment" } })
.then((mediaStream) => {
// 将video元素的流设置成摄像机的视频流
videoStream.value = mediaStream;
videoElement.value.srcObject = mediaStream;
// 视频流加载完成后播放
videoElement.value.onloadedmetadata = () => {
videoElement.value.play();
};
})
.catch(function (err) {
console.log(err.name + ": " + err.message);
});
})
</script>
<template>
<div class="video-wrapper">
<video ref="videoElement" class="video" autoplay playsinline></video>
</div>
</template>处理拍照逻辑
在我们成功调起相机,将视频流显示到页面上后,我们来继续处理拍照的逻辑,首先我们要新增一个响应式变量 cameraStatus 来记录相机的状态。然后我们写一个名为 onShutterClick 的点击事件,绑定到拍照按钮上。再然后我们在 <template> 中新建一个 <canvas> 标签用于绘制拍照后的图片,并写一个 drawVideoToCanvas 函数,这个函数是用来将拍照时的图像绘制到 <canvas> 里。
<script>
//上述初始化视频的逻辑
//......
const CAMERA_STATUS_ENUM = {
DEFAULT: 1,
LOADING: 2,
OUTPUT: 3,
}
const cameraStatus = ref(CAMERA_STATUS_ENUM.DEFAULT) // 记录相机状态
const drawVideoToCanvas = () => {
// 用来将拍照时的图像绘制到canvas,下面会详细展开
}
// 拍照点击事件
const onShutterClick = () => {
cameraStatus.value = CAMERA_STATUS_ENUM.LOADING
const base64Image = drawVideoToCanvas()
}
</script>
<template>
<div class="video-wrapper">
<video ref="videoElement" autoplay playsinline></video>
<canvas v-show="cameraStatus !== CAMERA_STATUS_ENUM.DEFAULT" ref="canvasElement"></canvas>
</div>
<div @click="onShutterClick">拍照</div>
</template>拍照逻辑细节
drawVideoToCanvas 函数主要分成三部分,第一部分是通过计算视频的宽高比和 <canvas> 画布的宽高比,让二者的宽高保持一致,这样才能保证我们在 <canvas> 上绘制的图像不失真。
第二部分是使用 drawImage 函数来绘制拍照的图像。
第三部分是将图像转换为 base64 格式的数据并返回,这个会在后面调用 Gemini API 时用到。
const drawVideoToCanvas = () => {
const canvas = canvasElement.value;
canvas.width = videoElement.value.clientWidth;
canvas.height = videoElement.value.clientHeight;
// 绘制内容
const ctx = canvas.getContext("2d");
const videoRatio = videoElement.value.videoWidth / videoElement.value.videoHeight;
const canvasRatio = canvas.width / canvas.height;
let drawWidth, drawHeight, startX, startY;
if (videoRatio > canvasRatio) {
// 视频宽高比大于画布宽高比,绘制高度等等于视频高度,绘制宽度等于视频高度除以画布宽高比
drawHeight = videoElement.value.videoHeight;
drawWidth = videoElement.value.videoHeight * canvasRatio;
// 计算绘制起始点坐标
startX = (videoElement.value.vi7udeoWidth - drawWidth) / 2;
startY = 0;
} else {
// 视频宽高比小于等于画布宽高比,绘制宽度等于视频宽度,绘制高度等于视频宽度除以画布宽高比
drawWidth = videoElement.value.videoWidth;
drawHeight = videoElement.value.videoWidth / canvasRatio;
// 计算绘制起始点坐标
startX = 0;
startY = (videoElement.value.videoHeight - drawHeight) / 2;
}
// 使用canvas的drawImage方法将视频绘制到画布上
ctx.drawImage(
videoElement.value,
startX,
startY,
drawWidth,
drawHeight,
0,
0,
canvas.width,
canvas.height
);
// 从dataURL中移除数据URL的前缀部分,以获取纯Base64编码的图像数据
const dataURL = canvas.toDataURL("image/png");
let base64Image = dataURL.replace(
/^data:image\/(png|jpg);base64,/,
""
);
return base64Image
}处理完拍照逻辑后,就能拿到拍摄照片的数据,去请求 Gemini 的多模态 API 了。
步骤三: 编写提示词&处理
Gemini 多模态请求
Gemini API 使用介绍
我们先来看一下 Gemini API 如何使用吧。Gemini API 的请求地址,请求参数和返回结构如下:
| 请求方式 | POST |
| 请求地址 | https://generativelanguage.googleapis.com/v1/models/gemini-1.5-flash:generateContent?key=${我是API的KEY} |
| 请求参数 | { "contents": [ { "role": "user", "parts": [ { "text": "我是提示词我是提示词" }, { "inlineData": { "mimeType": "我是图片格式", "data": "我是base64图片数据" } } ] } ] } |
| 返回值 | { "candidates": [ { "content": { "parts": [ { "text": "我是生成的数据" } ], "role": "model" }, "finishReason": "STOP", "index": 0, "safetyRatings": [] } ], "usageMetadata": {} } |
请求地址中需要拼接你申请好的 API key,请求参数的格式中 text 需要传入提示词,mimeType 需要传入图片格式,data 需要传入 base64 图片数据。返回结构中的 text 字段即为大模型的输出。
接口处理
在明确了 Gemini API 的使用方式后,就可以处理接口了,我们先新建一个 server/api/gemini.post.ts 文件,这个文件会生成一个 /api/gemini 接口。具体的内容则是根据传入的生成模式 id 和 base64 图片数据请求 Gemini API,并返回结果。
import axios from "axios";
export default defineEventHandler(async (event) => {
const body = await readBody(event)
const API_KEY = "你申请的Gemini KEY"
// 各类模式的提示词
const PROMPT = {
"1": { id: 1, name: "小红书风格", prompt: "你是一位小红书博主,专注于为用户推荐种草有价值的物品。根据提供的图片信息,使用小红书风格创作一篇种草文案,只需要输出纯文字即可,不需要Markdown格式:", },
"2": { id: 2, name: "好评大师", prompt: "你是一名大众点评专家,专注于从消费者反馈中提取有价值的信息并提供详细的优缺点分析。根据提供的图片信息,写一篇好评,只需要输出纯文字即可,不需要Markdown格式:", },
"3": { id: 3, name: "一句话文案", prompt: "根据图中的信息,用非常精炼的一句话进行描述,需要有诗意,有洞察力,下面是图片信息,只需要输出纯文字即可,不需要Markdown格式:", },
}
if (!body?.id || !body?.image) {
return {message: "缺少必要参数"};
}
try {
// 请求gemini API并进行处理
const res = await axios.post(`https://generativelanguage.googleapis.com/v1/models/gemini-1.5-flash:generateContent?key=${API_KEY}`, {
"contents": [
{
"role": "user",
"parts": [
{ "text": PROMPT[body.id].prompt },
{
"inlineData": {
"mimeType": "image/png",
"data": body.image
}
}
]
}
]
})
const outputText = res.data.candidates[0].content.parts[0].text
return {
outputText,
message: "请求成功"
}
} catch (e) {
return {
error: e,
message: "请求失败"
}
}
})页面请求逻辑处理
写好接口逻辑后,就可以在页面中使用 $fetch 来调用 /api/gemini 接口。
另外,我们还要新建一个名为 geminiText 的响应式变量,用于记录并展示大模型生成文案的内容,并写一个 onCloseClick 事件,绑定到生成文案的关闭按钮上。
<script>
//上述初始化视频和处理canvas的逻辑
// ......
const geminiText = ref("") // 大模型生成的文案内容
const onShutterClick = () => {
cameraStatus.value = CAMERA_STATUS_ENUM.LOADING
const base64Image = drawVideoToCanvas()
requestGemini(base64Image)
}
const requestGemini = (base64Image) => {
// 请求Gemini API
$fetch(`/api/gemini`, {
method: "post",
body: {
id: styleList.value[styleSelectIndex.value].id.toString(),
image: base64Image,
},
}).then(res => res.json()).then(res => {
cameraStatus.value = CAMERA_STATUS_ENUM.OUTPUT
geminiText.value = res.outputText
})
}
const onCloseClick = () => {
geminiText.value = ""
cameraStatus.value = CAMERA_STATUS_ENUM.DEFAULT
}
</script>
<template>
<div class="video-wrapper">
<video ref="videoElement" autoplay playsinline></video>
<canvas v-show="cameraStatus !== CAMERA_STATUS_ENUM.DEFAULT" ref="canvasElement"></canvas>
<div class="gemini-loading" v-if="cameraStatus === CAMERA_STATUS_ENUM.LOADING">让我想想……</div>
<div class="gemini-output" v-if="cameraStatus === CAMERA_STATUS_ENUM.OUTPUT">
<p class="gemini-text">{{ geminiText }}</p>
<div class="close-button" @click="onCloseClick">关闭</div>
</div>
</div>
<div @click="onShutterClick">拍照</div>
</template>到这里,图像文案拍立得应用的主要内容就做好了!(当然,你也可以根据你自己的喜好为页面添加 css 样式)
延伸内容
虽然说我们已经实现了 MVP 版本的图像文案拍立得应用,当玩具给身边的朋友尝尝鲜已经足够了,但从工程的角度来看,项目仍然有不少问题,比如:
长文本流式输出
图片和生成的文案不能持久化存储,退出页面后就消失了
下面会简单介绍一下这些问题的解决要点,供感兴趣的朋友们继续探索。
流式输出
虽然 Gemini 输出速度足够快,小于 200 字的场景基本都可以快速输出,但在长文本生成的场景时,仍然需要使用流式输出来优化用户体验。
我们在 API 中增加 alt=sse 参数即可返回流式输出。
https://generativelanguage.googleapis.com/v1/models/gemini-1.5-flash:generateContent?alt=sse&key=${API_KEY}在 API 接口中,我们使用 sendStreamAPI 来返回流式数据。而处理流式输出的返回,我们可以使用 js 内置的 TextDecoder 对象来读取流式输出 API 的返回内容,并在页面中展示。
数据持久化
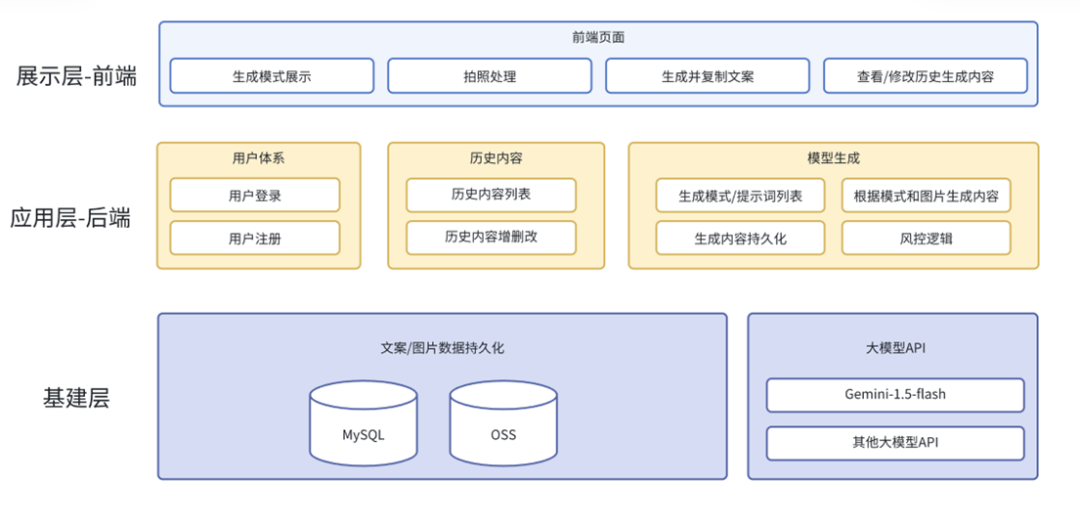
为了能持久化存储图片和生成的文案,我们需要做两件事:
搭建用户体系。
引入存储中间件做模式,提示词,图片和生成文案的持久化。
将我们的架构变成下图的样子:
展望
这是一次对 Gemini API 的简单尝试,生成的文案可以用于各种您需要的场景,甚至生成更加适合营销的文案帮助您实现出海业务增长。随着大模型多模态技术的不断发展,我们身边将涌现了越来越多的多模态应用。借助 AI 技术,我们只需要一点灵感和编程能力,就能解决许多困扰我们的问题。而在未来,也一定会有更多的 AI 应用,在各个领域掀起变革,为我们带来不一样的体验。
写在最后
感谢 ZY 的创作分享,希望这次的案例可以为您借助 Gemini 特性开发作品提供灵感。如果您也有自己的实践案例,欢迎您报名谷歌开发者招募活动并投稿作品,展示您对前沿技术的洞察,收获灵感和惊喜!

扫描二维码提交报名
和伙伴们一起探索 Google 技术
 点击屏末 | 阅读原文 | 即刻报名谷歌开发者招募活动
点击屏末 | 阅读原文 | 即刻报名谷歌开发者招募活动




















 9
9

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









