







实验目的:
通过该实验后,能掌握以下知识:
1 能够手动搭建Spark集群
2 能使用Spark Shell
实验说明:
本实验环境中已经配置好Hadoop集群环境和spark on yarn的运行环境,只需要在主服务器(namenode)上执行hdfs namenode -format 格式化命令后启动Hadoop集群。
本次搭建的Spark将使用Hadoop YARN作为集群的资源管理器。所以其需要基于Hadoop集群环境。
实验步骤:
步骤一:启动Hadoop集群
进入到hadoop目录下,执行命令bin/hdfs namenode -format,进行格式化(首次启动需格式化),然后再执行sbin/./start-all.sh启动 Hadoop集群。使用jps命令查看服务。

查看主服务器服务

查看俩个从服务器服务

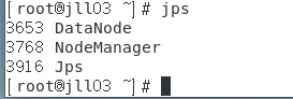
步骤二:
通过远程传输工具上传spark安装包,并进行解压


注:解压好spark包需在/etc/profile中配置spark环境变量,具体见“笔记”中配置环境变
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4535
4535











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









