







Oracle数据库里的统计信息是这样的一组数据:它存储在数据字典里,且从多个维度描述了Oracle数据库里对象的详细信息。CBO会利用这些统计信息来计算目标SQL各种可能的、不同的执行路径的成本,并从中选择一条成本值最小的执行路径来作为目标SQL的执行计划。
Oracle数据库里的统计信息可以分为如下6种类型:
-
表的统计信息
-
索引的统计信息
-
列的统计信息
-
系统统计信息
-
数据字典统计信息
-
内部对象统计信息
表的统计信息用于描述Oracle数据库里表的详细信息,它包含了一些典型的维度,如记录数、表块(表里的数据块)数量、平均行长度等。
索引的统计信息于描述Oracle数据库里索引的详细信息,它包含了一些典型的维度,如索引的层级、叶子块的数量、聚簇因子等。
列的统计信息于描述Oracle数据库里列的详细信息,它包含了一些典型的维度,如列的distinct值的数量、列的NULL值的数量、列的最小值、列的最大值以及直方图等。
系统统计信息于描述Oracle数据库所在的数据库服务器的系统处理能力,它包含了CPU和I/O这两个维度,借助于系统统计信息,Oracle可以更清楚地知道目标数据库服务器的实际处理能力。
数据字典统计信息用于热核Oracle数据库里数据字典基表(如TAB$、IND$等)、数据字典基表上的索引,以及这些数据字典的列的详细信息,描述上述数据字典基表的统计信息与描述普通表、索引、列的统计信息没有本质区别。
内部对象统计信息用于描述Oracle数据库里的一些内部表(如X$系列表)的详细信息,它的维度和普通表的统计信息的维度类似,只不过其表块的数量为0,因为X$系统表实际上只是Oracle自定义的内存结构,并不占用实际的物理存储空间。
1、收集统计信息
在Oracle数据库里,通常有两种方法可以用来收集统计信息:一种是使用ANALYZE命令;另一种是使用DBMS_STATS包。表、索引、列的统计信息和数据字典统计信息用ANALYZE命令或者DBMS_STATS包收集均可,但系统统计信息和系统内部对象统计信息只能使用DBMS_STATS包来收集。
对系统内部表若使用ANALYZE命令来收集统计信息,会报错ORA-02030
1.1 用ANALYZE命令收集统计信息
从Oracle7开始,ANALYZE命令就可以用来收集表、索引、列的统计信息,以及系统统计信息。
典型用法如下:
zx@ORCL>create table t2 as select * from dba_objects;
Table created.
zx@ORCL>create index idx_t2 on t2(object_id);
Index created.
zx@ORCL>analyze index idx_t2 delete statistics;
Index analyzed.从Oracle 10g开始,创建索引后Oracle会怎么收集目标索引的统计信息,出现演示的目的,这里删除索引IDX_T2的统计信息:
执行sosi脚本,从输出内容可以看到表T2、表T2的列和索引IDX_T2均没有相关的统计信息
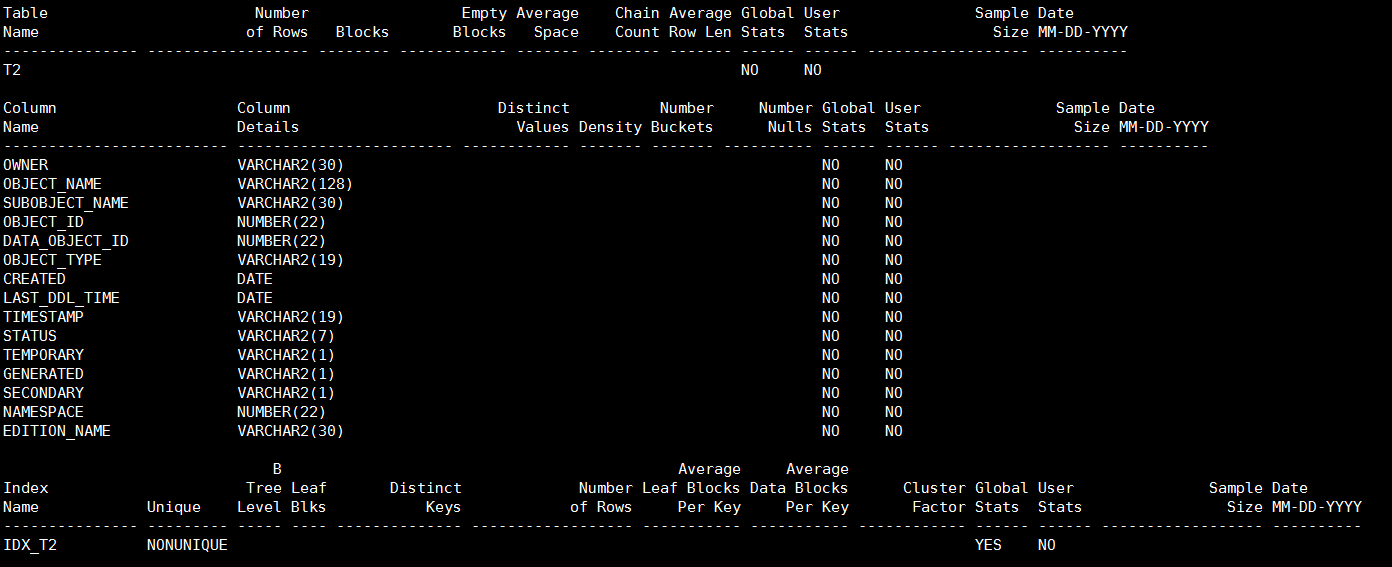
zx@ORCL>select count(*) from t2;
COUNT(*)
----------
86852只对表T2收集统计信息,并且以估算模式,采样的比例为15%:
zx@ORCL>analyze table t2 estimate statistics sample 15 percent for table;
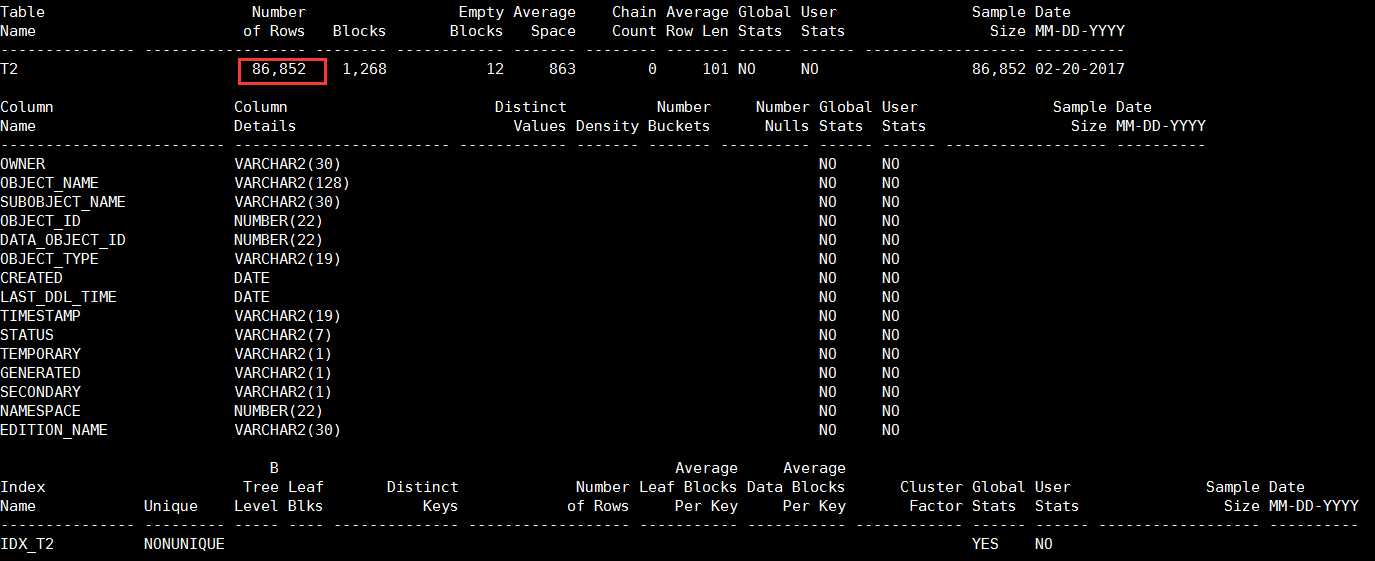
Table analyzed.再次执行sosi脚本,可以看出现在只用表T2有统计信息,表T2的列和索引IDX_T2均没有相关的统计信息。而且因为采用的是估算模式所以估算结果和实际结果并不一定会完全匹配,比如表T2的实际数量与估算出的数量不一致。

只对表T2收集统计信息,并且以计算模式:
zx@ORCL>analyze table t2 compute statistics for table;
Table analyzed.再次执行sosi脚本,可以看出现在只用表T2有统计信息,表T2的列和索引IDX_T2均没有相关的统计信息。而且因为采用的是计算模式,计算模式会扫描目标对象的所有数据,所以统计结果和实际结果是匹配的。
对表T2收集完统计信息后,现在对表T2的列OBJECT_NAME和OBJECT_ID以计算模式收集统计信息:
zx@ORCL>analyze table t2 compute statistics for columns object_name,object_id;
Table analyzed.再次执行sosi脚本,可以看出,现在列OBJECT_NAME和OBJECT_ID确实已经有统计信息了
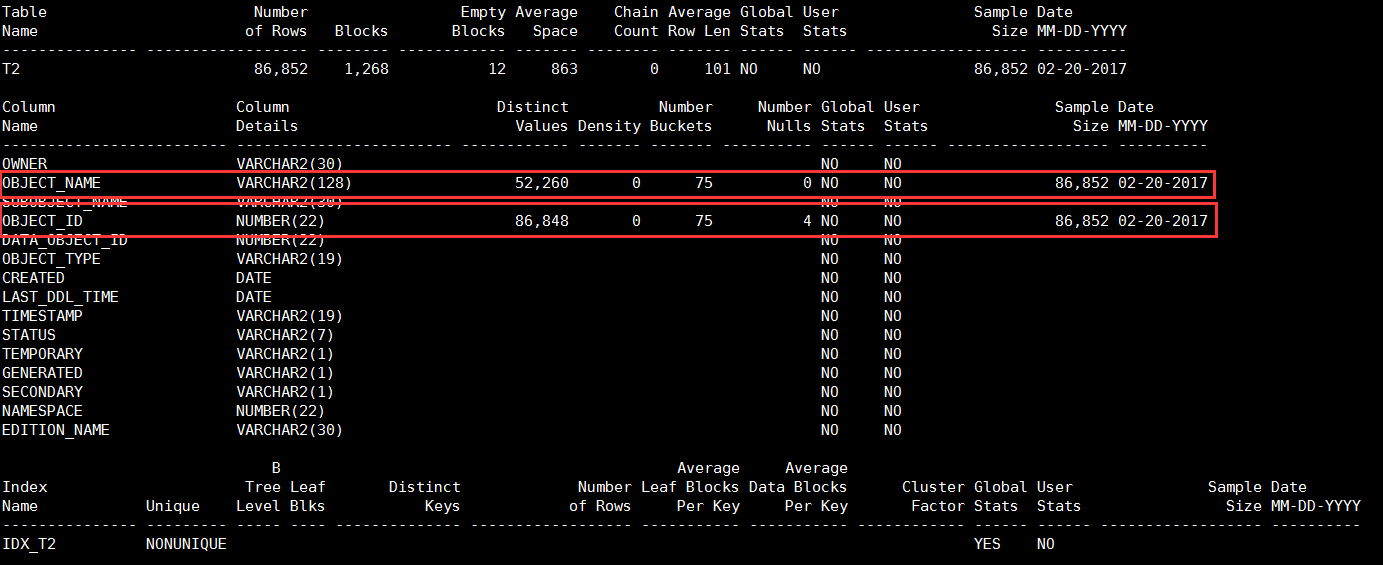
注:在崔华老师的《基于Oracle的SQL优化》一书中提到T2原有的统计信息已经被抹掉了,也就是说对同一个对象而言,新执行的ANALYZE命令会抹掉之前ANALYZE的结果。但是在我实际的执行结果是表T2原有的统计信息没有被抹掉。我用到的环境是10.2.0.4和11.2.0.4,暂时没有11.2.0.1的环境。
可以使用如下的命令同时以计算模式对表T2和列OBJECT_NAME、OBJECT_ID收集统计信息:
zx@ORCL>analyze table t2 compute statistics for table for columns object_name,object_id;
Table analyzed.再次执行sosi脚本,可以看到表T2和列OBJECT_NAME、OBJECT_ID上都有统计信息了。
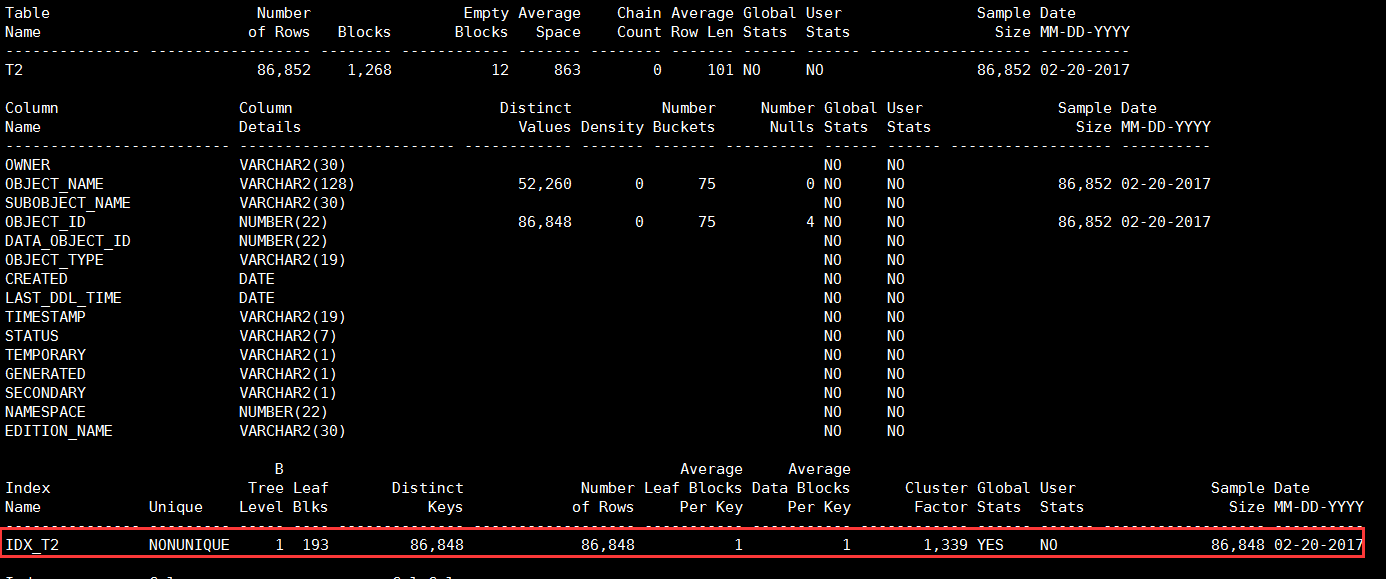
使用如下命令可以以计算模式收集索引IDX_T2的统计信息
zx@ORCL>analyze index idx_t2 compute statistics;
Index analyzed.再次执行sosi脚本,从输出可以看到,现在索引IDX_T2已经有了统计信息,并且之前收集的表T2和列OBJECT_NAME、OBJECT_ID上的统计信息并没有被抹掉,这是因为我们刚才执行的ANALYZE命令和之前执行的ANALYZE命令针对的不是同一个对象。
使用如下命令可以删除表T2、表T2的所有列及表T2的所有索引的统计信息:
zx@ORCL>analyze table t2 delete statistics;
Table analyzed.再次执行sosi脚本,从输出可以看到,刚才收集的表T2、表T2的列OBJECT_NAME、OBJECT_ID以及索引IDX_T2的统计信息已经全部被删除了。
如果想一次性以计算模式收集表T2、表T2的所有列和表T2上的所有索引的统计信息,执行如下的语句就可以了:
zx@ORCL>analyze table t2 compute statistics;
Table analyzed.再次执行sosi脚本,从输出可以看到,现在表T2、表T2的所有列和索引IDX_T2的统计信息都有了。
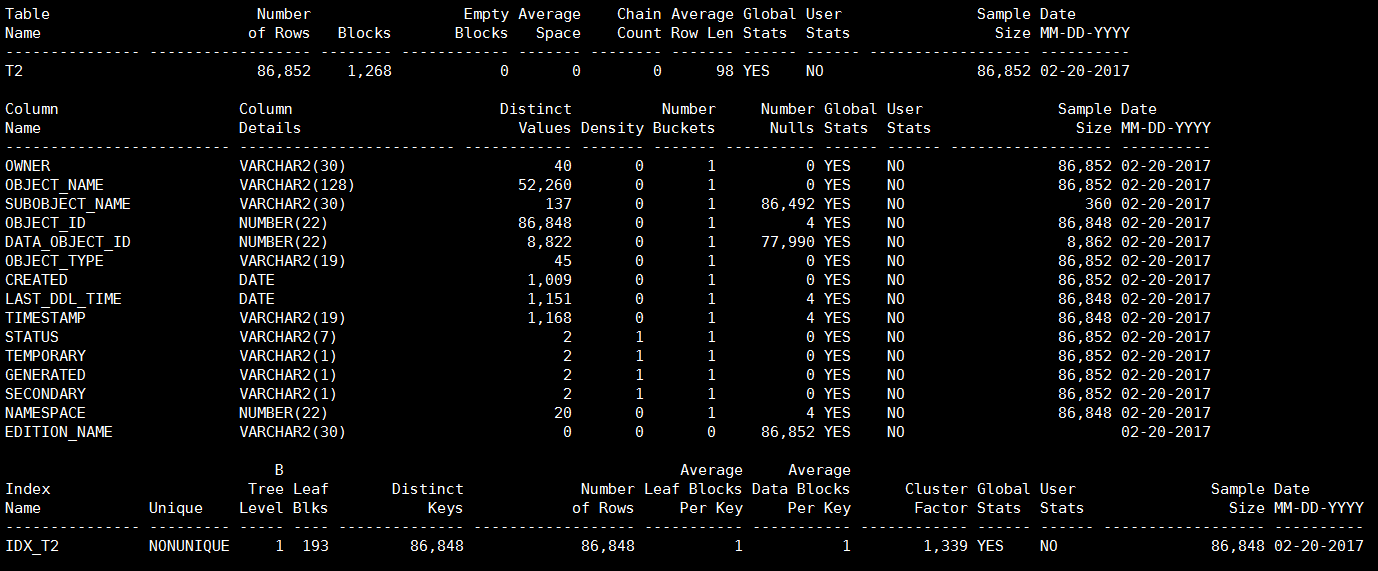
1.2 用DBMS_STATS包收集统计信息
从Oracle 8.1.5开始,DBMS_STATS包被广泛用于统计信息的收集,用DMBS_STATS包收集统计信息也是Oracle官方推荐的方式。在收集CBO所需要的统计信息方面,可以简单的将DBMS_STATS包理解成是ANALYZE命令的增加版。
DBMS_STATS包里最常用的就是如下4个存储过程:
-
GATHER_TABLE_STATS:用于收集目标表、目标表的列和目标表上的索引的统计信息。
-
GATHER_INDEX_STATS:用于收集指定索引的统计信息。
-
GATHER_SCHEMA_STATS:用于收集指定schema下所有对象的统计信息。
-
GATHER_DATABASE_STATS:用于收集全库所有对象的统计信息。
现在介绍DBMS_STATS包在收集统计信息时的常见用法,还是针对上面的测试表T2,这里使用DBMS_STATS包实现了和ANALYZE命令一模一样的效果。
先删除表T2上的所有统计信息
analyze table t2 delete statistics;
只对表T2收集统计信息,并且以估算模式,采用的比例同样为15%:
zx@ORCL>exec dbms_stats.gather_table_stats(ownname=>'ZX',tabname=>'T2',estimate_percent=>15,method_opt=>'FOR TABLE',cascade=>false);
PL/SQL procedure successfully completed.执行sosi脚本,从输出内容可以看出,现在只有表T2有统计信息,表T2的列和索引IDX_T2均没有相关的统计信息。而且因为采用的估算模式,所以估算结果和实际结果并不一定会完全匹配。
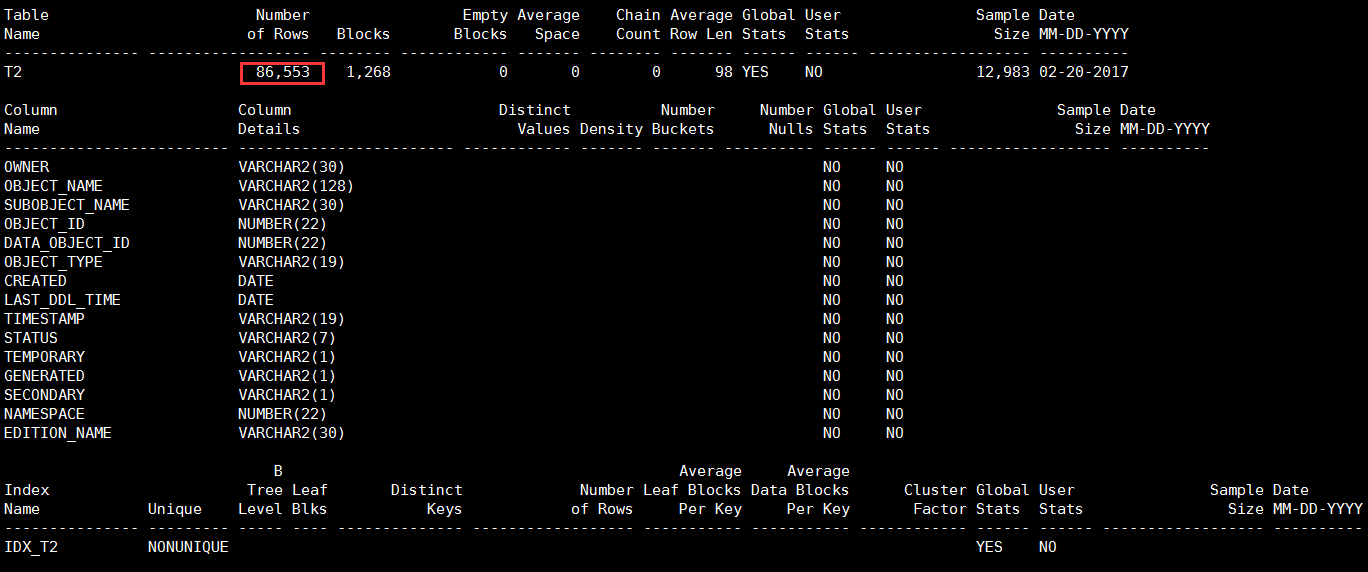
需要注意的是,这里Oracle数据库的版本是11.2.0.4,我们在调用DMBS_STATS.GATHER_TABLE_STATS时指定参数METHOD_OPT的值为'FOR TABLE',这表示只收集表T2的统计信息。这种收集表统计信息的方法并不适用于Oracle数据库所有的版本。例如这种方法就不适用于Oracle10.2.0.4和Oracle10.2.0.5,在这两个版本里,即使指定了'FOR TABLE',Oracle除了收集表统计信息之外还会对所有的列收集统计信息。
如果公对表T2收集统计信息,并且是以计算模式收集,用DBMS_STATS包实现的方法就是将估算模式的采样比例(即参数ESTIMATE_PERCENT)设置为100%或NULL;
exec dbms_stats.gather_table_stats(ownname=>'ZX',tabname=>'T2',estimate_percent=>100,method_opt=>'FOR TABLE',cascade=>false);
exec dbms_stats.gather_table_stats(ownname=>'ZX',tabname=>'T2',estimate_percent=>NULL,method_opt=>'FOR TABLE',cascade=>false);
zx@ORCL>exec dbms_stats.gather_table_stats(ownname=>'ZX',tabname=>'T2',estimate_percent=>100,method_opt=>'FOR TABLE',cascade=>false);
PL/SQL procedure successfully completed.执行sosi脚本,从输出内容可以看出,现在只有表T2的统计信息,表T2的列和索引IDX_T2均没有相关的统计信息。而且因为采用的是计算模式,计算模式会扫描目标对象的所有数据,所以统计结果和实际结果是匹配的。

对表T2收集完统计信息后,现在我们来对表T2的列OBJECT_NAME、OBJECT_ID以计算模式收集统计信息(不收集直方图):
zx@ORCL>exec dbms_stats.gather_table_stats(ownname=>'ZX',tabname=>'T2',estimate_percent=>100,method_opt=>'for columns size 1 object_name,object_id',cascade=>false);
PL/SQL procedure successfully completed.执行sosi脚本,从输出内容可以看出,现在表T2的列OBJECT_NAME、OBJECT_ID上都有统计信息了,并且Oracle还会同时收集表T2上的统计信息(注意,这和ANALYZE命令有所区别)。

使用如下命令可以以计算模式收集索引IDX_T2的统计信息
zx@ORCL>exec dbms_stats.gather_index_stats(ownname=>'ZX',indname=>'IDX_T2',estimate_percent=>100);
PL/SQL procedure successfully completed.执行sosi脚本,从输出内容可以看出,现在索引IDX_T2已经有了统计信息。
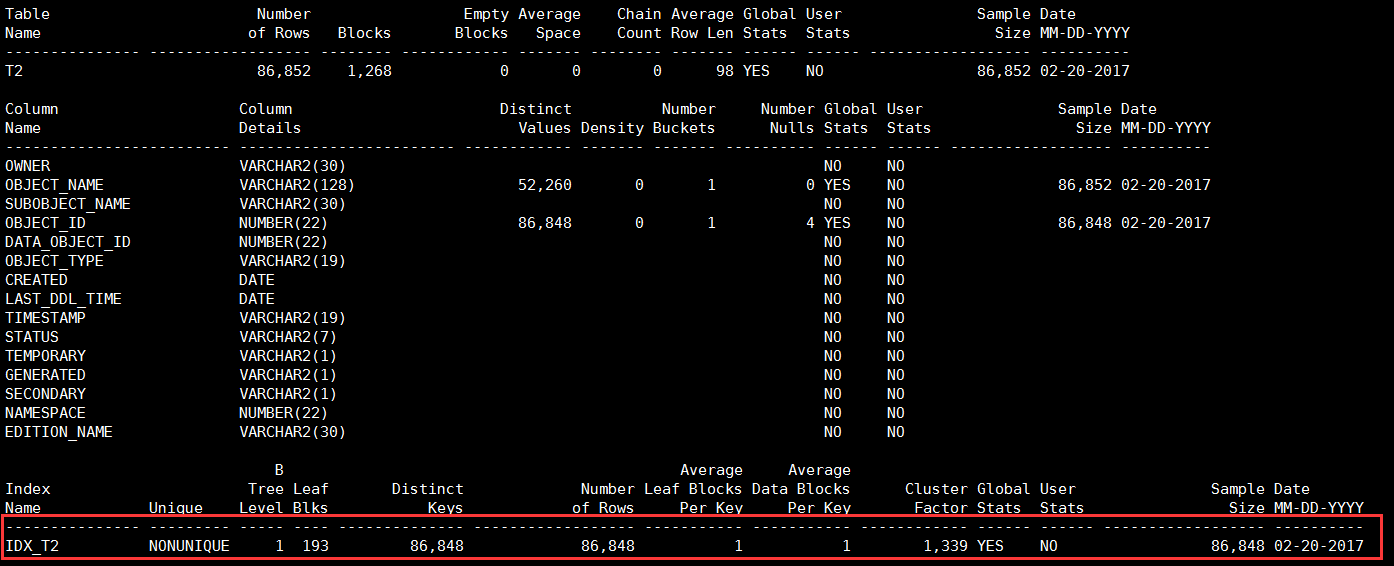
使用如下命令可以删除表T2、表T2的所有列及表T2的所有索引的统计信息:
zx@ORCL>exec dbms_stats.delete_table_stats(ownname=>'ZX',tabname=>'T2');
PL/SQL procedure successfully completed.执行sosi脚本,从输出内容可以看出,表T2、表T2的所有列及表T2的所有索引的统计信息已经全部被删除了。
如果想一次性以计算模式收集表T2、表T2的所有列及表T2的所有索引的统计信息,执行如下语句就可以了
zx@ORCL>exec dbms_stats.gather_table_stats(ownname=>'ZX',tabname=>'T2',estimate_percent=>100,cascade=>true);
PL/SQL procedure successfully completed.
1.3 ANALYZE和DBMS_STATS的区别
从上面的演示中可以看出ANALYZE命令和DBMS_STATS包都可以用来收集表、索引和列的统计信息,看起来它们在收集统计信息方面的效果是一模一样的,为什么Oracle会推荐使用DBMS_STATS包来收集统计信息呢?
因为ANALYZE命令和DMBS_STATS包相比,存在如下缺陷:
ANALYZE命令不能正确地收集分区表的统计信息,而DBMS_STATS包却可以。ANALYZE命令只会收集最低层次对象的统计信息,然后推导和汇总出高一级的统计信息,比如对于有子分区的分区表而言,它只会先收集子分区统计信息,然后再汇总,推导出分区或表级的统计信息。有的统计信息是可以从当前对象的下一级对象进行汇总后得到的,比如表的总行数,可以由各分区的行数相加得到。但有的统计信息则不能从下一级对象得到,比如列上的distinct值数量NUM_DISTINCT以及DESNSITY等。
ANALYZE命令不能并行收集统计信息,而DBMS_STATS包却可以。并行收集统计信息对数据量很大的表表而言,是非常有用的特性。对于数据量很大的表,如果不能并行收集统计信息,则意味着如果想精确地收集目标对象的统计信息,那么耗费的时间可能会非常长,这有可能是不能接受的。在Oracle数据库里,DBMS_STATS包收集统计信息可以并行执行,这在一定程度上缓解了对大表的统计信息收集过长所带来的一系列问题。
DBMS_STATS包的并行收集是通过手工指定输入参数DEGREE来实现的,比如对表T1进行收集统计信息,同时指定并行度为4:
exec dbms_stats.gahter_table_stats(ownname=>'SCOTT',tabname=>'T1',cascade=>true,estimate_percent=>100,degree=>4);当然,DBMS_STATS包也不是完美的,它与ANALYZE命令相比,其缺陷在于DBMS_STATS包只能收集与CBO相关的统计信息,而与CBO无关的一些额外信息,比如行迁移/行链接的数量(CHAIN_CNT)、校验表和索引的结构信息等,DBMS_STATS包就无能为力了。而ANALYZE命令可以用来分析和收集上述额外的信息,比如analyze table xxx list chained rows intoyyy 可以用来分析和收集行迁移/行链接的数量,analyzeindex xxx validate structure可以用来分析索引的结构。
2、查看统计信息
前面介绍了如何收集统计信息,那如何查看这些统计信息呢?Oracle数据库的统计信息会存储在数据字典里,我们只需要去查询相关的数据字典就好了。如果有充裕的时间,现写SQL去查询数据字典里的统计信息也没有什么,但当我们真正碰到有性能问题的SQL时,通常会希望能在第一时间就收集到与目标SQL相关的各种统计信息,以便于在第一时间定位问题所在,这时候写SQL去查询数据字典就已经来不及了,所以我们需要事先准备好通用的查询统计信息的脚本,出问题的时候只需要运行一下脚本,就能在第一时间获取目标对象的所有统计信息了。
sosi脚本(Show Optimizer Statistics Information)就是这样一种脚本,国内的Oracle数据库专家也一直在用这个脚本,它源于MOS上的文章:SCRIPT - Select to show OptimizerStatistics for CBO (文档 ID 31412.1),用法很简单,只需要运行一下sosi脚本,并指定要查看统计信息的表名就可以了。它支持分区表,显示分为三部分,分别是表级别的统计信息,分区级别的统计信息和子分区级别的统计信息。前面做实验用到的也是这个脚本。
附件是sosi脚本可以下载使用。
set echo off
set scan on
set lines 150
set pages 66
set verify off
set feedback off
set termout off
column uservar new_value Table_Owner noprint
select user uservar from dual;
set termout on
column TABLE_NAME heading "Tables owned by &Table_Owner" format a30
select table_name from dba_tables where owner=upper('&Table_Owner') order by 1
/
undefine table_name
undefine owner
prompt
accept owner prompt 'Please enter Name of Table Owner (Null = &Table_Owner): '
accept table_name prompt 'Please enter Table Name to show Statistics for: '
column TABLE_NAME heading "Table|Name" format a15
column PARTITION_NAME heading "Partition|Name" format a15
column SUBPARTITION_NAME heading "SubPartition|Name" format a15
column NUM_ROWS heading "Number|of Rows" format 9,999,999,990
column BLOCKS heading "Blocks" format 999,990
column EMPTY_BLOCKS heading "Empty|Blocks" format 999,999,990
column AVG_SPACE heading "Average|Space" format 9,990
column CHAIN_CNT heading "Chain|Count" format 999,990
column AVG_ROW_LEN heading "Average|Row Len" format 990
column COLUMN_NAME heading "Column|Name" format a25
column NULLABLE heading Null|able format a4
column NUM_DISTINCT heading "Distinct|Values" format 999,999,990
column NUM_NULLS heading "Number|Nulls" format 9,999,990
column NUM_BUCKETS heading "Number|Buckets" format 990
column DENSITY heading "Density" format 990
column INDEX_NAME heading "Index|Name" format a15
column UNIQUENESS heading "Unique" format a9
column BLEV heading "B|Tree|Level" format 90
column LEAF_BLOCKS heading "Leaf|Blks" format 990
column DISTINCT_KEYS heading "Distinct|Keys" format 9,999,999,990
column AVG_LEAF_BLOCKS_PER_KEY heading "Average|Leaf Blocks|Per Key" format 99,990
column AVG_DATA_BLOCKS_PER_KEY heading "Average|Data Blocks|Per Key" format 99,990
column CLUSTERING_FACTOR heading "Cluster|Factor" format 999,999,990
column COLUMN_POSITION heading "Col|Pos" format 990
column col heading "Column|Details" format a24
column COLUMN_LENGTH heading "Col|Len" format 9,990
column GLOBAL_STATS heading "Global|Stats" format a6
column USER_STATS heading "User|Stats" format a6
column SAMPLE_SIZE heading "Sample|Size" format 9,999,999,990
column to_char(t.last_analyzed,'MM-DD-YYYY') heading "Date|MM-DD-YYYY" format a10
prompt
prompt ***********
prompt Table Level
prompt ***********
prompt
select
TABLE_NAME,
NUM_ROWS,
BLOCKS,
EMPTY_BLOCKS,
AVG_SPACE,
CHAIN_CNT,
AVG_ROW_LEN,
GLOBAL_STATS,
USER_STATS,
SAMPLE_SIZE,
to_char(t.last_analyzed,'MM-DD-YYYY')
from dba_tables t
where
owner = upper(nvl('&&Owner',user))
and table_name = upper('&&Table_name')
/
select
COLUMN_NAME,
decode(t.DATA_TYPE,
'NUMBER',t.DATA_TYPE||'('||
decode(t.DATA_PRECISION,
null,t.DATA_LENGTH||')',
t.DATA_PRECISION||','||t.DATA_SCALE||')'),
'DATE',t.DATA_TYPE,
'LONG',t.DATA_TYPE,
'LONG RAW',t.DATA_TYPE,
'ROWID',t.DATA_TYPE,
'MLSLABEL',t.DATA_TYPE,
t.DATA_TYPE||'('||t.DATA_LENGTH||')') ||' '||
decode(t.nullable,
'N','NOT NULL',
'n','NOT NULL',
NULL) col,
NUM_DISTINCT,
DENSITY,
NUM_BUCKETS,
NUM_NULLS,
GLOBAL_STATS,
USER_STATS,
SAMPLE_SIZE,
to_char(t.last_analyzed,'MM-DD-YYYY')
from dba_tab_columns t
where
table_name = upper('&Table_name')
and owner = upper(nvl('&Owner',user))
/
select
INDEX_NAME,
UNIQUENESS,
BLEVEL BLev,
LEAF_BLOCKS,
DISTINCT_KEYS,
NUM_ROWS,
AVG_LEAF_BLOCKS_PER_KEY,
AVG_DATA_BLOCKS_PER_KEY,
CLUSTERING_FACTOR,
GLOBAL_STATS,
USER_STATS,
SAMPLE_SIZE,
to_char(t.last_analyzed,'MM-DD-YYYY')
from
dba_indexes t
where
table_name = upper('&Table_name')
and table_owner = upper(nvl('&Owner',user))
/
break on index_name
select
i.INDEX_NAME,
i.COLUMN_NAME,
i.COLUMN_POSITION,
decode(t.DATA_TYPE,
'NUMBER',t.DATA_TYPE||'('||
decode(t.DATA_PRECISION,
null,t.DATA_LENGTH||')',
t.DATA_PRECISION||','||t.DATA_SCALE||')'),
'DATE',t.DATA_TYPE,
'LONG',t.DATA_TYPE,
'LONG RAW',t.DATA_TYPE,
'ROWID',t.DATA_TYPE,
'MLSLABEL',t.DATA_TYPE,
t.DATA_TYPE||'('||t.DATA_LENGTH||')') ||' '||
decode(t.nullable,
'N','NOT NULL',
'n','NOT NULL',
NULL) col
from
dba_ind_columns i,
dba_tab_columns t
where
i.table_name = upper('&Table_name')
and owner = upper(nvl('&Owner',user))
and i.table_name = t.table_name
and i.column_name = t.column_name
order by index_name,column_position
/
prompt
prompt ***************
prompt Partition Level
prompt ***************
select
PARTITION_NAME,
NUM_ROWS,
BLOCKS,
EMPTY_BLOCKS,
AVG_SPACE,
CHAIN_CNT,
AVG_ROW_LEN,
GLOBAL_STATS,
USER_STATS,
SAMPLE_SIZE,
to_char(t.last_analyzed,'MM-DD-YYYY')
from
dba_tab_partitions t
where
table_owner = upper(nvl('&&Owner',user))
and table_name = upper('&&Table_name')
order by partition_position
/
break on partition_name
select
PARTITION_NAME,
COLUMN_NAME,
NUM_DISTINCT,
DENSITY,
NUM_BUCKETS,
NUM_NULLS,
GLOBAL_STATS,
USER_STATS,
SAMPLE_SIZE,
to_char(t.last_analyzed,'MM-DD-YYYY')
from
dba_PART_COL_STATISTICS t
where
table_name = upper('&Table_name')
and owner = upper(nvl('&Owner',user))
/
break on partition_name
select
t.INDEX_NAME,
t.PARTITION_NAME,
t.BLEVEL BLev,
t.LEAF_BLOCKS,
t.DISTINCT_KEYS,
t.NUM_ROWS,
t.AVG_LEAF_BLOCKS_PER_KEY,
t.AVG_DATA_BLOCKS_PER_KEY,
t.CLUSTERING_FACTOR,
t.GLOBAL_STATS,
t.USER_STATS,
t.SAMPLE_SIZE,
to_char(t.last_analyzed,'MM-DD-YYYY')
from
dba_ind_partitions t,
dba_indexes i
where
i.table_name = upper('&Table_name')
and i.table_owner = upper(nvl('&Owner',user))
and i.owner = t.index_owner
and i.index_name=t.index_name
/
prompt
prompt ***************
prompt SubPartition Level
prompt ***************
select
PARTITION_NAME,
SUBPARTITION_NAME,
NUM_ROWS,
BLOCKS,
EMPTY_BLOCKS,
AVG_SPACE,
CHAIN_CNT,
AVG_ROW_LEN,
GLOBAL_STATS,
USER_STATS,
SAMPLE_SIZE,
to_char(t.last_analyzed,'MM-DD-YYYY')
from
dba_tab_subpartitions t
where
table_owner = upper(nvl('&&Owner',user))
and table_name = upper('&&Table_name')
order by SUBPARTITION_POSITION
/
break on partition_name
select
p.PARTITION_NAME,
t.SUBPARTITION_NAME,
t.COLUMN_NAME,
t.NUM_DISTINCT,
t.DENSITY,
t.NUM_BUCKETS,
t.NUM_NULLS,
t.GLOBAL_STATS,
t.USER_STATS,
t.SAMPLE_SIZE,
to_char(t.last_analyzed,'MM-DD-YYYY')
from
dba_SUBPART_COL_STATISTICS t,
dba_tab_subpartitions p
where
t.table_name = upper('&Table_name')
and t.owner = upper(nvl('&Owner',user))
and t.subpartition_name = p.subpartition_name
and t.owner = p.table_owner
and t.table_name=p.table_name
/
break on partition_name
select
t.INDEX_NAME,
t.PARTITION_NAME,
t.SUBPARTITION_NAME,
t.BLEVEL BLev,
t.LEAF_BLOCKS,
t.DISTINCT_KEYS,
t.NUM_ROWS,
t.AVG_LEAF_BLOCKS_PER_KEY,
t.AVG_DATA_BLOCKS_PER_KEY,
t.CLUSTERING_FACTOR,
t.GLOBAL_STATS,
t.USER_STATS,
t.SAMPLE_SIZE,
to_char(t.last_analyzed,'MM-DD-YYYY')
from
dba_ind_subpartitions t,
dba_indexes i
where
i.table_name = upper('&Table_name')
and i.table_owner = upper(nvl('&Owner',user))
and i.owner = t.index_owner
and i.index_name=t.index_name
/
clear breaks
set echo on
参考《基于Oracle的SQL优化》

















 332
332

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









