







C语言是有类型的语言
C语言的变量,必须:
在使用前定义,并且确定类型。
C以后的语言想两个方向发展;
1.C++/Java更强调类型,对类型的检查更严格
2.JavaScirpt、Python、PHP不看中类型,甚至不需要事先定义
类型安全
支持强类型的观点认为明确的类型有助于尽早发现程序中的简单错误
反对强类型的观点认为过于强调类型迫使程序员面对底层、实现而非事物逻辑
总的说,早期语言强调类型,面向底层的语言强调类型
C语言的类型
整数
char、short、int、long、long long
浮点数
float、double、long double
逻辑
bool
指针
自定义类型
(蓝色为C99的类型)
类型有何不同
1.类型名称:int、long、double
2.输入输出时的格式化%d 、%ld、%lf
3.所表达的数的范围:char<short<int<float<double
4.内存中所占据的大小:1个字节道16个字节
5.内存中的表达形式:二进制数(补码)、编码
sizeof
是一个运算符,给出某个类型或变量在内存中所占据的字节数
是静态运算符,它的结果在编译时刻就决定了
不要再sizeof的口号里做运算,这些运算不会做的
整数
char:1字节(8比特)
short:2字节
int:取决于编译器(CPU),通常的意义是“1个字节”
long:取决于编译器(CPU),通常的意义是“1个字”
long long:8字节
二进制负数
1个字节可以表达的数;
00000000-11111111(0-255)
三种方案:
1.仿照十进制,有一个特殊的标志表示负数
2.取中间的数为0,如10000000表示0,比它小的是负数,比它大的是正数
3.补码
补码
考虑-1,我们希望-1+1——>0。如何做到?
0——>00000000
1——>00000001
11111111+00000001——>100000000
(1)00000000-00000001——>11111111
11111111被当做纯二进制看待时,是255,被当作补码看待时是-1
同理,对于-a,其补码就是0-a,实际是2^n-a,n是这种类型的位数
补码的意义就是拿补码和原码可以加出一个溢出的“零”
数的范围
对于一个字节(8位),可以表达的是:
00000000-11111111
其中
00000000——>0
11111111~10000000——>-1~-128
00000001~01111111——>1~127


unsigned
如果一个字面量常熟想要表达自己是unsigned,可以在后面加u或U
255U
用I或L表示long(long)
*unsigned的初衷并非扩展数能表达的范围,而是为了做二进制运算,主要是为了移位
(这个整数不以补码方式来表达,没有负数,只有零和正整数;负作用,使正数范围扩大一倍)
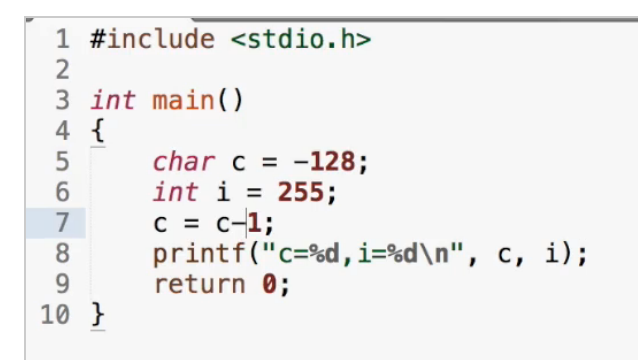
整数越界
整数是以纯二进制方式进行计算的,所以:
11111111+1——>100000000——>0
01111111+1——>10000000——>-128
10000000-1——>01111111——>127


整数的输入输出
只有两种形式:int或long long
%d:int
%u:unsigned
%ld:long long
%lu:unsigned long long
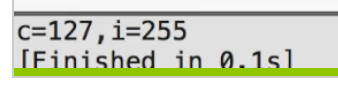
八进制和十六进制
一个以0开始的数字字面量是8进制
一个以0x开始的数字字面量是16进制
%o用于8进制,%x用于16进制
(8进制和16进制只是如何把数字表达为字符串,与内部如何表达数字无关)

*8进制和16进制
16进制很适合表达二进制数据,因为4位二进制正好是一个16进制位
8进制的一位数字正好表达3位二进制
因为早期计算机的字长是12的倍数,而非8
选择整数类型:
没什么特殊需要就只用int就好了
浮点类型


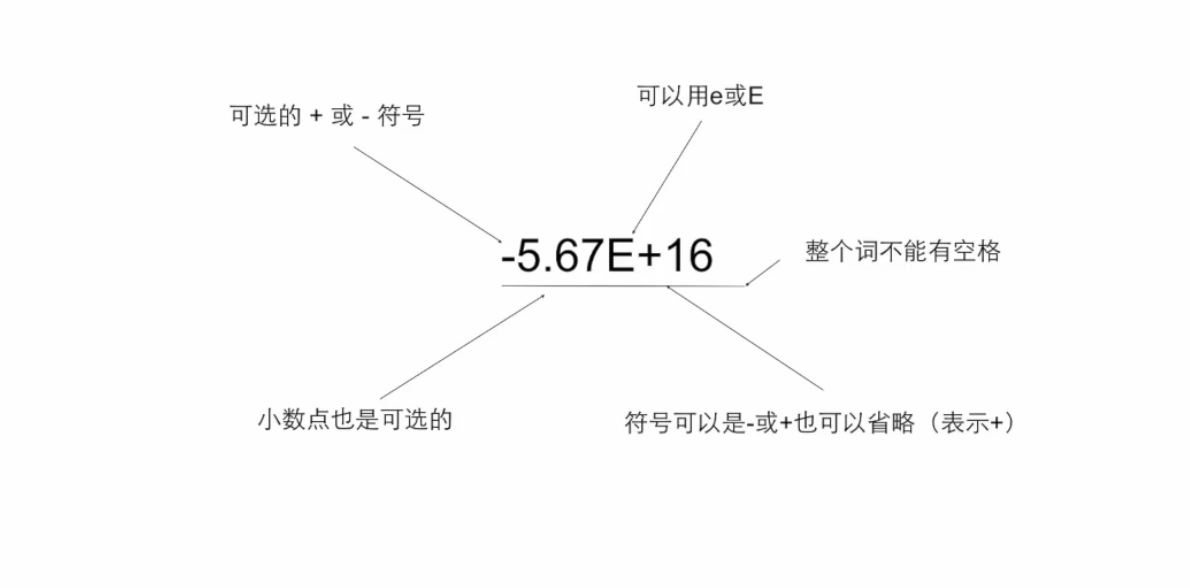
科学计数法
输出精度

超过范围的浮点数



选择浮点类型

char是整数也是字符
(character)
char是一种整数,也是一种特殊的类型:字符。这是因为:
用单引号表示的字符字面量:`a`,`1`
``也是一个字符
printf和scanf里用%c来输入输出字符
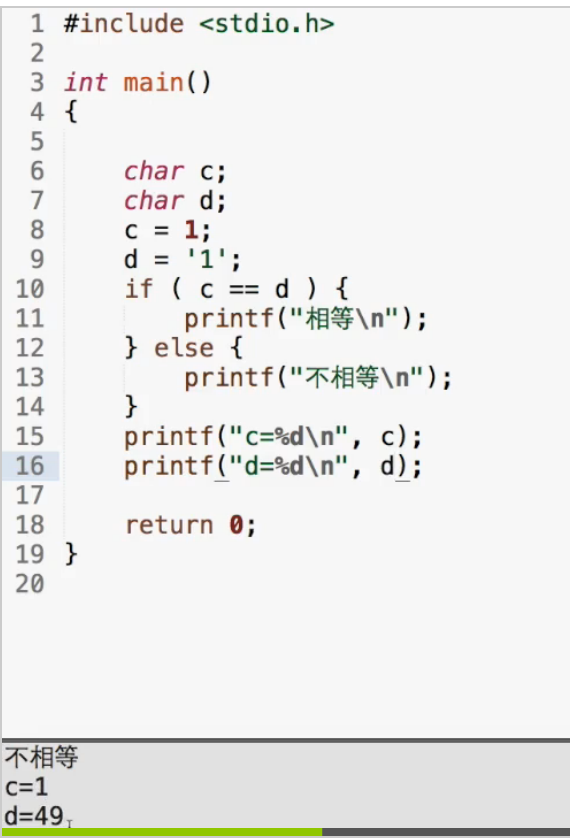 `1`是一个字符
`1`是一个字符



混合输入

%后不带空格,就是只读到整数后面为止,后面那个给下一位
如果有空格,程序会把空格都读完,无论后面几个空格,然后在继续下一位
字符计算
 结果是 B
结果是 B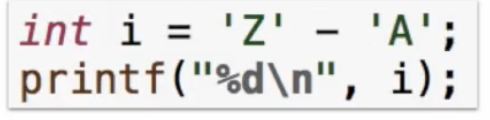 结果是 25
结果是 25
大小写转换

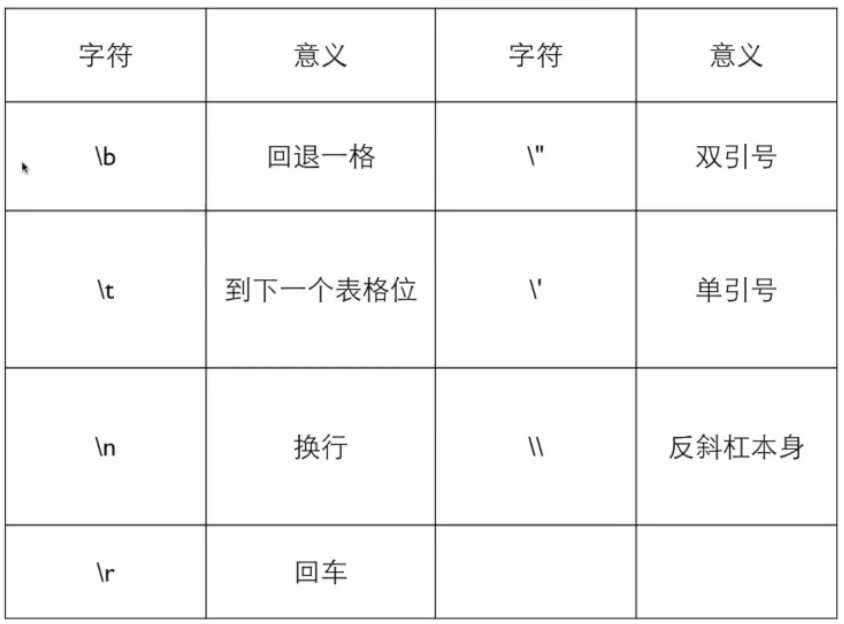
逃逸字符


自动类型转换





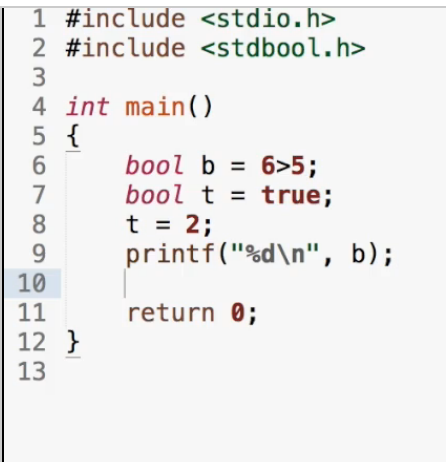
bool类型
#include<stdbool.h>
之后就可以使用bool和ture、false
逻辑运算
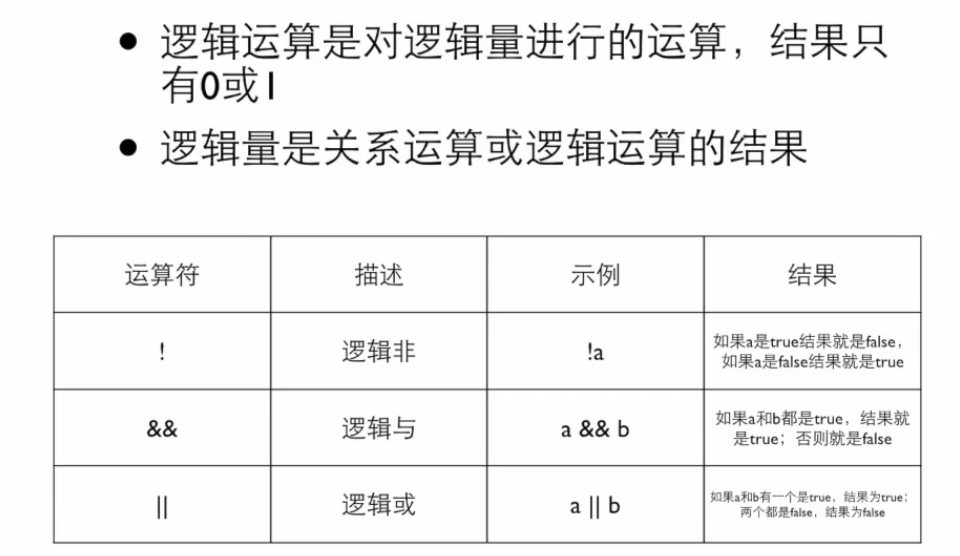
TRY(区间)



优先级
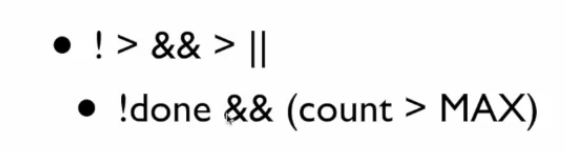

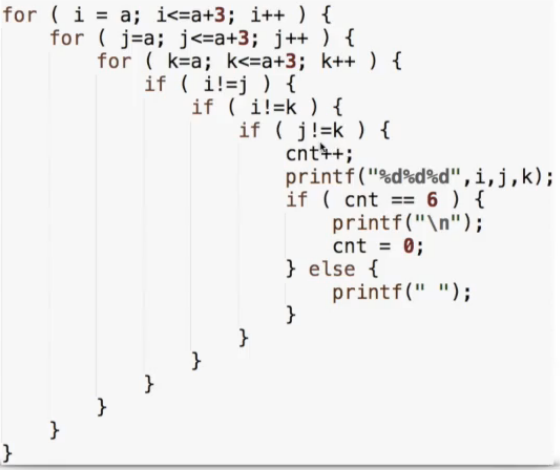
改写成

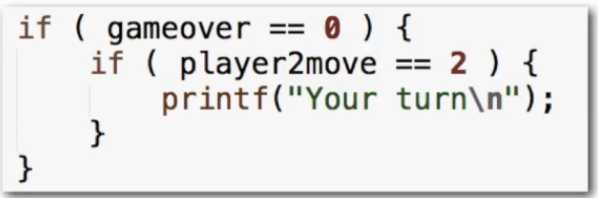
改写

短路

 不要把赋值包括复合赋值组合进表达式。
不要把赋值包括复合赋值组合进表达式。条件运算符


嵌套条件表达式

最好不好用,程序不好理解。
逗号运算

主要在for中使用
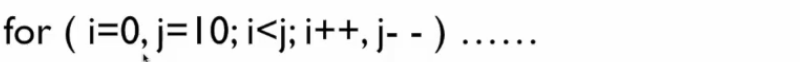















 198
198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









