







 本文详细介绍了NVIDIA Collective Operations中的AllReduce、Broadcast、Reduce和AllGather四种通信操作,包括它们的原理、示例和RingAllReduce、RingReduceScatter、RingAllGather等实际实现策略。这些技术在深度学习和分布式计算中至关重要。
本文详细介绍了NVIDIA Collective Operations中的AllReduce、Broadcast、Reduce和AllGather四种通信操作,包括它们的原理、示例和RingAllReduce、RingReduceScatter、RingAllGather等实际实现策略。这些技术在深度学习和分布式计算中至关重要。
集合通信 Collective Operations
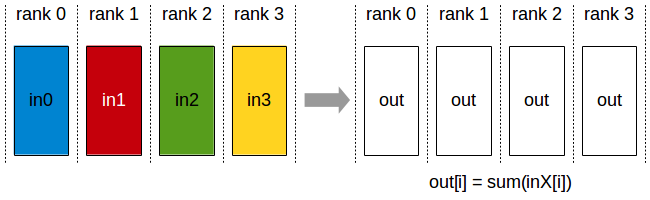
AllReduce
ncclResult_t ncclBroadcast(const void* sendbuff, void* recvbuff, size_t count, ncclDataType_t datatype, int root, ncclComm_t comm, cudaStream_t stream)
- N 个设备参加的AllReduce,没有root,初始状态下,所有的N个设备上sendbuffer 长度为 count(函数中定义 size_t count),N个sendbuffer中的内容记为 in_0,in_1,…,in_N-1, 运行结束后,所有sendbuffer中内容经过op操作,使得N个设备上的recv buffer中有相同的结果副本,长度均为count,即out。
- 以op操作为ncclSum为例, out[i] 来自于所有sendbuffer的 in_k[i] 的和,即 out[i] = sum(in_k[i])
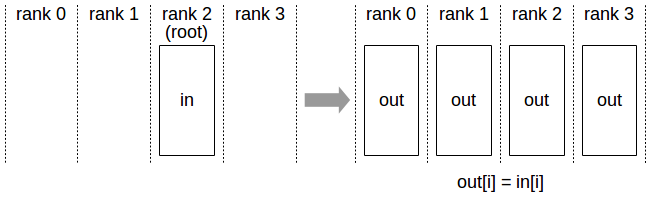
Broadcast
ncclResult_t ncclBroadcast(const void* sendbuff, void* recvbuff, size_t count, ncclDataType_t datatype, int root, ncclComm_t comm, cudaStream_t stream)
N个设备参与的broadcast,root 是 函数中指定的 int root(以上图为例则是2),初始状态下,rank 为 root(上图中2)的设备上的send buffer 长度为count。运行结束后,所有参与broadcast 的N个设备上的recv buffer 长度为 count, 且所有N个rank 的 recv buffer 部分的数据均来自于 root设备的send buffer 的拷贝。
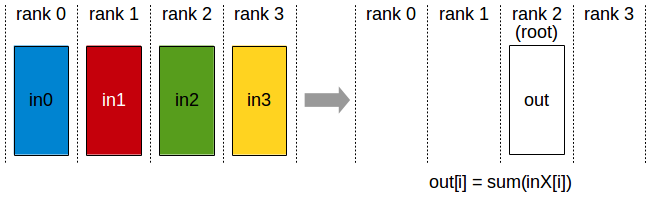
Reduce
ncclResult_t ncclReduce(const void* sendbuff, void* recvbuff, size_t count, ncclDataType_t datatype, ncclRedOp_t op, int root, ncclComm_t comm, cudaStream_t stream)
- N个设备参与的reduce ,root 是 函数中指定的 int root(上图中为2),初始状态下,N个设备上的send buffer 长度为 count,记为数组 in_0,in_1,…in_N-1。 运行结束后,rank 为 root (上图中为2)的设备的recv buffer长度为count,记为数组out 。其中 recv buffer的数据来自于N个的send buffer经op操作后的结果。
- 以op操作为 ncclSum为例,out[i] 为各个send buffer 中 in_X[i] 的和,即out[i] = sum(in_X[i])
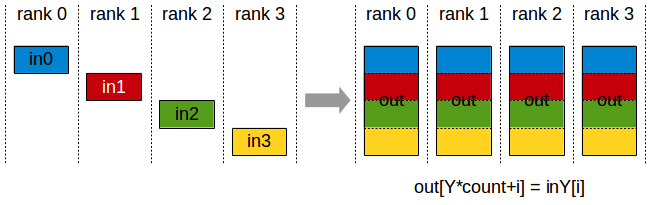
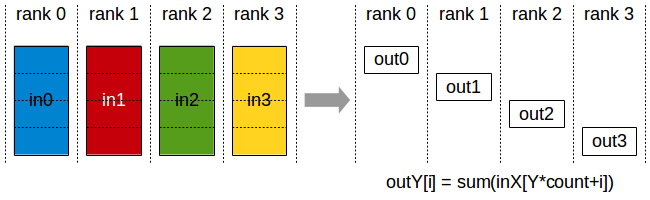
AllGather
ncclResult_t ncclAllGather(const void* sendbuff, void* recvbuff, size_t sendcount, ncclDataType_t datatype, ncclComm_t comm, cudaStream_t stream)
N个设备参与AllGather,没有root,初始状态下,N个设备上的send buffer 长度为 sendcount,记为数组 in_0,int_1,…,in_N-1,运行结束后,N个设备上的recv buffer 内容均相同,长度均为 N ∗ s e n d c o u n t N*sendcount N∗sendcount,记为 数组out 。其中每个设备上的recv buffer中的 o u t [ Y ∗ s e n d c o u t + i ] out[Y*sendcout + i] out[Y∗sendcout+i]来自于rank为 Y 的设备的send buffer中的 in_Y[i] , 即 out[Y*count + i] = in_Y[i]
ReduceScatter
ncclResult_t ncclReduceScatter(const void* sendbuff, void* recvbuff, size_t recvcount, ncclDataType_t datatype, ncclRedOp_t op, ncclComm_t comm, cudaStream_t stream)
- N 个设备参与的ReduceScatter,没有root设备。初始状态下,N个设备的sendbuffer 长度均为 N*recvcount。运行结束后,N个设备的recv buffer长度为 recvcount,记为数组out_0,out_1,…,out_N-1。其中,N个 send buffer中数据经过op 操作得到 reduced result,将其散布在 N 个设备中,每个设备仅包含 reduced result中一部分。
- 以op操作为 ncclSum为例, rank为Y的设备中数据 out_Y[i] 为 reduced result 中 Yrecvcount+i 位置的数据,即 out_Y[i] = sum(in_X[Ycount + i])
集合通信的实现
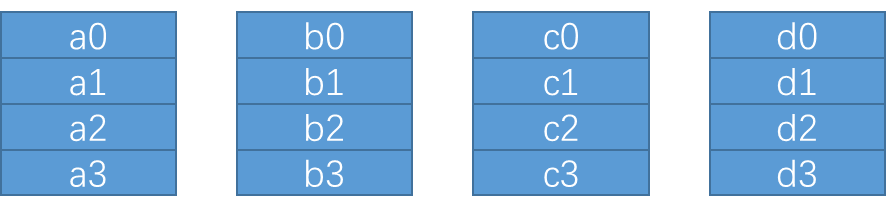
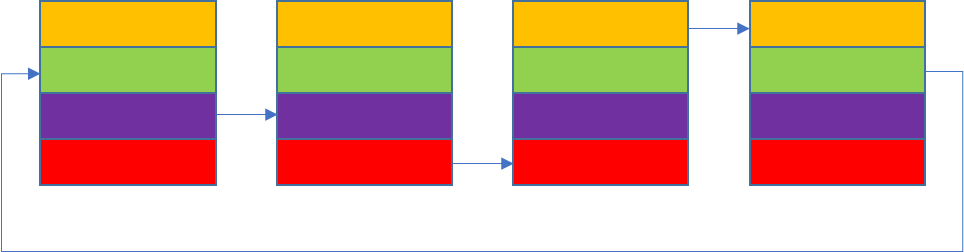
Ring AllReduce
Ring AllReduce
各个设备首尾相连,形成单向的环。每个环上处理一部分数据 block,NCCL 在 luanch kernel 时,会确定 block的数量,一个block对应一个环。
一个循环中AllReduce的实现:
-
一共有 k 各设备,将每个设备上的数据划分成等大的 k 个 chunk
-
step 0 当前设备的 rank 为 ringIx 则将 (ringIx + k -1 ) mod N 号 chunk 传给下一个设备
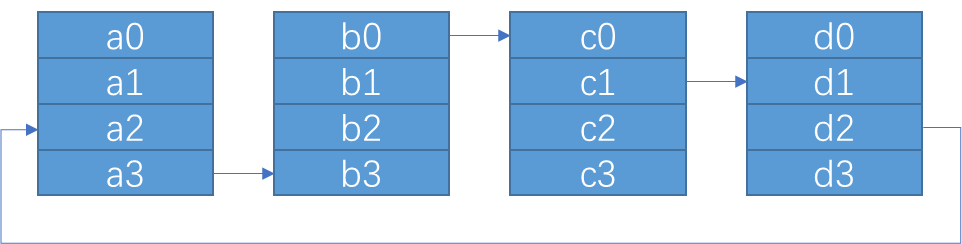
// step 0: push data to next GPU
chunk = modRanks(ringIx + nranks-1);
offset = calcOffset(chunk);
nelem = min(realChunkSize, size-offset);
prims.send(offset, nelem);
- 进行 K - 2 次循环,j 从2 遍历道 N-1; 每次循环将 接收该设备的 (ringIx + k - j ) mod N 作为 chunk_id ,进行reduce之后,传给下一个设备
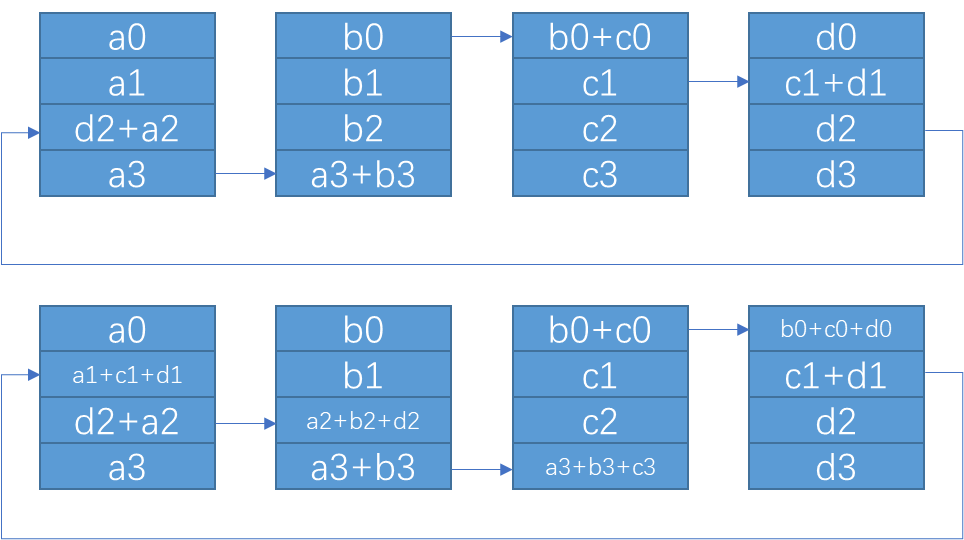
// k-2 steps: reduce and copy to next GPU
for (int j=2; j<nranks; ++j) {
chunk = modRanks(ringIx + nranks-j);
offset = calcOffset(chunk);
nelem = min(realChunkSize, size-offset);
prims.recvReduceSend(offset, nelem);
}
- step k-1 每个设备选择自己的 rank 作为 chunk_id,调用 directRecvReduceCopySend 接收 chunk,和 sendbuff 中对应的数据 reduce,此时的结果已经是该 chunk 所有 rank sendbuff 中的数据 reduce 之后的结果,将这个结果写入到 recvbuff ,并发送给下一个设备,因为下一步操作不需要再进行 reduce,所以可以使用 directSend。
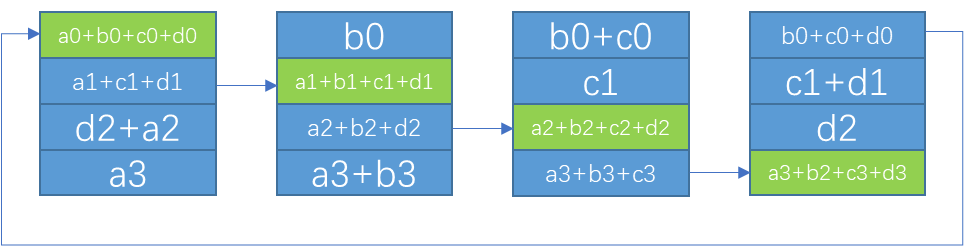
// step k-1: reduce this buffer and data, which will produce the final
// result that we store in this data and push to the next GPU
chunk = ringIx + 0;
offset = calcOffset(chunk);
nelem = min(realChunkSize, size-offset);
prims.directRecvReduceCopySend(offset, offset, offset, nelem, /*postOp=*/true);
- k-2 step 接收对应位置数据并发送给下一个设备
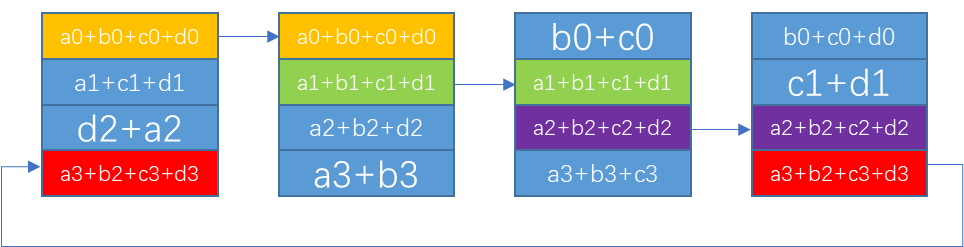
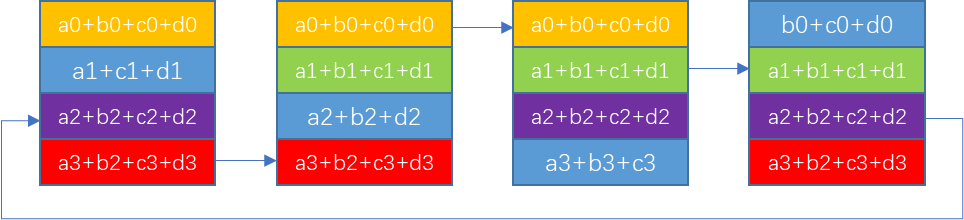
// k-2 steps: copy to next GPU
for (int j=1; j<nranks-1; ++j) {
chunk = modRanks(ringIx + nranks-j);
offset = calcOffset(chunk);
nelem = min(realChunkSize, size-offset);
prims.directRecvCopySend(offset, offset, nelem);
}
- 最后一步只需要接收数据,不需要发送
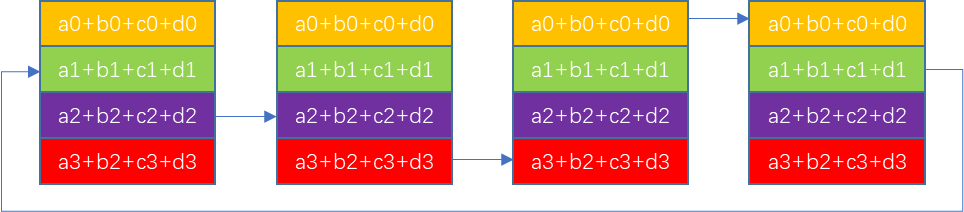
// Make final copy from buffer to dest.
chunk = modRanks(ringIx + 1);
offset = calcOffset(chunk);
nelem = min(realChunkSize, size-offset);
prims.directRecv(offset, nelem);
Ring ReduceScatter
和Ring AllReduce 前半部分很相似
/// begin ReduceScatter steps ///
ssize_t offset;
int nelem = min(realChunkSize, size-chunkOffset);
int rankDest;
// step 0: push data to next GPU
rankDest = ringRanks[nranks-1];
offset = chunkOffset + rankDest * size;
prims.send(offset, nelem);
// k-2 steps: reduce and copy to next GPU
for (int j=2; j<nranks; ++j) {
rankDest = ringRanks[nranks-j];
offset = chunkOffset + rankDest * size;
prims.recvReduceSend(offset, nelem);
}
// step k-1: reduce this buffer and data, which will produce the final result
rankDest = ringRanks[0];
offset = chunkOffset + rankDest * size;
prims.recvReduceCopy(offset, chunkOffset, nelem, /*postOp=*/true);
Ring AllGather
allGathre 和 allReduce 后半段过程很相似

/// begin AllGather steps ///
ssize_t offset;
int nelem = min(realChunkSize, size-chunkOffset);
int rankDest;
// step 0: push data to next GPU
rankDest = ringRanks[0];
offset = chunkOffset + rankDest * size;
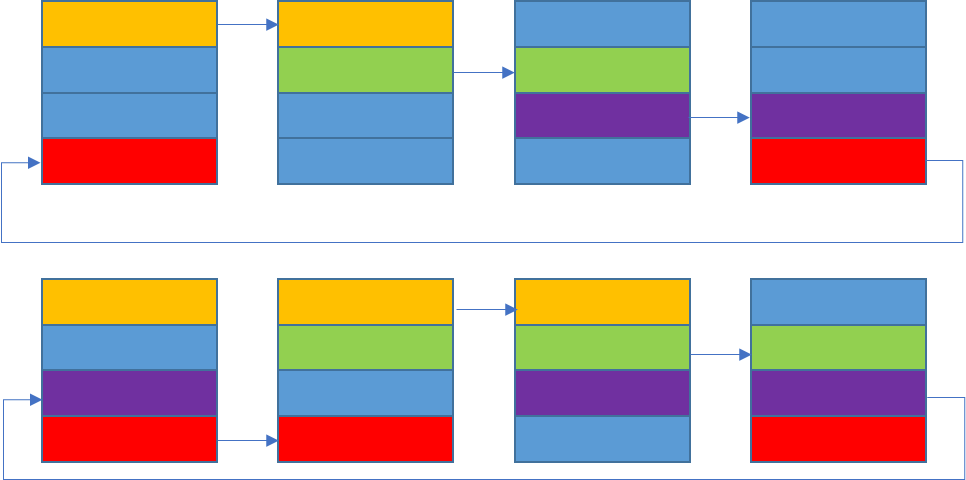
// k-2 steps: copy to next GPU
for (int j=1; j<nranks-1; ++j) {
rankDest = ringRanks[nranks-j];
offset = chunkOffset + rankDest * size;
prims.directRecvCopySend(offset, offset, nelem);
}
// Make final copy from buffer to dest.
rankDest = ringRanks[1];
offset = chunkOffset + rankDest * size;
// Final wait/copy.
prims.directRecv(offset, nelem);
Ring Reduce

if (prevRank == root) {
for (ssize_t gridOffset = 0; gridOffset < size; gridOffset += loopSize) {
int realChunkSize = calcChunkSize(gridOffset);
ssize_t offset = gridOffset + bid*realChunkSize;
int nelem = min(realChunkSize, size-offset);
prims.send(offset, nelem);
}
}


for (ssize_t gridOffset = 0; gridOffset < size; gridOffset += loopSize) {
int realChunkSize = calcChunkSize(gridOffset);
ssize_t offset = gridOffset + bid*realChunkSize;
int nelem = min(realChunkSize, size-offset);
prims.recvReduceSend(offset, nelem);
}

else if (rank == root) {
for (ssize_t gridOffset = 0; gridOffset < size; gridOffset += loopSize) {
int realChunkSize = calcChunkSize(gridOffset);
ssize_t offset = gridOffset + bid*realChunkSize;
int nelem = min(realChunkSize, size-offset);
prims.recvReduceCopy(offset, offset, nelem, /*postOp=*/true);
}
}
总的代码:
if (prevRank == root) {
for (ssize_t gridOffset = 0; gridOffset < size; gridOffset += loopSize) {
int realChunkSize = calcChunkSize(gridOffset);
ssize_t offset = gridOffset + bid*realChunkSize;
int nelem = min(realChunkSize, size-offset);
prims.send(offset, nelem);
}
}
else if (rank == root) {
for (ssize_t gridOffset = 0; gridOffset < size; gridOffset += loopSize) {
int realChunkSize = calcChunkSize(gridOffset);
ssize_t offset = gridOffset + bid*realChunkSize;
int nelem = min(realChunkSize, size-offset);
prims.recvReduceCopy(offset, offset, nelem, /*postOp=*/true);
}
}
else {
for (ssize_t gridOffset = 0; gridOffset < size; gridOffset += loopSize) {
int realChunkSize = calcChunkSize(gridOffset);
ssize_t offset = gridOffset + bid*realChunkSize;
int nelem = min(realChunkSize, size-offset);
prims.recvReduceSend(offset, nelem);
}
}
Tree AllReduce
Tree AllReduce算法,是把AllReduce拆成了reduce和broadcast
假设各设备建立的梳妆拓扑结构如下:
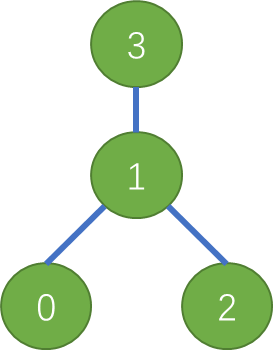
Up:Reduce阶段, 从叶子节点开始,向根节点发送数据:

if (tree->down[0] == -1) {
for (ssize_t gridOffset = 0; gridOffset < size; gridOffset += loopSize) {
ssize_t offset = gridOffset + bid*int(chunkSize);
int nelem = min(chunkSize, size-offset);
prims.send(offset, nelem);
}
}
非根节点,向父节点发送数据,同时进行reduce
for (ssize_t gridOffset = 0; gridOffset < size; gridOffset += loopSize) {
ssize_t offset = gridOffset + bid*int(chunkSize);
int nelem = min(chunkSize, size-offset);
prims.recvReduceSend(offset, nelem);
}
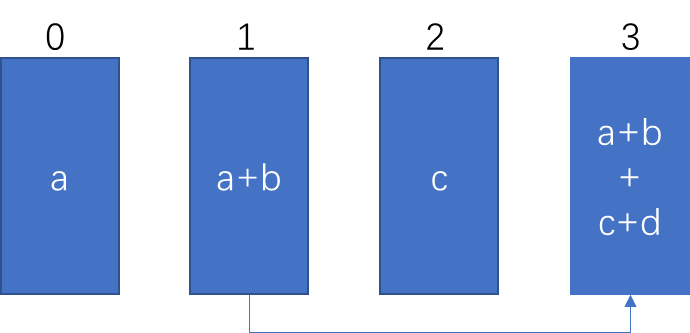
根节点接收数据,并执行reduce
if (tree->up == -1) {
for (ssize_t gridOffset = 0; gridOffset < size; gridOffset += loopSize) {
ssize_t offset = gridOffset + bid*int(chunkSize);
int nelem = min(chunkSize, size-offset);
prims.recvReduceCopy(offset, offset, nelem, /*postOp=*/true);
}
}
if (tree->up == -1) {
for (ssize_t gridOffset = 0; gridOffset < size; gridOffset += loopSize) {
ssize_t offset = gridOffset + bid*int(chunkSize);
int nelem = min(chunkSize, size-offset);
prims.recvReduceCopy(offset, offset, nelem, /*postOp=*/true);
}
}
else if (tree->down[0] == -1) {
for (ssize_t gridOffset = 0; gridOffset < size; gridOffset += loopSize) {
ssize_t offset = gridOffset + bid*int(chunkSize);
int nelem = min(chunkSize, size-offset);
prims.send(offset, nelem);
}
}
else {
for (ssize_t gridOffset = 0; gridOffset < size; gridOffset += loopSize) {
ssize_t offset = gridOffset + bid*int(chunkSize);
int nelem = min(chunkSize, size-offset);
prims.recvReduceSend(offset, nelem);
}
}
down:broadcast 阶段,从根节点开始,向外广播
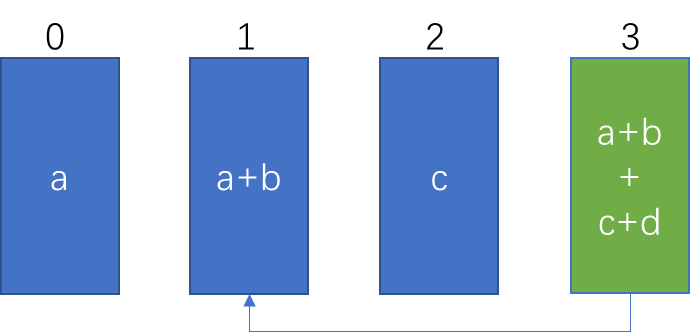
if (tree->up == -1) {
for (ssize_t gridOffset = 0; gridOffset < size; gridOffset += loopSize) {
ssize_t offset = gridOffset + bid*int(chunkSize);
int nelem = min(chunkSize, size-offset);
prims.directSendFromOutput(offset, offset, nelem);
}
}
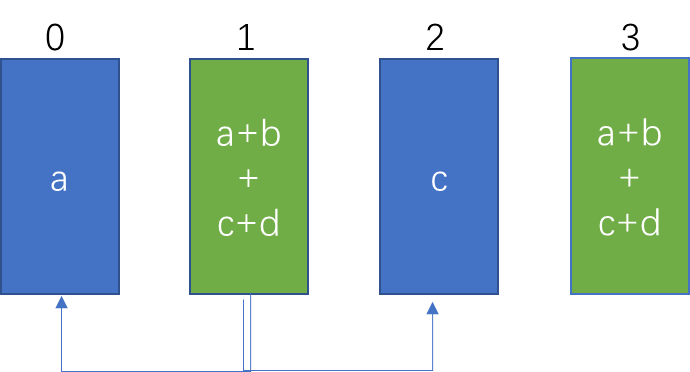
for (ssize_t gridOffset = 0; gridOffset < size; gridOffset += loopSize) {
ssize_t offset = gridOffset + bid*int(chunkSize);
int nelem = min(chunkSize, size-offset);
prims.directRecvCopySend(offset, offset, nelem);
}
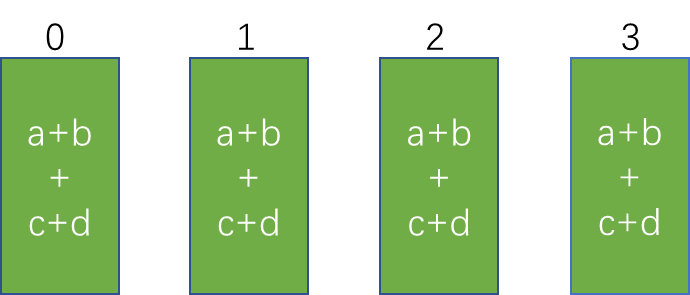
else if (tree->down[0] == -1) {
for (ssize_t gridOffset = 0; gridOffset < size; gridOffset += loopSize) {
ssize_t offset = gridOffset + bid*int(chunkSize);
int nelem = min(chunkSize, size-offset);
prims.directRecv(offset, nelem);
}
}

















 159
159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









