






applymap用于DataFrame中的元素级别,就是对所有元素应用某个方法;apply用于Series或DataFrame的列。比如:
applymap():
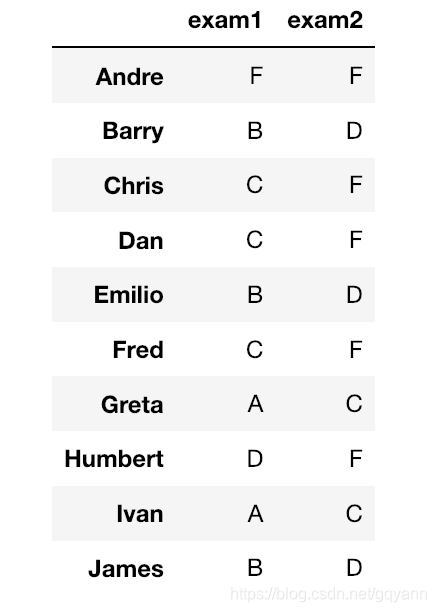
# 成绩转换为字母表示
grades_df = pd.DataFrame(
data={'exam1': [43, 81, 78, 75, 89, 70, 91, 65, 98, 87],
'exam2': [24, 63, 56, 56, 67, 51, 79, 46, 72, 60]},
index=['Andre', 'Barry', 'Chris', 'Dan', 'Emilio',
'Fred', 'Greta', 'Humbert', 'Ivan', 'James']
)
# 先写出一个对单个元素转换的方法
def convert_grades(grade):
'''
Fill in this function to convert the given DataFrame of numerical
grades to letter grades. Return a new DataFrame with the converted
grade.
The conversion rule is:
90-100 -> A
80-89 -> B
70-79 -> C
60-69 -> D
0-59 -> F
'''
if grade >= 90:
return 'A'
elif grade >= 80:
return 'B'
elif grade >= 70:
return 'C'
elif grade >= 60:
return 'D'
else:
return 'F'
def convert(grades):
return grades.applymap(convert_grades)
convert(grades_df)
 apply:
apply:
这是针对DataFrame中的列,也就是Series
ex1
grades_df = pd.DataFrame(
data={'exam1': [43, 81, 78, 75, 89, 70, 91, 65, 98, 87],
'exam2': [24, 63, 56, 56, 67, 51, 79, 46, 72, 60]},
index=['Andre', 'Barry', 'Chris', 'Dan', 'Emilio',
'Fred', 'Greta', 'Humbert', 'Ivan', 'James']
)
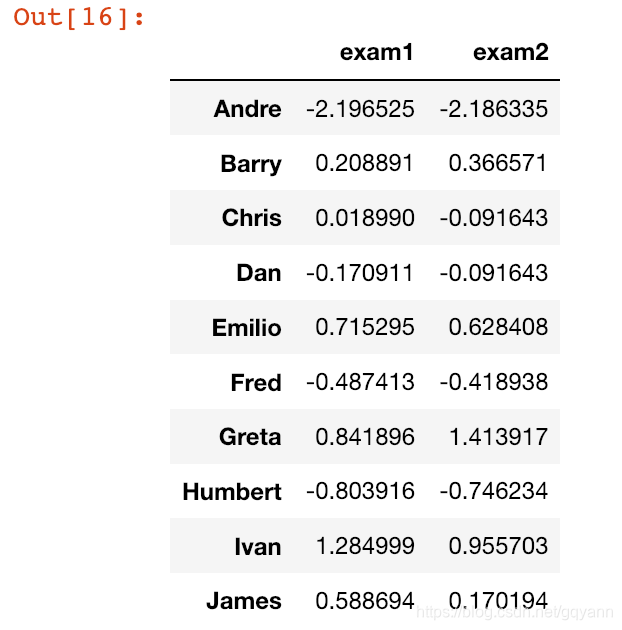
def standardize_column(column):
return (column - column.mean()) / column.std()
def standardize(df):
'''
Fill in this function to standardize each column of the given
DataFrame. To standardize a variable, convert each value to the
number of standard deviations it is above or below the mean.
'''
return df.apply(standardize_column)
standardize(grades_df)
 ex2
ex2
df = pd.DataFrame({
'a': [4, 5, 3, 1, 2],
'b': [20, 10, 40, 50, 30],
'c': [25, 20, 5, 15, 10]
})
def second_largest_column(column):
sorted_column = column.sort_values(ascending=False)
return sorted_column.iloc[1]
def second_largest(df):
'''
Fill in this function to return the second-largest value of each
column of the input DataFrame.
'''
return df.apply(second_largest_column)
second_largest(df)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









