







MapReduce
MapReduce
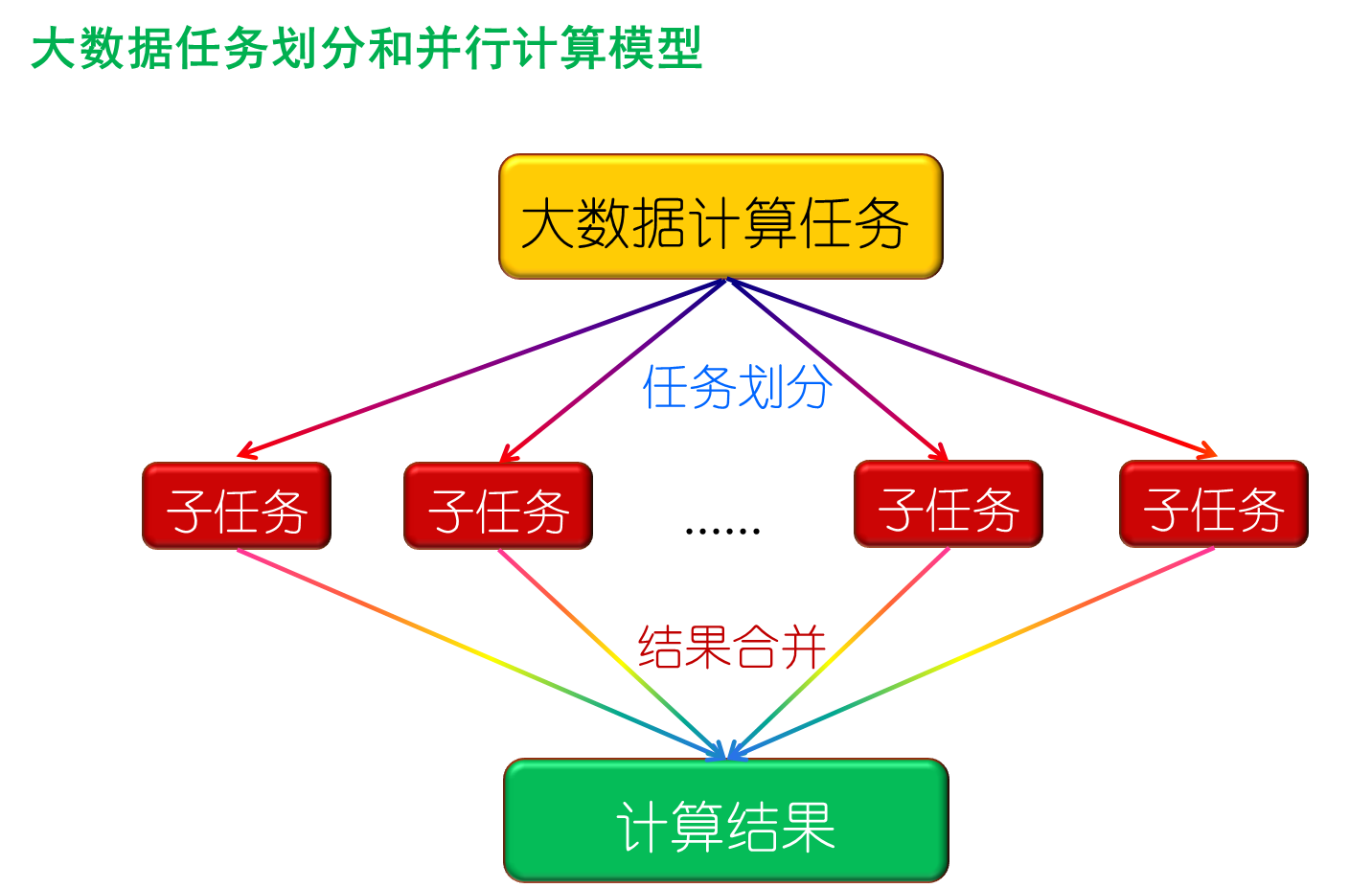
大数据任务划分和并行计算模型
不可拆分的计算任务或者相互之间有依赖关系的数据无法进行并行计算
抽象架构模型
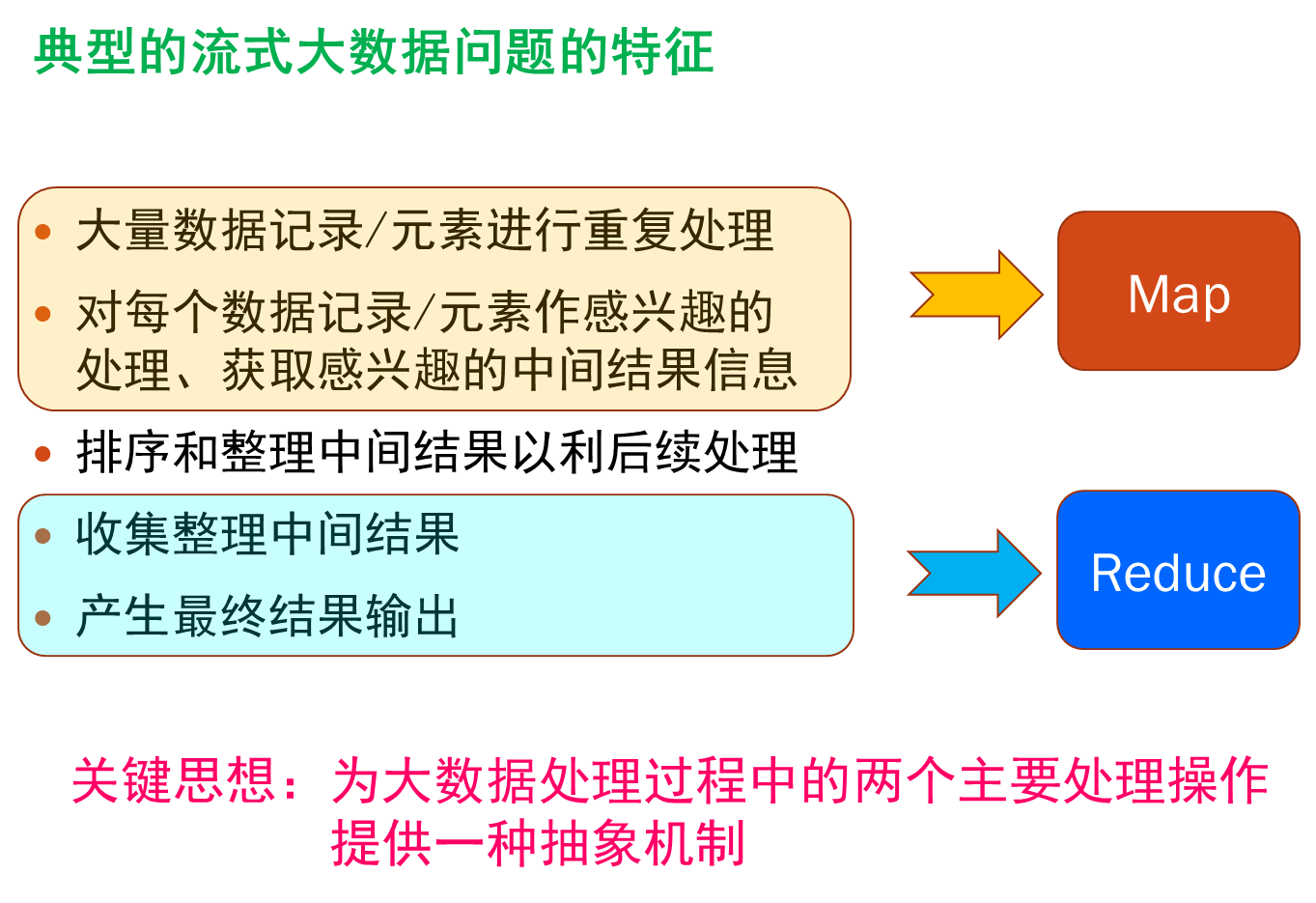
两个抽象编程接口
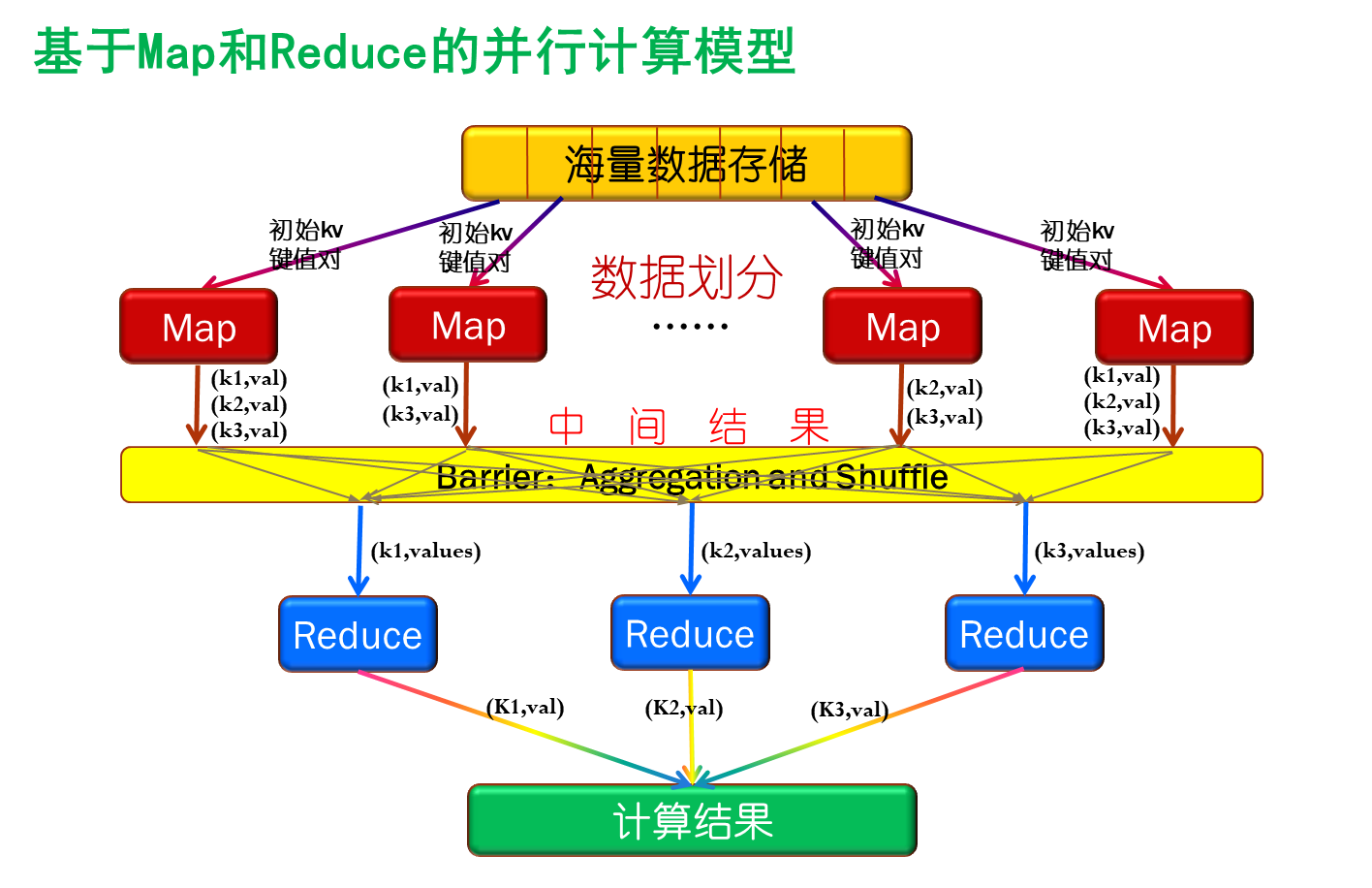
- Map节点对划分的数据进行并行处理,从不同的输入数据产生不同的中间结果输出
- Reduce节点也并行计算
- 进行reduce处理之前,必须等到所有的map函数都做完,因此在进入recudce之前需要一个同步障 Barrier ;这个阶段也负责对amp的中间结果进行收集和整理,以便reduce有效地计算最终结果
- 汇总所有reduce的输出结果即获得最终结果
MapReduce框架 自动并行化隐藏底层细节
MapReduce两点
- 为程序员提供了抽象和高层的编程接口和框架
- 程序员仅需要关心应用层计算问题
-
- 具体如何去完成并行计算任务所相关的诸多系统层的细节被隐藏起来,交给计算矿机去处理
MapReduce 提供的主要功能
- 任务调度:将一个计算作业 job 划分成许多计算任务 task,为task 分配调度计算节点。
- 数据/代码互定位:为减少数据通信,一个基本原则是本地化数据处理,实现代码向数据迁移。当无法完成本地化数据处理是,在寻找其他可用节点,并数据通过网络传送给该节点,数据向代码迁移,单应尽量从数据所在机架上寻找可用节点以减少通讯延迟。
- 出错处理:
- 分布式数据存储和文件管理
- Combiner和Patitioner
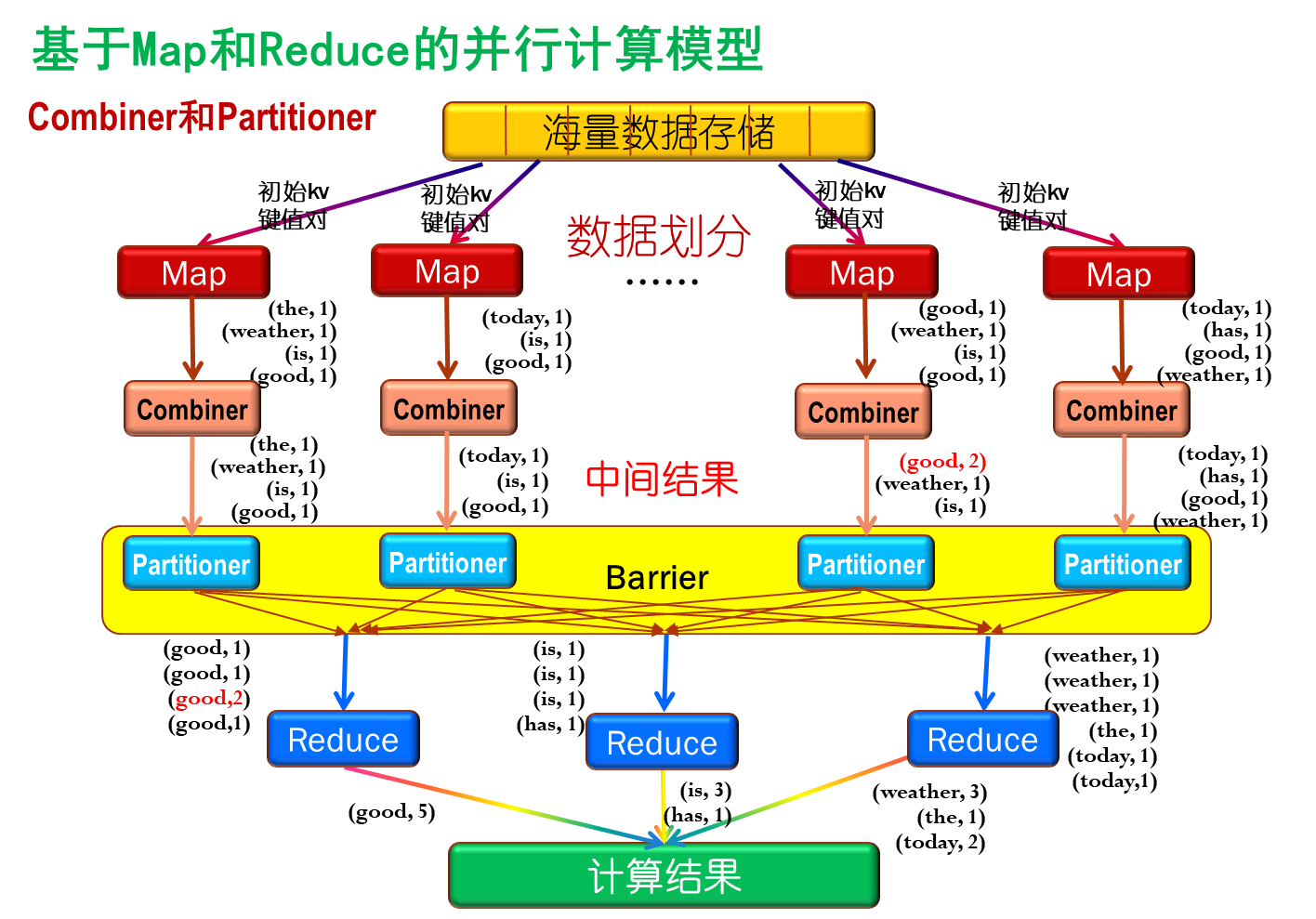
Combiner: 合并相同主键的键值对,减少网络传输的开销,进行中间数据网络传输的优化工作。在map节点计算完成之后,输出中间结果之前进行。
Partitioner:对map输出的中间结果进行一定的划分,保证相关数据发送到同一个reduce节点。在map节点输出后,传入reduce结点之前完成。
MapReduce 主要设计思想和特点
- 失效被认为是常态
- 把处理向数据迁移
- 顺序处理数据、避免随机访问数据:顺序访问有高带宽
- 为应用开发者隐藏细节
MapReduce 的基本工作原理
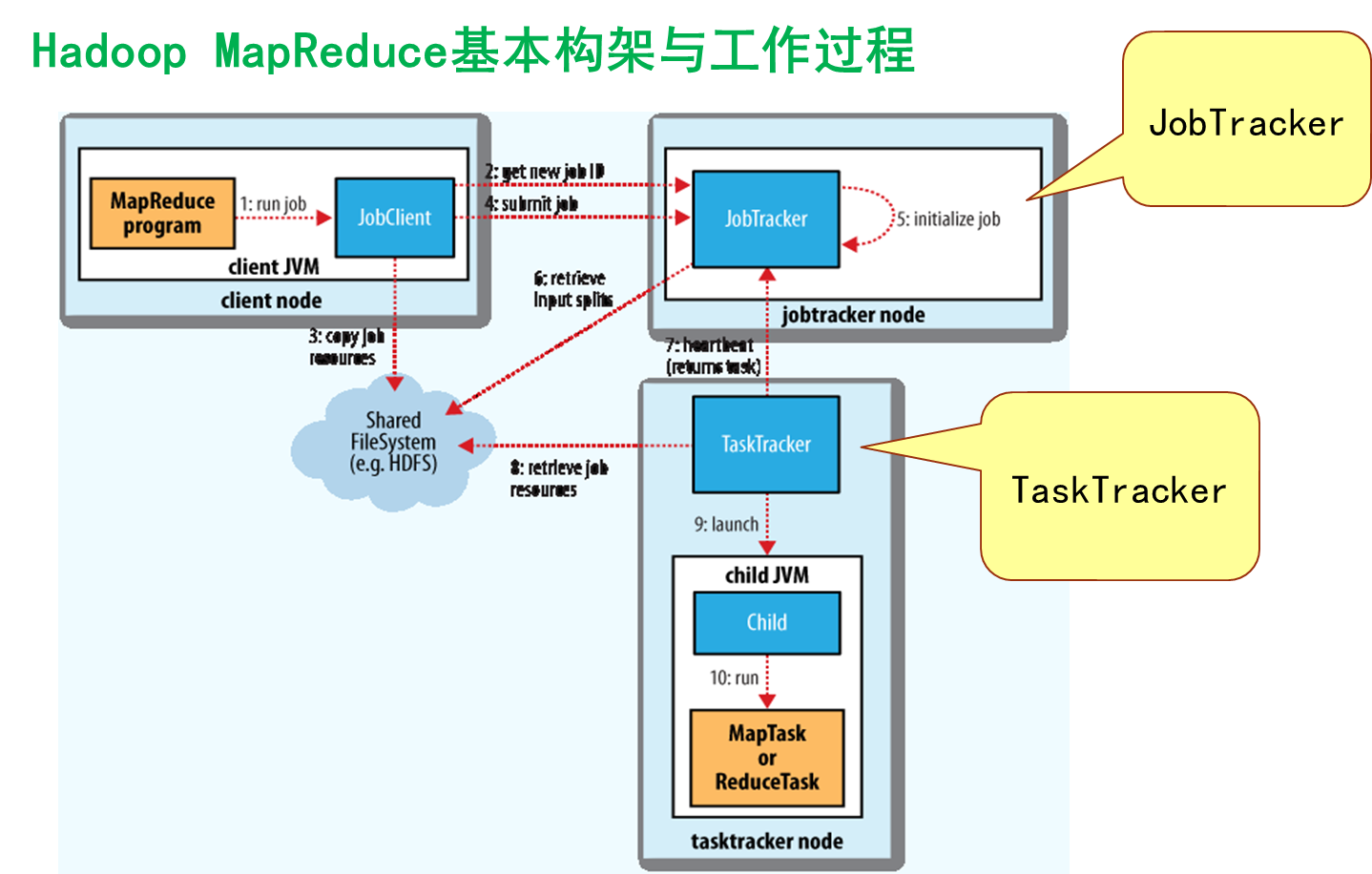
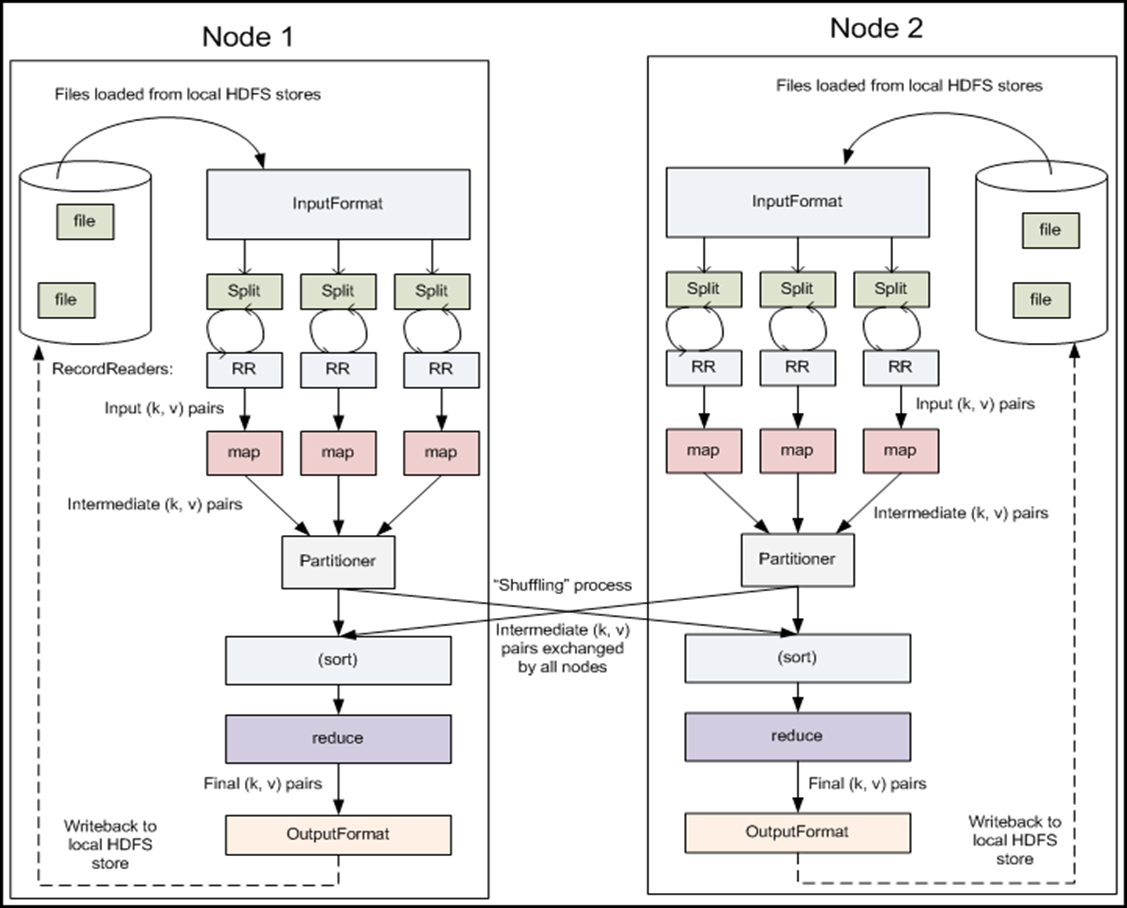
- 一个InputSplite将作为一个Mapper的输入,Mapper的数量由InputSplit的个数决定
- Split 与 block 的对应关系可能是多对一,默认为一对一
- sort :传输到每一个Reducer节点上的、将被所有的Reduce函数接收到的Key,value对会被Hadoop自动排序
Partitioner 中的问题
- 如何均匀划分,如何快速查找
全序划分TotalOrderPartition
- key的分布未知
- 预读一小部分数据采样
- 对采样数据排序后俊峰,假设有N个reducer,取N-1个分割点

高效的划分模型
partitioner构造一个两层的trie 树,根据 key的前两字节确定划分
构建单词的同现矩阵
- 同现定义: 相邻的两个词,在一个2-word 窗口同时出现的词
文档倒排索引
- Inverted Index:给出一个词term ,能取得含有这个 term 的文档列表
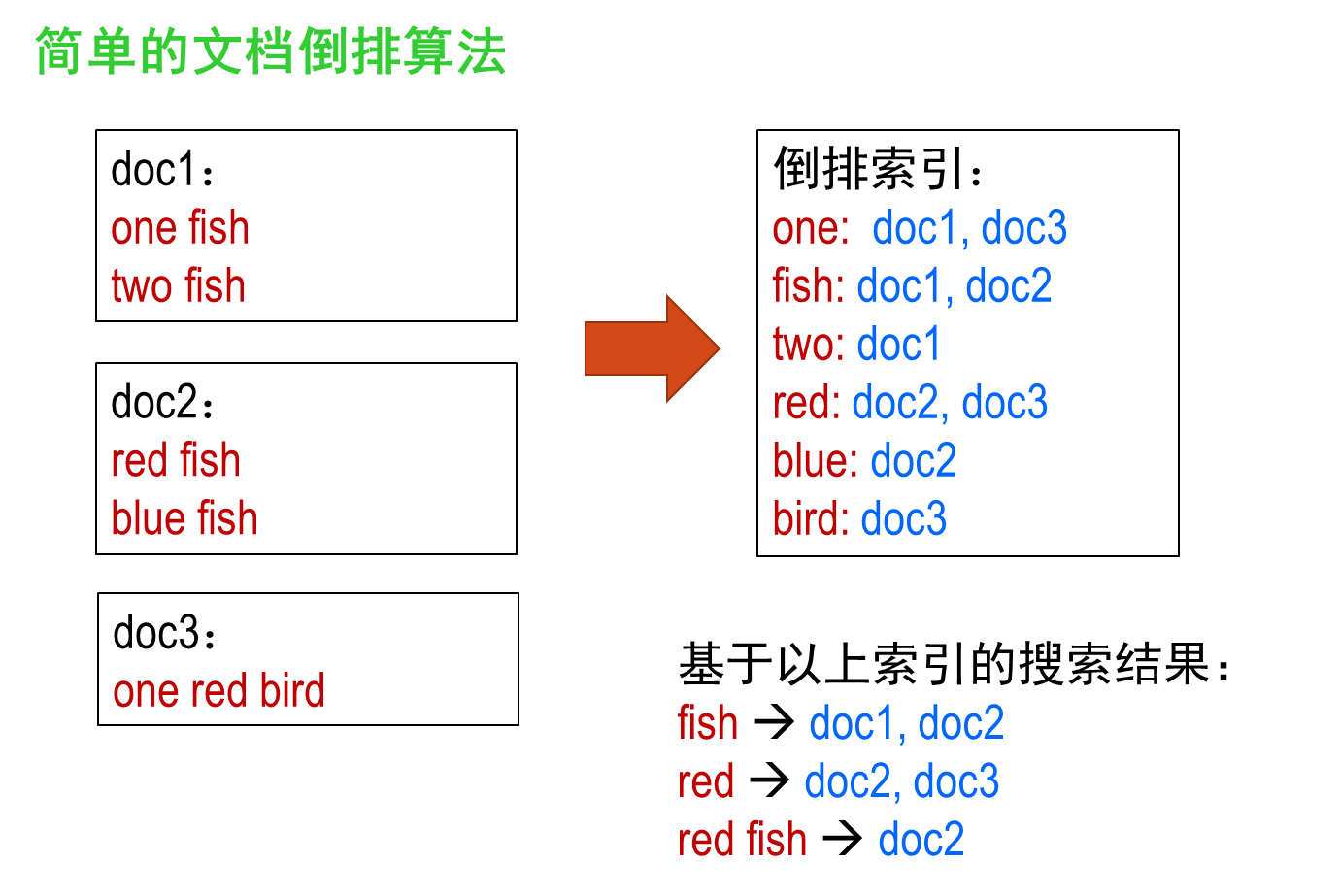
带有词频属性的倒排索引
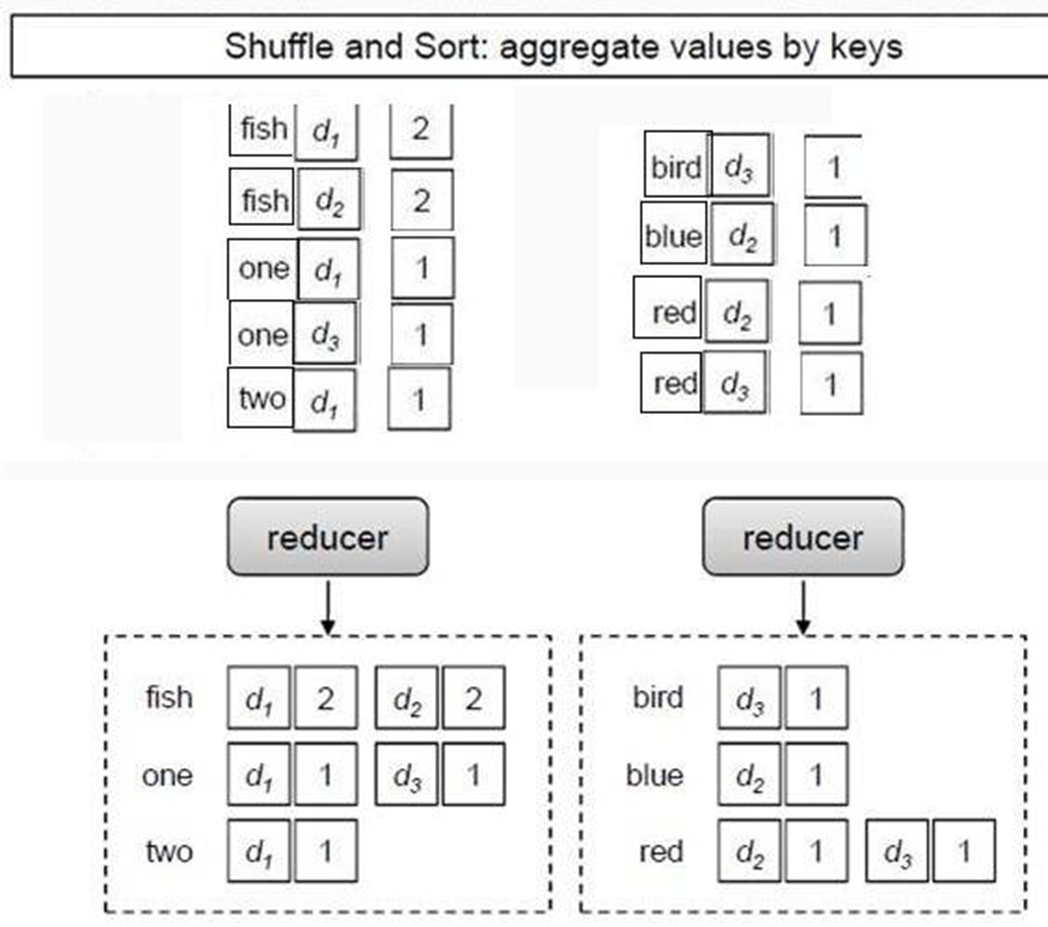
- 不能在 reduce 中完成排序,有可能会造成内存溢出
- 当键值对进行shuffle处理传向合适的Reducer时,按照 文件名进行排序
- 解决方案:maper 阶段输出的中介结果 <{term, 文件名},频次>,定制partition使得同一个term的键值会被分到同一个桶中
蒙骗partition:
将组合键 <term, docid> 临时拆开,蒙骗partition 按照 ,而不是<term,docid>进行分区,这样保证 相同term的一组键值对一定被分到同一个分区中

















 780
780











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









