







Spark集群搭建
一、搭建Spark的准备环境
1、在实验中我使用的系统是Ubuntu14.04,是在虚拟机上远程访问服务器,是安装在服务器上的(因为自己电脑的配置没有服务器的高)。至于下载地址,可以在Ubuntu官网上自行下载。
2、因为Spark的运行需要在HDFS分布式系统上运行,这样就不可避免的需要搭建Hadoop集群,并且需要yarn的支持。所以需要先搭建hadoop,因为之前我已经搭建好了hadoop集群。实验中使用的是hadoop2.7.1版本。
3、需要安装Scala,因为后边会用到它来编写程序,并且Spark的源代码也是用Scala编写的。(搭建hadoop集群的时候已经安装过了Scala,所以这里不再介绍)
4、下载Spark,实验中我使用的是Spark2.1.0的最新版本。(spark-2.1.0-bin-hadoop2.7.1.tgz)下载地址:
http://mirror.bit.edu.cn/apache/spark/
二、安装spark
1、先说一下,Master和Slave们的IP地址
|
59.67.77.12
|
Master
|
|
59.67.77.15
|
Slave1
|
|
59.67.77.16
|
Slave2
|
|
59.67.77.17
|
Slave3
|
2、在Master上搭建spark
将下载好的spark解压,解压到 /usr/local/文件夹(刚才下载好的spark是在之文件夹中的)如图所示:
$ sudo tar -zxf spsrk-2.1.0-bin-hadoop2.7.tgz -C /usr/local
$ cd /usr/local
$ ls
然后通过ls命令查看到/usr/local 文件夹内的文件:

由于spark的名字太长了,看着不舒服,那就改改吧(
![]() )
)
$ sudo mv spark-2.1.0-bin-hadoop2.7/ spark/
$ ls

这次看着没那么长的名字了吧,看着爽歪歪,哈哈!!! 先别着急最好给spark文件夹也修改一下权限
$ sudo chown -R hadoop:hadoop spark
修改spark的环境变量(非常重要,没有这个环境变量,后边的所有操作都没有任何意义的。就像Windows的环境变量一样需要修改)
需要在/etc/profile文件内编辑
$ sudo gedit /etc/profile
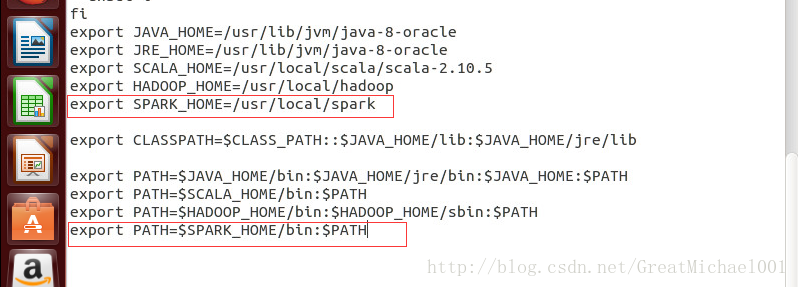
在文档的后边添加spark的环境变量
|
export SPARK_HOME
=/usr/local/
spark
export
PATH
=
$SPARK_HOME/bin
:
$PATH
|
下边这条命令让它立即生效
$ source /etc/profile
配置完了环境变量是不是就可以了,当然不是我们还要修改hadoop-env.sh .template文件。这个文件名看着怎么这么别扭,给他改一个名字,把后边的template去掉。
$ cd /usr/local/spark/conf
$ ls
$ gedit hadoop-env.sh

因为刚才修改了spark文件的权限,所以现在可以直接在文件夹下重命名。不用再命令行修改,如果喜欢,你可以用命令行修改。

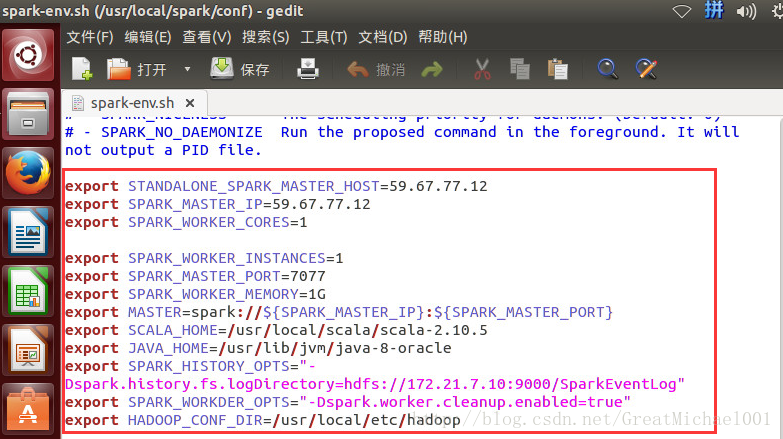
修改 spark-env.sh 文件内容如下,也就值在文件的尾部添加如下代码:
|
export STANDALONE_SPARK_MASTER_HOST=59.67.77.12
export SPARK_MASTER_IP=59.67.77.12
export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_MEMORY=1G
export SPARK_MASTER_PORT=7077
export MASTER=spark://${SPARK_MASTER_IP}:${SPARK_MASTER_PORT}
export SCALA_HOME=/usr/local/scala/scala-2.10.5
export JAVA_HOME=/usr/lib/jvm/java-8-oracleexport SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://172.21.7.10:9000/SparkEventLog" export SPARK_WORKDER_OPTS="-Dspark.worker.cleanup.enabled=true"
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
|
最后就是修改salves 文件的内容:

接下来基本就可以了,但是我们还要创建一个临时文件并且分配给管理员权限:
$ sudo mkdir logs
$ sudo chmod 777 logs
如图所示:

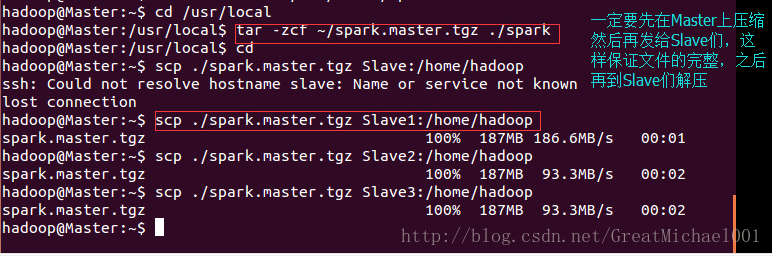
此时此刻,Master节点的配置已经完成。那么接下来的任务就是把刚才配置好的spark文件发送个slave们吧。(注意:此时千万别直接发送给slave们,因为直接发送容易丢失文件,最后的解决方法就是先在Master节点上压缩,把压缩包发送给slave们,然后再在slave们上解压到指定位置就OK了!)
在Master上压缩文件,把spark文件压缩成:spark.master.tgz包
$ tar -zcf ~/spark.master.tgz ./spark #压缩spark文件为 spark.master.tgz包
$ cd
$ scp ./spark.master.tgz Slave1:/home/hadoop # 解压文件到Slave1节点上的hadoop用户的主文件夹内
接下来就是在各个slave们上进行解压,解压到指定的文件夹下。
$ sudo tar -zxf ~/spark.master.tgz -C /usr/local # 把刚才传过来的压缩包解压到指定文件夹下
$ sudo chown -R hadoop /usr/local/spark # 更改hadoop用户里 /usr/local/spark/文件夹得权限

最后修改一下slave们的环境变量(知道在Master上怎么修改环境变量吧。对头,在slave们上也是同样的修改!!然后让其生效)
好吧!接下来就是奇迹发生的时刻:
先开启hadoop(注意:这个必须要在Master上执行。)
$ start-dfs.sh
$ start-yarn.sh
通过jps可以查看slave们节点所启动的进程。如果正确的话在Master上会出现如图所示:

最最后当然是开启spark了,前面都配置好,最后当然就开启spark了。。。
同样也是在Master节点上开启了
$ cd /usr/local/spark #切换到spark文件夹下
$ ./sbin/start-all.sh #开启spark
如图所示:

下面我们开始测试一下是否成功
$ jps

哈哈哈成功了。然后我们切换到slave2下测试一下,此时此刻我们在Master上用命令切换到slave2上
$ ssh Slave2
$ jps

输入:
$ exit
就可以退回到Master
到此spark的集群搭建就结束,但是别忘了完毕守护进程
$ stop-yarn.sh
$ stop-dfs.sh
$ cd /usr/local/spark
$ ./sbin/stop-all.sh
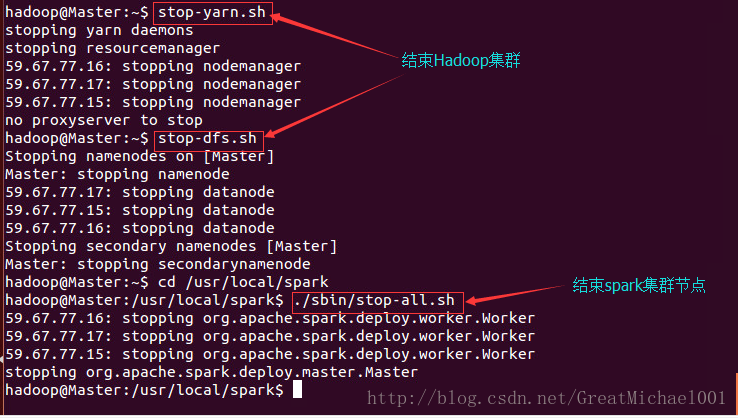
到这里spark的集群搭建就全部讲解完毕,这是我亲身试过的,所有的代码和程序都跑过,所以请大胆是玩转spark吧!!
![]()















 2406
2406











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









