







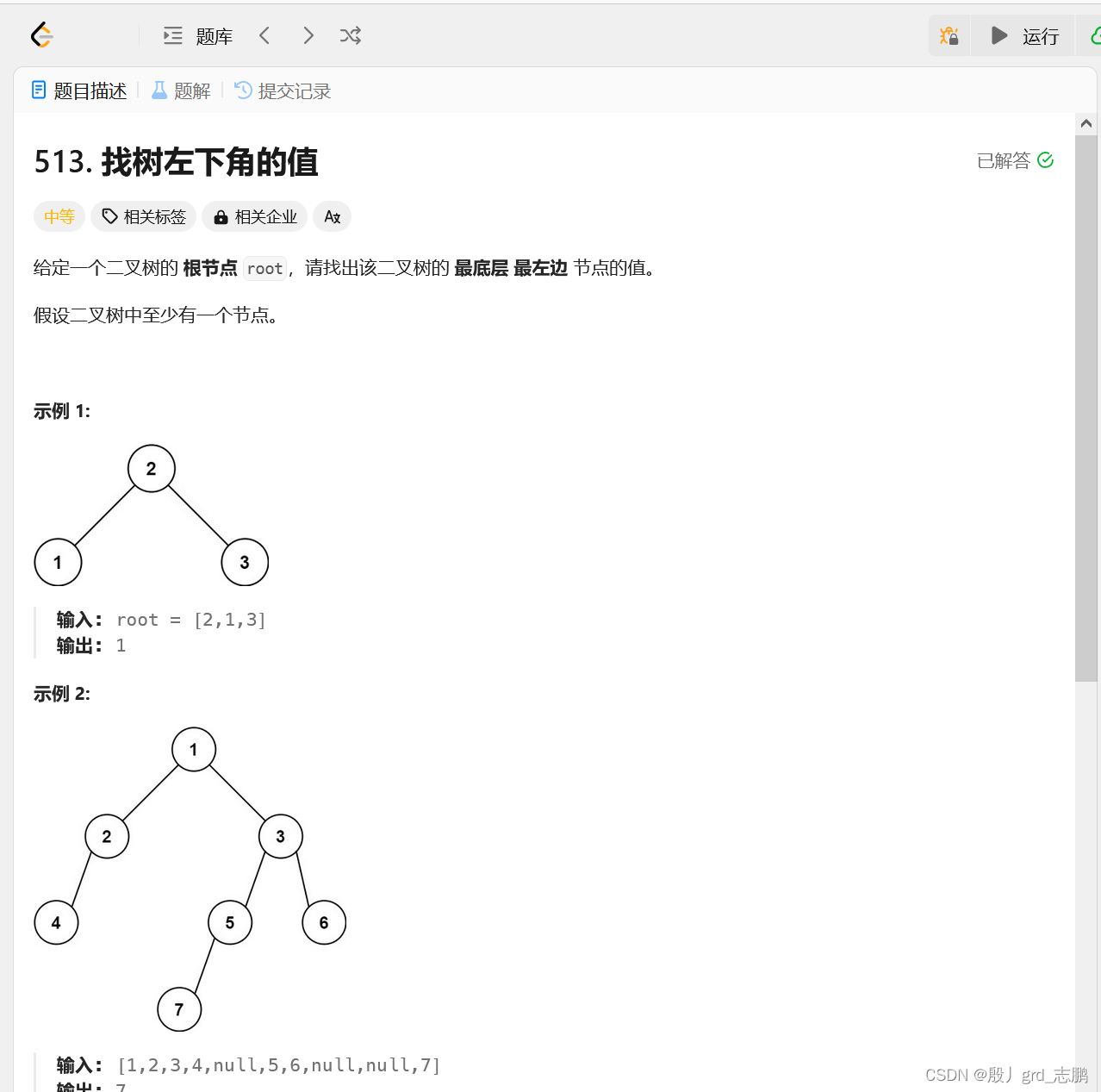
| java数据结构与算法刷题目录(剑指Offer、LeetCode、ACM)-----主目录-----持续更新(进不去说明我没写完):https://blog.csdn.net/grd_java/article/details/123063846 |
|---|
1. 深度优先
| 解题思路 |
|---|
- 先深度优先遍历左结点,获得可到达的最左结点高度A
- 然后递归向上继续深度优先
- 如果递归向上过程,
没有发现比A高的高度,那么最开始的那个左节点就是我们要找的- 但如果我们
发现比A高的,那么我们优先进入更高层。而因为我们先深度遍历左节点。所以就算进入更高层,依然是获得当前结点的可到达的最左结点B,然后更新高度为B。继续递归向上。- 直到遍历完成,注意只有高度更高时,才更新
| 代码 |
|---|

/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
int curVal = 0;//遍历过程中,当前最左结点
int curHeight = 0;//遍历过程中,当前最左结点的层次
public int findBottomLeftValue(TreeNode root) {
dfs(root,0);//第0层开始遍历
return curVal;
}
public void dfs(TreeNode root,int height) {
if(root == null) return;//如果当前结点为空,直接返回
//不为空就进行深度优先遍历.有下一层就去下一层
height++;
//先找左
dfs(root.left,height);//遍历左子树,层级+1
//如果右边的层级更高,优先高层级
dfs(root.right,height);//遍历右子树,层级+1
if(height > curHeight){//如果当前层的深度比记录的深
curHeight = height;//更新
curVal = root.val;//更新
}
}
}
2. 广度优先
| 解题思路:所有结点遍历一遍的情况下,广度优先比深度优先慢一倍.因为入队列出队列,每个结点访问两次 |
|---|
- 广度优先,就相当于层级遍历,正好适合这道题
- 每一层我们从右到左遍历,当遍历到最后一个结点时,正好是最后一层的最左边结点
- 所以我们要先入队列右节点,然后在入队列左节点,和一般情况下,从左到右层级遍历是反过来的。这点要注意
| 代码 |
|---|
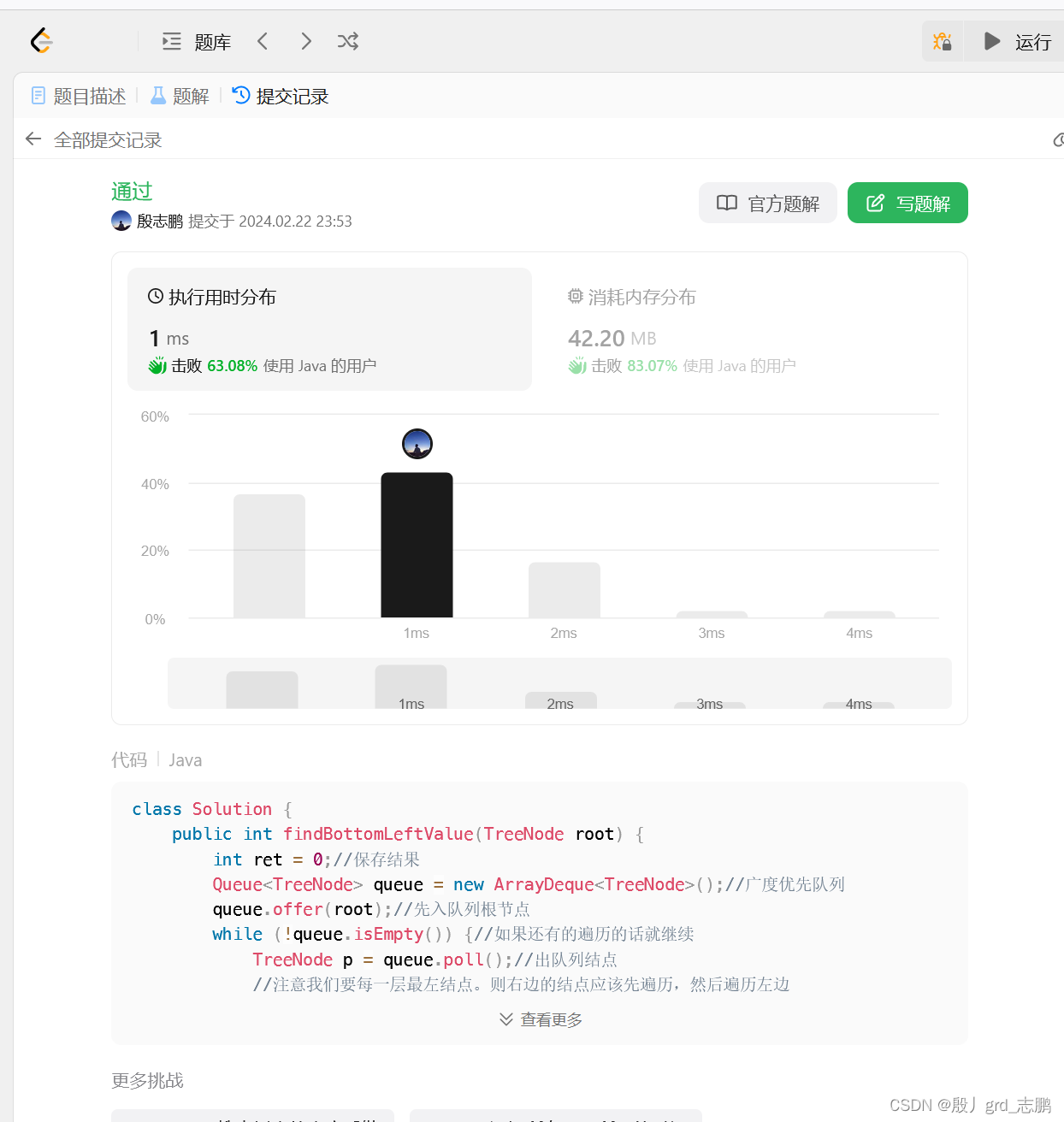
class Solution {
public int findBottomLeftValue(TreeNode root) {
int ret = 0;//保存结果
Queue<TreeNode> queue = new ArrayDeque<TreeNode>();//广度优先队列
queue.offer(root);//先入队列根节点
while (!queue.isEmpty()) {//如果还有的遍历的话就继续
TreeNode p = queue.poll();//出队列结点
//注意我们要每一层最左结点。则右边的结点应该先遍历,然后遍历左边
//这样最后才能知道,留下的是左边的结点
if (p.right != null) {//如果有右子树,先右,否则会先把左,出队列,我们就无法获取当前层左下角的值了
queue.offer(p.right);
}
if (p.left != null) {//左节点后出,才能在当前层遍历完成后,得到是左边的结点
queue.offer(p.left);
}
ret = p.val;//保存值,因为左节点是后入队列的,所以最后会保存到最左的结点
}
return ret;
}
}
















 516
516

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











