







| 网页右边,向下滑有目录索引,可以根据标题跳转到你想看的内容 |
|---|
| 如果右边没有就找找左边 |
一、概述
- jvm是什么,jvm是一种规范,它虚构出来一台计算机,实习了字节码指令集,并对内存进行管理(堆,栈,方法区等等)
- jvm和java无关,因为任何语言只要编译成.class字节码文件或者在执行过程中产生class二进制流文件都可以被JVM执行

为什么说java是跨平台语言,JVM是跨语言平台
- 首先因为有java虚拟机(JVM)的存在,我们只需要写一份代码并编译成class字节码文件,然后在windows系统安装对应版本的JVM,Linux上安装对应版本的JVM,实现相同class字节码文件在不同系统执行,实现了跨平台(只要在不同系统根据同一种规范,写出不同系统不同实现的虚拟机即可)
- 而JVM不仅仅可以支持java语言,它还可以执行scala,kotlin,groovy等100多种语言
常见的JVM实现(不同厂家可以实现更适合自己的JVM,而我们使用的一般都是Hotspot版本,就是oracle官方实现的,我们做实验学习用的JVM虚拟机)

- java从编译到执行的流程,首先
我们编写.java文件,就是平常我们写的java代码文件,然后通过javac命令将java文件编译为.class的字节码文件,最后将编译好的文件给java虚拟机(JVM)即可- JVM在流程中做什么事,首先
通过ClassLoader(类加载器)将class文件打包扔到内存中,包括这个文件使用到的类库,比如使用List集合时引入的java.util.ArrayList包等,然后因为java是半解释半编译语言,所以通过解释器和编译器对打包好的文件进行解释编译,最后将解释编译好的文件交给执行引擎,引擎去和操作系统和硬件交涉

JDK & JRE & JVM之间的关系
jvm
只是来执行class文件的,JRE是运行时环境,除了包含JVM还包含有核心类库,因为仅仅将class文件给JVM无法直接执行,这些文件还依赖与一些核心类库,JDK是最重要的,我们不安装JDK是没有办法使用java的,它包含JRE,并且包含我们开发使用的类库

二、类加载
| 查看class文件 |
|---|
| 请参考文章:如何使用IDEA查看class文件 |
- class文件由二进制构成
- 数据类型有u1、u2、u4、u8 和 _info(表类型,源自于hotspot(oracle官方JVM)源码中的写法)
- 可以以16进制查看class文件的软件有sublim、notepad,还有IDEA的BinEd插件也可以
- 观察ByteCode的方法,javap、KBE(可以直接修改)、jclasslib(IDEA插件)
1、类加载器(加载过程->初始化)
| 类加载与实例化区别 |
|---|
| 类加载,是将一个类加载到内存,并对类中静态变量初始化,因为静态变量是不需要实例化的 |
| 实例化,通过加载到内存的类,进行实例化,获取实例化对象 |
类加载过程
- loading(加载):将一个class文件加载到内存(此时生成了两个内存,一个是class文件的二进制放在内存中,然后生成一个class对象,此对象指向存放class文件二进制的内存地址)
- linking(连接):和内存地址连接
- verification(校验):校验加载的class文件是否复合文件标准
- preparation(准备):为文件中的静态变量赋默认值(
注意是赋默认值,比如一个static int i = 8 此时不是直接等于8,而是赋默认值)- resolution(解析):将
符号引用解析成内存地址也就是直接引用(在class文件,我们会发现常量池中有类似Object的常量,而我们通过特定的指令引用这些常量,这叫符号引用,但是这个常量在内存中的位置又是不同的,无法直接通过指令直接找到内存中常量的位置,而这一步骤就是让符号引用直接变成内存地址引用)
- initializing(初始化):为文件静态变量赋初始值(此时才真正给静态变量根据编程时指定的值赋值)
类加载器
- JVM按需加载,首先Bootstrap加载核心类,如果想要获取Bootstrap Loader(启动类加载器),因为是c语言实现,所以找不到具体java返回值,获取的会是一个null值.此加载器主要加载System.getProperty(“sun.boot.class.path”)所指定的路径或jar
- Extended Loader(标准扩展类加载器ExtClassLoader):加载System.getProperty(“java.ext.dirs”)所指定的路径或jar,是一些扩展的jar包
- AppClass Loader(系统类加载器AppClassLoader):加载System.getProperty(“java.class.path”)所指定的路径或jar,比如我们自己写的类,就用这个加载器加载
- CustomClassLoader加载器的父加载器(注意是父亲,不是继承关系,不要混淆)是APP,APP父加载器是Extension,Extension父加载器是Bootstrap,Bootstrap父加载器是null
双亲委派(由子到父,再由父到子的过程叫双亲委派)
首先一个class文件,会通过自定义加载器在
缓存中去找有没有加载过此class,如果有返回结果(告诉程序,当前加载器缓存中加载过这个类,不用重复加载了),没有委派给父亲的缓存找,依次类推直到Bootstrap加载器(具体如下图),本步骤并不会真正加载,只是查一下有没有加载过
如果上面连Bootstrap加载器的缓存都没有,就会往回委派,交给Ext加载器,让此加载器去
加载(此时不是到缓存中找了,而是尝试加载),如果加载成功返回结果并加入缓存(下次加载就能在缓存中找到了),不成功继续委派给儿子,依次类推直到最小的Custom自定义加载器,如果还是不能加载,就会报错
双亲委派的意义
(就是为了安全(主要)和效率(次要))假如有
一个用户自己定义一个java.lang.String的类,没有双亲委派的话,比如在自定义加载器就找到了相应的加载器,直接将其加载了,那么,此时,就会覆盖掉内存中原本java原生的String类。此时程序中但凡使用String类,都会使用用户定义的这个String类,比如这个类中,会将每一个String都写到一个邮件中,发给作者,那么银行卡还能安全么?但是有了双亲委派,
先到自定义加载器缓存中找,没加载过,找父亲,一般程序都会使用String,那么找到Ext或者Bootstrap加载器的缓存时,就应该会找到了,此时就会返回结果,已经加载过这个类了,不需要重复加载总结:如果已经加载过这个类,那么缓存中一定会找到,如果找到,返回结果,无需重复加载,此为效率的提升。如果有同名类出现,比如String类,也会在缓存中找到,不会重复加载,避免此类覆盖原生JDK的String类,此为安全性的体现。
父加载器
父加载器
不是类加载器的加载器也不是类加载器的父类加载器.而是在一个类加载器源码中,会有一个parent变量,为ClassLoader类型对象,此对象指向的加载器,为当前加载器的父加载器注意看下面的图片输出结果,sun.misc.Launcher是一个类加载器的包装启动类,而$后面跟的是它的内部类,@后面是hash码,由此可见,我们看源码需要到Launcher中看
类加载器范围
根据Launcher的源码可以看到App加载器的加载范围
通过简单代码查看这几个加载器加载哪些类
Bootstrap加载器加载
Ext加载器
App加载器
可见这里倒数第二个是项目路径,倒数第一个是IDEA的都由App加载了,这是在没有自定义加载器的情况下














2、自定义类加载器
什么情况用自定义加载器
- Spring框架中,要帮你生成Class对象时
- Tomcat服务器需要自定义加载器
- 热部署时,如何动态的替换现在内存中的类,需要用到自定义加载器
步骤
- 继承ClassLoader类
- 重写模板方法findClass------》并调用defineClass
- 自定义类加载器加载自加密的class
3.1 防止反编译
3.2 防止篡改如何加载指定类,以及ClassLoader类源码
public static void main(String[] args) throws ClassNotFoundException {
//Test1.class.getClassLoader() 获取加载器,这里明显是App加载器,因为Main是我们自定义的类
//然后我们调用方法loadClass("要加载的类名");此时即可将一个类通过加载器加载了
//所以我们需要查看ClassLoader类中loadClass方法的源码
Class aClass = Test1.class.getClassLoader().loadClass("com.company.Test1");
System.out.println(aClass.getName());//运行结果com.company.Test1,Test1类名
}
源码如下:
接下来,看这个方法内部调用的另一个loadClass方法源码,这是一个重载方法,需要多传一个参数,如果没有找到加载器,委派给父类,如果没有父亲为null,调用findClass方法



| 自定义加载器实例 |
|---|

package com.company;
import java.io.*;
public class Test1 extends ClassLoader{
@Override
protected Class<?> findClass(String name) throws ClassNotFoundException {
File file = new File("D:\\IdeaProjects\\javaTest\\", name.replaceAll(".", "/").concat(".class"));//从项目路径找class文件
try {
FileInputStream fileInputStream = new FileInputStream(file);//获取指定class文件的输入流
ByteArrayOutputStream baos = new ByteArrayOutputStream();//获取字节数组输出流
int b = 0;
while((b=fileInputStream.read())!=0){
baos.write(b);//写内容
}
byte[] bytes = baos.toByteArray();//转为字节数组
baos.close();//关闭流
fileInputStream.close();//关闭流
return defineClass(name,bytes,0,bytes.length);//通过此辅助方法,将class文件写入内存,并返回对象
} catch (Exception e) {
e.printStackTrace();
}
return super.findClass(name);//上面失败,委派父类,让父类帮助加载
}
public static void main(String[] args) throws Exception {
ClassLoader classLoader = new Test1();
Class aClass = classLoader.loadClass("com.company.Hello");//传入文件路径
Hello hello = (Hello) aClass.newInstance();//利用反射获取对象
hello.m();//调用方法
System.out.println(classLoader.getClass().getClassLoader());//获取加载器
System.out.println(classLoader.getParent());//获取加载器的父加载器
}
}
3、编译器(JIT)和懒加载

- java使用混合模式,也就是使用频率不高的代码采用解释执行,解释执行启动速度快,使用频率高的代码采用编译执行,编译起来比较耗时,但是执行比解释快很多。
就是说,解释执行启动快,执行速度慢,编译执行启动慢,因为需要先编译,执行速度快
懒加载
JVM没有规定何时加载,采用按需加载,也就是说,需要用的时候才加载- JVM
明确规定何时必须进行初始化

4、初始化
| 根据我们上面介绍类加载器的加载过程时,介绍到过程一共是下面这些步骤,上面我们已经介绍完loading过程了,接下来介绍初始化过程 |
|---|
类加载过程
- loading(加载):将一个class文件加载到内存(此时生成了两个内存,一个是class文件的二进制放在内存中,然后生成一个class对象,此对象指向存放class文件二进制的内存地址)
- linking(连接):和内存地址连接
- verification(校验):校验加载的class文件是否复合文件标准
- preparation(准备):为文件中的静态变量赋默认值(
注意是赋默认值,比如一个static int i = 8 此时不是直接等于8,而是赋默认值)- resolution(解析):将
符号引用解析成内存地址也就是直接引用(在class文件,我们会发现常量池中有类似Object的常量,而我们通过特定的指令引用这些常量,这叫符号引用,但是这个常量在内存中的位置又是不同的,无法直接通过指令直接找到内存中常量的位置,而这一步骤就是让符号引用直接变成内存地址引用)
- initializing(初始化):为文件静态变量赋初始值(此时才真正给静态变量根据编程时指定的值赋值)
实例1:
- 首先我们在main方法调用了T.count,那么根据懒加载,只有我们需要用的时候才加载,此时将T类load到内存,进入linking过程,为静态变量赋默认值并建立内存连接
- 进入verification校验class文件是否符合JVM标准,然后进行preparation为静态变量赋默认值,此时count = 0,t = null(默认值),此时因为t = null ,则没有构造方法,count++没有执行
- 进入resolution,如果loading的时候,传入参数true,表示解析,那么此时会将符号引用解析为直接引用
- 进入initializing过程,为静态变量赋初始值,此时count=2,然后t = new T() ,此时会调用构造方法执行count++,那么count=3
- 类加载完成,输出3
实例2:
- 与上一个实例一样,不同的是verification过程赋默认值时,先给t赋值null,然后给count赋值0
- 然后initializing过程赋初始值时,先给t赋值new T() ,此时调用构造方法,执行count++,count=1,然后给静态变量count赋初始值,count = 2
- 类加载完成,执行输出,输出2


| 成员变量初始化 |
|---|
当我们new对象时,分三步,第一步先申请内存,然后赋默认值,第二步赋初始值,第三步变量指向内存地址、 |
三、字节码层面中面试常问细节
1、单例模式,双重检查
| 仔细看此实例,问:用不用加volatile关键字 |
|---|

答案是必须加volatile(volatile关键字的一大作用就是,阻止指令重排序),因为可能有线程读到一个半初始化状态的单例对象的问题
- 我们知道,变量赋值分为3步,申请内存赋默认值,赋初始值,变量指向内存
- 但是如果发生指令重排序,也就是申请内存赋默认值之后,直接变量指向内存,最后才赋初始值
- 那么仔细想想,根据上面的代码,如果第一个线程来赋值单例,发生指令重排序,初始化一半的时候,第二个线程进来,发现INSTANCE不是null了(因为赋默认值),直接拿着这个单例走了
- 但是还没有初始化呢,他拿着一个没初始化完成,只是一个默认值就走了,那么整个代码肯定要出问题

2、JMM,硬件层数据一致性
硬件层并发优化基础知识
现在,基本CPU都是多核的,显著提升速度,但是如果一个线程跑在第一个cpu内核,另一个线程跑第二个cpu内核,就有可能发生线程不同步问题 ,所以我们要理解,当其中一个线程改了x的值,另一个内核中的线程怎么才能知道值改了呢?方法有如下几种
- 所有cpu访问L3和主存都通过一条总线,给这条总线上锁,那么第一个cpu内核操作x值的时候,其它cpu内核无法访问,但是这种会极大影响效率,这是很久以前的老cpu才干的事
- 现有cpu采用
各种各样的一致性协议(缓存锁(MESI等)+总线锁),我们简单介绍其中的一种MESI一致性协议(读取缓存以cache line为基本单位,基本都是64bytes)
缓存行出现的问题-----》伪共享
当x和y在一个缓存行时,cpu1只用x,cpu2只用y,那么cpu1改x值,cpu2会立即同步缓存行,导致,因为一个完全和自己没关系的值改,而重新取主存拿资源
解决办法-----》缓存行对齐,我们看看disruptor的做法,看看它如何做到单机效率最强的-----可以看出它对缓存行进行的对齐(p1->p14),保证,无论是填充到前面还是后面,都不会和其它数据放到一个缓存行.极大提升效率,并且只浪费了一些空间,典型的空间换时间







3、cpu乱序执行
什么是乱序
就是cpu读的时候,可以同时执行不影响的其它指令,写的时候,可以合并写,因此,cpu执行时乱序的(比如下图中的烧水例子,在用烧水壶烧水的同时,可以做不影响烧开水的其它事,比如洗茶壶(烧水的是烧水壶,和这个不是一个壶,这个是泡茶的壶),洗茶杯)
另外,我们看图片右侧,发现有一个WCBuffer,这是用来合并写的高速缓存,它只有4个字节,每次都要凑满4个后合并去写,那么我们程序的一个优化点就可以,每次都4个一组去执行写操作,那么每次WCBuffer就正好拿到4个执行,又拿到4个执行,非常的顺滑,经过测试,每6个一组给cpu和每4个一组给cpu,后者比前者快1倍为什么要乱序执行
- cpu比内存速度快百倍,如果cpu执行了一条指令,下一条指令要等内存的数据,那么会慢百倍,这期间足够执行大量的其它指令了
- 所以cpu此时不会一味的等,而是执行其它不影响当前执行的其它指令,等到数据从内存拿过来的时候,再继续执行刚才的指令,充分利用cpu资源
如何保证特定情况下,不乱序执行
- volatile关键字修饰的,可以保证有序性,此关键字的两大作用:有序并且禁止指令重排序
- 汇编指令(下面这是x86的,其它的需要具体去查),cpu级别的内存屏障(为了不使用锁,因为影响效率),比如下面这个sfence指令,在这条指令之前的写操作和之后的写操作不能重排序,上面的不能去下面执行,下面的不能去上面执行
- JVM级规范屏障(就是只是规范了屏障,实际的屏障,还是使用上面的汇编和原子指令操作来实现,需要根据不同操作系统和硬件来决定如何实现,比如AMD的cpu指令,需要特定去查)



4、volatile实现细节
字节码层面的细节
访问标志中会有volatile修饰,也就是加了ACC_VOLATILE修饰符
JVM层面的实现细节
在volatile操作前后都加了屏障,最好将这些屏障背会,StoreStroeBarrier这些单词念起来还是比较顺口的
OS和硬件层面的细节
- 我们需要通过工具hsdis,反汇编,将虚拟机编译完成的字节码反汇编,查看汇编指令
- 在windows上,基本上是通过lock指令来实现
总结
在字节码上,只是加了ACC_VOLATILE标识具体实现在JVM,JVM上是在volatile操作上下都加内存屏障,内存屏障实现在硬件和操作系统,在硬件和操作系统上,使用汇编指令,以及windows使用lock指令实现,其它系统需要特定去查



5、Synchronized实现细节
字节码层面
接下来看下图,我们发现锁对象时,会多几条指令monitorenter和两个monitorexit,可见锁住的指令是在monitor块中的,monitorenter表示进入块,另一个表示退出块,有两个monitorexit表示,遇见异常也自动退出块
JVM层面
C C++ 调用了操作系统提供的同步机制
OS和硬件层面
依然拿x86举例,windows使用lock指令


6、排序规范
java八大原子操作(已弃用)
仅仅放弃了用这些内容来描述,但是模型没变
java并发内存模型
JVM规定重排序必须遵守的规则




7、对象
对象创建过程
类加载-进行静态变量赋默认值并建立直接连接-静态变量赋初始值(上面这些是类没有在内存时,需要先load到内存)------》对象申请内存-赋默认值-调用构造方法-成员变量按顺序赋初始值-执行构造方法语句
如何查看java虚拟机参数
对象在内存中的存储布局(就是对象在内存中如何存储,比如下面普通对象,由8字节对象头+4字节class指针指向类文件在内存中位置+4字节实例数据+如果整个对象只有14字节,那么最后会填充2字节对齐,因为8的倍数效率更高)
对象大小(比如Object o = new Object()的大小,new int[]{}的大小,这些是空对象,不计算数据大小)
- 首先java有一个agent机制,就是class文件加载到内存的过程中,agent代理,会截获class文件,可以对其更改,并可以获取整个Object的大小,但是过程及其麻烦,就直接说测试结果
Object大小为16字节:首先脑袋(对象头)8字节,然后class指针4字节(因为虚拟机默认压缩指针开启,所以8字节压缩为4字节),然后现在一共12字节,因为需要是8的倍数,所以padding对齐4个字节,最终16字节new int[]={}空数组大小为16字节:脑袋8字节+指针4字节+数组长度4字节=16字节,正好8的倍数,无需padding对齐- 上面情况都是虚拟机默认开启指针压缩的情况,面试时要将两种情况都说出来
- 下面是关闭指针压缩的大小
- 实例计算new P() 实例对象的大小(提示,引用类型比如int i; 那么内存中,会分配数据类型默认大小的空间,比如int是4字节)
最终结果为32字节,脑袋8+指针4+两个int 8+一个String 4+3个byte 3+ object 4 = 31,不是8的倍数,padding填充1 = 32什么是Oops
普通的对象的指针,和类指针不一样,很多书籍都误导了
对象头具体包括什么
我们安装Oracle官方的JVM虚拟机来讲解,它将对象头内容定义在如下文件
对象定位
- 句柄池:T t = new T();时,t先执行一个指针,此指针分别指向class对象的内存地址,和class文件在内存的地址(此做法相对访问速度慢,但是垃圾回收的时候效率高)
- 直接指针: t直接指向class对象的内存地址,class对象是始终指向class文件的,所以此做法访问效率更高,垃圾回收就相对麻烦一点








8、JVM Runtime Data Area(java运行处理区)
一道面试题
i=i++最终结果为8,i=++i最终结果为9
运行时引擎
运行时引擎的位置
运行时区域
PC的含义
其它的一些内容的含义
下图Local Variable Table 叫局部变量表 ,Operand Stack叫操作栈线程共享区域
解释面试题
细看下面指令,左边是i = ++i的字节码,右边上是i = i++
- bipush:压栈,将8这个值搞成int值,将其push到栈中
- istore_1: 将栈中int值,放在局部变量表中为1的位置,上图最右面是局部变量表,发现1的位置是变量i,也就是放在i中
- iinc 1 by 1: 将局部变量表为1的位置的值,+1
- iload_1: 将局部变量表中为1的位置的值,拿出来进行压栈,就是放在栈中
- return: 赋值操作
根据上面的解析,我们可知,先看处于右面的字节码,它是i = i++的指令,
- 前两条指令表示,先将8这个值压栈(放到栈),然后将栈里面这个值放在局部变量表中的1这个位置,此时int i = 8;执行完成,这两条指令就是这句代码
- 第3条指令,将局部变量表中1位置的值拿出来,压栈,此时栈中有一个值8,局部变量表1位置值为8
- 第4条指令:将局部变量表中1位置的值+1,现在栈中为8,局部变量表1位置为9
- 第5条指令:将栈中int值放在局部变量为1位置,也就是将栈中的8给局部变量表1位置,现在局部变量表1位置为8
- 最后一条指令,赋值,那么最终i的值为8
那么经过解析,很容易就能知道为什么i = ++i的结果是9了,看上图中最左边的字节码文件
- 将8压栈-----》栈中的8放局部变量表1位置----》局部变量表1位置+1----》将局部变量表1位置值9压栈----》将栈中值放在局部变量表中为1位置----》赋值,最终i = 9









9、栈
栈帧
每个方法对应一个栈帧,每个栈帧都有4个内容,局部变量表,操作栈,动态链接(要频繁的去方法区中找class执行方式和常量),返回地址(当前栈帧执行完成,弹出栈,此时栈会根据此地址,执行下一个栈帧,也就是它存储的是下一个栈帧),每个栈帧都操作同一个堆
栈的执行流程
下图int i=200因为超过了127,超过了byte所能代表的大小,所以改用short类型也就是sipush,下图写错了,不是超过了120,而是127
下图解释为什么可以用this
下面解释字节码文件如何执行相加操作(另外执行完相加后,3和4就弹出栈了,最后栈中只有一个7,当7给了c后,栈中没有东西了)
下面解释调用和new对象的字节码
- new:申请内存地址,此时main栈帧的操作栈将拿出一块区域赋默认值
- dup:建立链接,此时复制一个刚刚栈中的内容,放在其上面,链接同时指向这两个区域
- invokespecial:调用特定方法,这里调用的是构造方法,此时为栈中内容,就是h赋初始值,并且弹出刚才复制的内个
- astore_1:将栈中内容放在局部变量1中,此时栈中h弹出
- aload_1:将局部变量1中内容压栈(放在操作栈,需要在栈中执行操作),此时栈中有h
- invokevirtual:执行成员方法m1,然后h弹出,此时前往下一个栈帧m1执行
- m的字节码前面都讲过就不赘述了,就是给i赋值200,然后return,m1从JVM栈中弹出,回到main1栈帧
- main栈帧继续执行,又遇到return,弹出栈帧,JVM栈没有内容了,执行完成,程序结束。
下面解释方法返回值的字节码
下面解释递归,命令含义都列出来了,自己看吧,这个很多人写代码都写不明白,更别说字节码了,懂得自然能看懂








10、 invoke指令
invoke指令
- InvokeStatic 用以调用类方法
- InvokeVirtual 执行成员方法
此指令会执行当前栈中压的对象里面的成员方法,所以实现了多态,栈中压的谁就执行谁的指定成员方法
- InvokeInterface 调用接口方法
在运行时搜索一个实现了这个接口方法的对象,找出适合的方法进行调用
- InvokeSpecial 调用特定方法
调用可以直接定位的,不需要多态的方法,一般用来调用private修饰的方法和构造方法
- InvokeDynamic
lambda表达式、反射、其它动态语言动态产生的class,用此指令
四、垃圾回收
| 没有引用指向的东西就是垃圾 |
|---|
| 两个概念 |
|---|
| YGC:young GC,伊甸区不足(存放年轻代对象空间),触发YGC |
| FGC:全堆范围的gc。默认堆空间使用到达80%(可调整)的时候会触发fgc |
1、找垃圾
如何找到垃圾?
- reference count 引用计数:下图中红圈表示对象,蓝线表示引用,蓝色方块表示值,数字3代表现在有3个对象引用它,
当第一个红圈对象使用完,断开引用,此时数字3变为2,当数字变为0表示没有对象引用,此时这个蓝色方块表示垃圾,需要回收
但是这种算法无法处理以下结构(循环引用),每一个蓝方块,都记录自己下一个是谁,那么每个计数都是1,当某个蓝方块被断开引用,此时它就变为垃圾,但是它还记录着下一个蓝方块,如果它被回收,那么它引用的蓝方块就找不到了
- 根可达算法,下图中,最上面的4个紫色方块表示根,如果它的引用通过路径可以找到,那么找到的都不是垃圾,通过路径从根无法到达的,便是垃圾,比如右下角的3个方块,无法从根找到,则被回收



2、垃圾清除算法
- Mark-Sweep 标记清除
- 首先所有未使用空间是保存到特定的空闲列表中的,此算法不会找列表中的东西。然后此算法会找到所有存活对象(不可回收对象),将剩下的对象标记为可回收对象,然后清除被标记对象。适合在存活对象多的情况下使用。(共扫描两遍,第一遍找所有存活对象,第二遍将剩下的找到回收)
- Copying 拷贝
- 同样空闲列表不做考虑,找到所有存活对象拷贝一份,然后清除所有对象(无论是有用的不可回收还是没用的可回收),之后通过一系列对象引用转换操作,让之前的引用对象重新指向拷贝后的对象。(
就是把能用的先复制一份,然后把除了刚复制的对象以外的都删了,难点在于原来的引用如何指向复制后的对象,适用于存活对象少,扫描一次,效率高,无碎片,但移动过程中浪费空间)
- Mark-Compact 标记压缩
- 空闲列表不考虑,先找到所有不可回收对象,放在最前面,然后回收垃圾(扫描两次,第一次找不可回收,第二次将不可回收移动到前面。涉及对象的移动,效率有一定影响,但方便对象分配,不会产生内存减半问题,不会产生碎片)






3、堆内存逻辑分区

- 分代
- 除Epsilon、ZGC、Shenandoah之外的GC(垃圾回收器)都是使用逻辑分代模型
- G1是逻辑分代,物理不分代
- 除此之外,不仅逻辑分代,而且物理分代
- 一个对象从出生到消亡
- 对象出生时,尝试在栈上(stack)分配,如果栈装不下,进入伊甸区(Eden)
- 进入伊甸区后,垃圾回收1次,则进入幸存区域(survivor)1区
- 然后再垃圾回收一次,进入survivor2区,如果再回收一次那么再进入1区,然后再进入2区,一直循环直到年龄够了
- 年龄够了,进入老年区(Old)
- GC概念(记住叫法,面试官一般会通过概念名词问你,你听不懂就没办法解答)
- MinorGC/YGC:年轻代空间耗尽时触发的回收
- MajorGC/FullGC:在老年代无法继续分配空间时触发,新生代老年代同时进行回收
- 分配担保
survivor区满了,分配担保,直接让其进入老年代


4、栈上分配

栈上分配优势(栈上分配比堆上快的多,因为直接弹出,不涉及内些麻烦的操作)
- 线程私有小对象,每个线程有自己的小对象
- 无逃逸,在一个局部变量的使用中,直接用完就扔,叫无逃逸,如果在外面定义了,那么用完后,依然保留,这叫逃逸
- 支持标量替换
- 调优时,一般不调整这个东西
线程本地分配TLAB(当eden就剩一个空间,多个线程挣用,必将产生同步问题,需要解决同步,浪费资源,而TLAB是在eden中分配1%作为线程独有空间,避免不必要挣用)
- 占用eden,默认1%
- 多线程时,无需竞争eden就可以申请空间,提高效率
- 小对象
- 调优时,无需调整
5、 对象何时进入老年代

- 超过XX:MaxTenuringThreshold参数指定次数(YGC),如果不指定,那么根据不同算法,次数如下所示
- Parallel Scavenge :15次
- CMS : 6次
- G1 : 15次
- 动态年龄(当某些情况下,并不是达到上面规定的次数才进入老年代)
比如s1(幸存者1区)中拷贝一些东西到s2,这些东西拷贝过来后,总体的年龄已经超过幸存者区域默认规定的年龄总和的50%了,那么此时,不考虑次数,直接将当前年龄最大的放入old区(
就是如果幸存者区的对象年龄加起来,超过总年龄(参数设置的年龄总量)的50%,年龄大的直接晋升老年代)
- 总结
- 当一个对象new后,进行栈上分配,用完可以直接pop弹出,直接结束对象生命周期,这就是栈上分配的好处
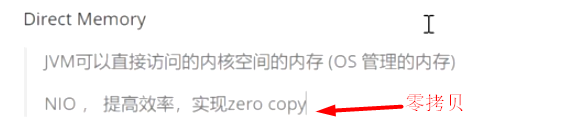
- 栈满了,没办法继续栈上分配,那么需要判断当前对象是否很大,如果很大,直接进入老年区,最后通过FGC(老年代空间不够了,进行的回收)回收
- 如果对象不是很大,那么进行TLAB(线程本地分配,好处就是不需要线程挣用与同步),如果大小适当,直接进入伊甸区中为其分配的1%(默认情况下是1%),否则,直接放在伊甸区
- 此时,伊甸区的对象如果进行1次垃圾回收,如果
没有被清除,则进入幸存1区(S1),再次回收,判断年龄,如果年龄够大,进入老年区,不够大进入S2,S2中再回收一次,就直接再进到S1,不判断年龄,S1再回收,才继续判断年龄

6、常见垃圾回收器

历史:JDK诞生是,Serial就开始追随,为了提高效率,诞生PS(Parallel Scanvenge),为了配合CMS(CMS在1.4版本后期引入,开启了并发回收时代,但毛病较多,暂时没发现有JDK版本使用),诞生了PN(ParNew),Serial表示单线程,Parallel表示多线程并行,CMS表示多线程并发(工作和垃圾回收同时进行)
- Serial 年轻代 串行回收,STW(让所有工作中线程停止,正在工作中,完成手里头工作再停),然后单线程进行回收,回收完,让线程继续工作,也就是只有一个清理线程清理
- Parallel Scavenge(PS) 年轻代 并行回收,和Serial不同点在于,它清理线程有多个,STW后,多个线程进行回收
- ParNew(Parallel New,PN) 年轻代 配合CMS的并行回收,同样要先STW,它在PS基础上进行了增强,以便和CMS配合,
PN响应时间优先(配合CMS),PS吞吐量优先- SerialOld
- ParallelOld(PO)
- ConcurrentMarkSweep(CMS) 老年代 并发的,垃圾回收和应用程序同时运行,降低STW的时间(200ms)。另外,它使用的算法是三色标记+Incremental Update
- CMS问题较多,所以现在没有一个版本是默认CMS,只能手工指定,
- CMS既然是MarkSweep,就一定会有
碎片化问题,碎片到达一定程度,CMS的老年代分配对象分配不下的时候,使用SerialOld进行老年代回收- 想象:PS + PO -> 回收10G内存垃圾(回收一次用来10十多秒) ,换CMS垃圾回收器 -> PN + CMS +SerialOld(几个小时-几天的STW)
- 几十G内存,单线程回收->G1+FGC 几十个G -> 上T内存的服务器ZGC
- CMS工作过程
- 初始标记,先STW,然后将垃圾的内些根标记上,具体参考上面找垃圾内一节介绍的根可达算法,我们就是标记内些根,此步骤耗费时间不多,和Serial 等垃圾回收STW比非常短
- 并发标记,占据整个过程80%的时间,和工作线程并发执行,标记所有垃圾
- 重新标记,并发标记过程中产生的新垃圾,或者已经标记为垃圾的,现在却不再是垃圾的,先STW,然后重新标记一下,耗费时间也很短,因为不多
- 并发清理,和工作线程同时进行,但是此时如果产生新的垃圾,不会清理这些新产生的,这些新垃圾叫浮动垃圾,只能等下次CMS执行一起清理
- G1(10ms),只在逻辑上分年轻代,老年代,使用三色标记+SATB算法
- ZGC(1ms) ,PK C++,使用算法,颜色指针ColoredPointers + 读屏障
- Shenandoah,使用算法 颜色指针+ 读屏障
- Eplison
- 1.8默认垃圾回收:PS + ParallelOld
- 常见回收器组合:Serial组合(Serial+SerialOld),Parallel组合(Parallel Scavenge+ParallelOld),ParNew+CMS组合
- 垃圾回收器根内存的大小关系
- Serial 几十M
- PS 上百M-几个G
- CMS 20G
- G1 几百G
- ZGC 4T

7、1.7的永久代(Perm Generation)到1.8的元数据区(Metaspace)
- 永久代,是JDK1.7用来存放所有元数据,和所有class的,包括String,动态代理内些动态生成的类,很容易溢出
- 永久代必须指定大小限制
- 元数据区,没有大小限制,受限于你的物理内存,但是你也可以指定元数据区的大小
- 1.7版本时,字符串常量都放在永久代
- 1.8以后,字符串常量放在堆中
- MethodArea,方法区,是一个逻辑概念,1.7以前指的就是永久代,1.8之后是元数据区,存class的元信息,代码的编译信息,各种层次信息等,另外它是堆之外的空间
8、常见垃圾回收器组合参数设定(1.8)
- -XX:+UseSerialGC: 指定垃圾回收器为Serial New(DefNew)+Serial Old
小型的程序,默认不会是这种选项,HotSpot会根据计算以及配置和JDK版本自动选择回收器
- -XX:+UseParNewGC: 指定垃圾回收器为ParNew + SerialOld
这个组合以及很少使用了,某些版本已经废弃
- -XX:UseConcMarkSweepGC :ParNew+CMS+SerialOld
- -XX:UseParallelGC :Parallel Scavenge + Parallel Old
- -XX:UseG1GC : G1
- windows下通过如下命令会显示默认GC是什么,Linux没有找到查看方法
java +XX:PrintCommandLineFlags -version
- Linux下1.8版本默认回收器是
- 1.8.0_181(看不出来),Copy MarkCompact
- 1.8.0_222默认PS+PO
9、JVM常用命令行参数
HotSpot参数分类
- 标准:-开头,所有HotSpot都支持
- 非标准:-X开头,特定版本HotSpot支持特定命令
- 不稳定:-XX开头,下个版本可能取消
- 常用命令(Linux上使用,如果要在windows中的idea上指定,把前面的java关键字去掉)
- java -XX:+PrintCommandLineFlags 要运行的类
用默认值指定堆大小,类指针和普通指针,然后运行程序
- java -Xmn10M -Xms40M -Xmx60M -XX:+PrintCommandLineFlags -XX:+PrintGC 要运行的类
- 手动指定堆大小,Xmn表示新生代大小,Xms和Xmx表示堆的最小和最大值,一般设置为一样,不一样会因为弹性,浪费计算资源
PrintGC的意思是打印基本GC回收信息,还可以指定为PrintGCDetails 打印的更详细,PrintGCTimeStamps 打印具体时间,PrintGCCauses 打印GC产生原因
- java -XX:+UseConcMarkSweepGC -XX:+PrintCommandLineFlags 要运行的类
使用并发标记算法回收
- java -XX:+PrintFlagsInitial 默认参数值
- java -XX:+PrintFlagsFinal 最终参数值
- java -XX:+PrintFlagsFinal | grep xxx 找到对应的参数
- java -XX:+PrintFlagsFinal -version |grep GC
- 一段实验用程序(一个链表List,每个节点分配1M,无限循环,内存迟早占满)
- idea如何指定运行程序的参数
- Linux指定参数运行程序
- 查看是否内存溢出(out of memory表示内存没有空间了),另外内存泄漏(memory leak)表示一块内存被占,但是占内存的对象一直得不到回收,这块内存无法释放,别人也用不了,叫内存泄漏
- 指定新生代和堆大小,打印GC回收信息
- 使用并发标记算法回收,也就是CMS
- 打印日志详细信息








10、GC日志解析

heap dump的日志解析
- 上图中new generation表示总空间,total是总大小 = eden伊甸区+1个幸存者区(S区),因为每次只能使用一个,所以total=eden+1个,而不是eden+2个
- 上图的意思是,eden区(伊甸区),从起始地址到结束地址,整个空间大小为5632K,使用了94%,使用空间结束地址表示从起始地址到空间结束地址,占整个空间的94%


11、G1


| G1逻辑模型,与以前的回收器已经完全不一样了 |
|---|
- G1 将内存分为多个小空间Region,空间大小1m到32m(2的幂次方),可以自己设定,但必须2的倍数
- 小空间可以存放任何区的东西,其中Humongous是大对象,它是多个小区域组合而成
- 小空间不属于特定区,无论是伊甸区还是老年区,它都可以存储,当前伊甸区被使用完,它将变成空白区,下次如果需要幸存者区域,那么它就可以当做幸存者区用


| G1基本概念 |
|---|



| 阿里正在研究的一个专门用于webapp项目的JVM |
|---|
当一个用户session进入服务器,产生的对象,在session结束时,对象不会立即回收,而是等最后的GC回收一起回收,而阿里巴巴想要做一个,当session结束时,立即将对象回收的JVM

| G1新老年代比例 |
|---|
无需手工指定,动态调整区域大小,比如一个区域有点大,让stw时间过长,那么G1会动态的将区域调小一点
| G1产生FGC怎么办 |
|---|
对象分配不下就会产生FGC
- 扩内存
- 提高CPU性能,回收更快,业务逻辑产生对象的速度固定,垃圾回收越快,内存空间越大
- 降低MixedGC触发的阈值,让MixedGC提早发生(默认是45%)
| G1中的MixedGC |
|---|
MixedfGC默认在堆内存使用超过45%时开启,可以由下面的参数设置

相当于一套完整的CMS
- 初始标记STW
- 并发标记
- 最终标记STW(重新标记)
- 筛选回收STW(并行)
12、并发标记算法TODO
五、调优
| 调优前需要了解的概念 |
|---|
- 吞吐量:用户代码执行时间/(用户代码执行时间+垃圾收集执行时间)
- 响应时间块:用户线程停顿的时间短,STW越短,响应时间越好
- 确定调优之前,应该确定到底那个优先,是计算型任务还是响应型任务,然后对症下药
| 什么是调优 |
|---|
- 根据需求进行JVM规划和预调优
- 熟悉业务场景,进行压力测试,没有最好的垃圾回收器,只有最合适的,考虑是用户响应优先,还是吞吐量优先,然后监控,无监控,不调优
- 选择回收器组合
- 计算内存需求
- 设定年代大小、升级年龄是多少
- 设定日志参数
- -Xloggc:/opt/xxx/logs/xxx-xxx-gc-%t,log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=20M -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCCause
2.或者每天生产一个日志文件
- 观察日志情况
- 案例分析
- 垂直电商网站,要求响应时间100ms,或者业余的问法,每日百万订单,需要什么服务器配置
- 首先,100W订单,我们需要
知道订单量大的时间段,比如最大100订单/s或者最高峰的时候1000订单/s,接下来开始分析。首先需要服务器配置也不需要多关心,因为不同的服务器配置都能支持,内存1.5G或者内存16G,都是可以的,无非就是垃圾回收的快慢,次数多少的问题。关键是,在最高峰的时候能不能支撑的住,比如1.5G内存,1000个订单过来,瞬间占满了内存,然后程序崩了,那么,这时候,可能需要换垃圾回收器,或者加内存。但是一般一个订单最大也就512kb,1000个也就500多m,根本不存在占满的问题,出现崩溃可能只是垃圾回收不及时(响应时间慢),导致内存溢出。一般,假设新生代空间分配256M,瞬间1000个订单500M过来,只要响应时间跟得上,也不会崩溃。所以最终需要关心的就是,响应时间应该达到什么水平,比如100ms以下,然后选择不同的机器压测,最后根据压测结果选择合适的服务器配置。这就是为什么这是专业的问法,而需要什么服务器配置是业余的问法- 如果面试问到,你可以这样说:首先知道订单的最高峰,比如1000个订单/s,那么1000个订单按512M来算,如果16G内存,那么就随便扔,反正也占不满,最后在VGC回收即可,如果1.5G内存,只要CPU响应速度够快,能够及时响应,清理垃圾,然后剩下的订单跟上,也没有问题。
- 12306遭遇春节大规模抢票,如何支撑
- 12306应该是并发量最大的秒杀网站了,号称并发量最高的时候达到100W并发
- 那么这时候就需要很多均衡负载集群策略,使用CDN(缓存,用户是北京的,访问北京服务器,响应块)->LVS->NGINX->业务系统->每台机器1W并发(10K问题,单机10K并发,目前没有解决方案,理论上10000个redis可以解决),一百台机器同时处理
- 分析业务,普通电商,一般是下单->业务系统(订单系统IO减库存)->用户付款。而12306可能是下单->减库存和订单同时
异步进行(如果同步,必须付款才减库存,可能撑不了多久)->等付款- 最好把库存放在一个服务器上,所有减库存都找这个服务器,那么减库存还是会把压力压到一台服务器,压力很大
- 所以最后我们需要做分布式本地库存+单独服务器做库存均衡
- 总结,大流量处理方法,就是分而治之
- 怎么得到一个事物会消耗多少内存?
- 弄台机器,看能承受多少TPS,是不是达到目标,如果没有,通过扩容和调优,让它达到
- 用压测来确定
- 优化运行JVM运行环境
- 有一个50万PV的资料类网站(从磁盘提取文档到内存),原服务器32位,1.5G的堆,用户反馈网站比较缓慢,因此决定升级为64位,16G的堆内存,结果用户反馈卡顿十分严重,效率更低了,如何优化
- 原网站为什么慢?很多用户浏览数据,很多磁盘数据load到内存,
内存不足,频繁GC,STW时间长,响应时间变慢- 为什么加强硬件,开始卡顿?1.5G内存,GC时,STW因为内存不大,所以单次STW也不是特别长,只是整体有点慢,但是16G内存,
内存越大,FGC时间就越长。当16G内存满了,再STW的时候,由于垃圾太多,时间就更长,给用户的感官就不是响应较慢,而是卡顿了解决办法:将PS换成PN+CMS或者G1
- 系统CPU经常100%如何优化
- 占用高,肯定有线程在占用系统资源
- 首先得找出哪个进程cpu占用高(top来找),然后找出这个进程中哪个线程占用高(top-Hp)
- 如果是java程序,我们可以导出该线程堆栈(jstack)
- 查找哪个线程(栈帧)消耗时间(jstack)
- 系统内存飙高,如何找问题所在
- 导出堆内存(jmap工具导出)
- 分析(jhat jvisualvm mat jprofiler…都可以进行分析)
- 如何监控JVM
- jstat jvisualvm jprofiler arthas top…都可以
- 解决JVM运行过程中出现的各种问题(OOM)
1、linux中用各种命令来定位错误
直接通过top命令,获取进程信息,可见下面占用最高cpu和内存的java程序,进程号为1364 |
|---|
另外,jps命令,可以只显示java进程 |

通过命令top -Hp 进程号,查看进程所有线程 |
|---|


jstack命令,定位线程状况 |
|---|
注意:这里我虚拟机崩了,所以重新运行了程序,进程号变成了1591
- 通过
jstack 进程号命令,查看所有线程的运行状况,注意,jstack所有线程号都以16进制为准
- WAITING状态:一直在等待状态(下图可见,它一直在等一个对象,是Object类型的,这就可以知道,这个线程在等什么而一直处于WAITING状态,如果有100个线程waiting on < xxxx>,那么我们一定要找到哪个线程持有这把锁)
发生如上状况,如何找到哪个线程持有锁呢?找到waiting on 后面< xxxx>内个对象,看哪些线程有这个对象,然后持有这个对象的线程一般是RUNNABLE状态
同样的,我们也得在编程的时候,尤其线程池中,给线程起有意义的名称
- BLOCKED: 拿不到锁,被阻塞
- RUNNABLE:运行状态






jmap -histo 进程号查看进程中哪些类对象非常多,一般太多的类,都是垃圾回收不掉的 |
|---|
| 下图,instances表示这个类有多少个对象 |
| bytes 表示一共占多少字节 |

但是,我们一般不会在线区查看这些东西,而是通过jmap -dump:format=b,file=导出文件路径 进程号命令导出文件,观察
此命令慎用,因为线上时,如果内存很大,jmap执行期间,会对进程产生很大影响,甚至卡顿
那么如何该怎么办呢?
- 运行程序时,指定了HeapDump参数,OOM(内存溢出)的时候会自动产生堆转储文件(不推荐,因为也消耗多余资源)
- 如果有很多服务器备份(高可用),停掉这台服务器对其它服务器不影响,把这台服务器隔离开,然后使用jmap命令导出监控信息(推荐)
- 在线定位,后面会讲(大公司面试可以提一下,使用阿里的在线排查工具arthas,小公司用不到这种东西)
| 定位OOM(内存溢出) |
|---|
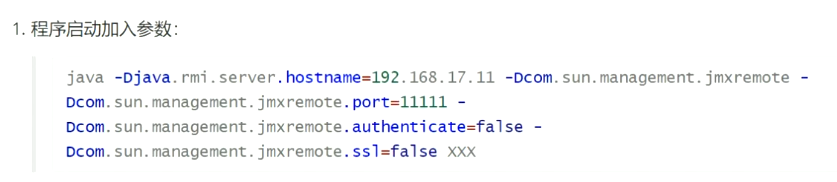
- 图形化界面定位(通过开启JMX协议,直接挂在进程上,让你可以远程监控程序,但是额外的消耗资源,不可以在上线后使用,压测的时候,测试的时候使用)
- 运行程序时,带上参数,开启JMX协议
- windows中,找到你JDK的bin目录下,自带了一个jconsole工具,连接上面参数中指定的hostname和端口
- 已经上线的系统,用cmdline和arthas工具
推荐arthas,阿里巴巴推出的在线排查工具


- 另外,生产环境不能随便dump,小堆影响不大,大堆会有服务暂停或卡顿(加live可以缓解),dump前会有FGC
- 场景OOM问题:栈、堆、MethodArea、直接内存
2、阿里巴巴Arthas在线排查工具
| 直接百度,进入官方文档学习使用即可 |
|---|

| 如何使用 |
|---|
保证你在linux运行了java程序,必须是一直执行的,而不是直接运行结束的内种,否则也不需要监控了
- 下载后解压到linux
- 运行
- 挂到指定程序进程上
- jvm命令查看JVM的详细配置情况
- thread命令,列出所有线程运行状况,thread 序号,查看指定线程状态
- dashboard命令,用命令行模拟图形界面,观察系统情况
- deapdump命令,相当于上面讲的jmap -dump命令,导出dump状态,可以直接deapdump 路径,导出到指定路径,生成的dump文件,如何分析,可以百度如何使用MAT分析dump
- jad反编译命令,只要你知道类的名称或全路径(最好是全路径,因为很多重复class),比如jad com.yzpnb.erdisa.ArrersMain,就会将ArrersMain的字节码反编译过来,多数用在定位动态代理问题,第三方类问题,版本问题(确定是不是最新的代码版本)等
redefine:热替换(只能改方法实现,不能改方法名,不能改属性),下图中,我们先将TT类重新修改,然后重新编译,最后通过redefine命令热替换了class



























 7741
7741











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











