







文章目录
- HashMap
- 1、数据结构
- 2、利用反射机制获取容量,阈值,元素个数
- 3、put流程
- 4、HashMap怎么设定初始容量大小的吗?
- 5、HashMap的哈希函数怎么设计的吗?
- 6、那你知道为什么这么设计吗?
- 7、为什么采用hashcode的高16位和低16位异或能降低hash碰撞?hash函数能不能直接用key的hashcode?
- 8、1.8对hash函数做了优化,1.8还有别的优化吗?
- 9、为什么要做这几点优化
- 10、那HashMap是线程安全的吗?
- 11、那你平常怎么解决这个线程不安全的问题?
- 12、那有没有有序的Map?
- 13、TreeMap怎么实现有序的?LinkedHashMap怎么实现有序的?
- 14、hashmap为什么是线程不安全?
- 15、为什么初始化容量为16
- 16、为什么负载因子是0.75
- 17、HashMap允许空键空值么
- 18、影响HashMap性能的重要参数
- 19、HashMap的工作原理
- 20、HashMap 的底层数组长度为何总是2的n次方
- 21、为什么1.8改用红黑树
- 22、1.8中的扩容为什么逻辑判断更简单
- 23、hashmap重复数据校验
- 24、何时链表转换为红黑树
- 25、HashMap 和 ConcurrentHashMap 的区别
- 26、平时开发中遍历HashMap方案有哪些
- 27、hashmap遍历修改数据
- 28、谈一下hashmap扩容机制
- hashmap如何解决hash冲突
- ArrayList
- 29、ArrayList理解,谈谈你的理解(重点)
- 30、说说ArrayList为什么增删慢
- 31、ArrayList的底层实现是数组,但是数组的⼤⼩是定⻓的,如果我们不断的往⾥⾯添加数据的话,不会有问题吗?
- 32、ArrayList常用方法
- 33、ArrayList⽤来做队列合适么
- 34、可以手写一个ArrayList的简单实现
- 35、你什么时候要选择 ArrayList,什么时候选择 LinkedList
- 36、ArrayList中elementData为什么被transient修饰
- 37、ArrayList添加第一个元素过程
- 38、ArrayList扩容机制说一下
- 39、ArrayList 底层实现就是数组,访问速度本身就很快,为何还要实现 RandomAccess
- 40、`ArrayList` 中的 `elementData` 为什么是 `Object` 而不是泛型 `E`
- 41、`ArrayList `的插入删除一定慢么?
- 42、`ArrayList`默认容量
- 43、遍历一个 `List `有哪些不同的方式 每种方法的实现原理是什么 `Java `中 `List `遍历的最佳实践是什么
- 44、说一下 `ArrayList `的优缺点
- 45、如何实现数组和 `List` 之间的转换
- 46、`ArrayList`与`LinkedList`区别
- 47、多线程场景下如何使用 `ArrayList`
- 48、为什么 `ArrayList` 的 `elementData` 加上 `transient` 修饰?
- 49、`ArrayList`是线程安全的么?
- 50、初始化`ArrayList`几种方案
- 51、list遍历几种方案
- 52、`ArrayList`对于删除元素特殊处理
- 53、`ArrayList`对于添加删除元素操作
- 54、`ArrayList`中`modCount`的作用
- 55、`ArrayList`删除重复数据
- `ConcurrentHashmap`
HashMap
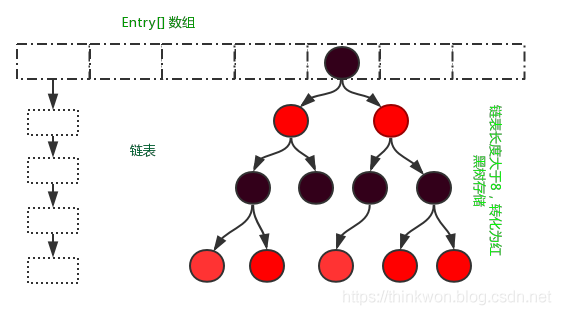
1、数据结构
HashMap是数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的即哈希表和红黑树
首先有一个每个元素都是链表(可能表述不准确)的数组,当添加一个元素(key-value)时,就首先计算元素key的hash值,以此确定插入数组中的位置,但是可能存在同一hash值的元素已经被放在数组同一位置了,这时就添加到同一hash值的元素的后面,他们在数组的同一位置,但是形成了链表,同一各链表上的Hash值是相同的,所以说数组存放的是链表。而当链表长度太长时,链表就转换为红黑树,这样大大提高了查找的效率
当链表数组的容量超过初始容量的0.75时,再散列将链表数组扩大2倍,把原链表数组的搬移到新的数组中
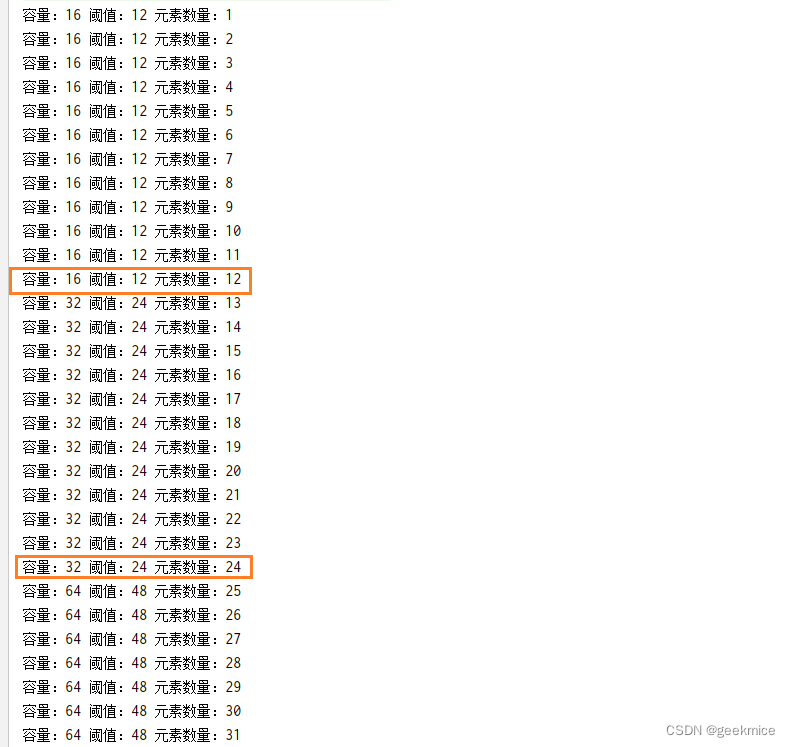
2、利用反射机制获取容量,阈值,元素个数
public class HashMapT {
public static void main(String[] args) throws Exception {
//指定初始容量15来创建一个HashMap
HashMap m = new HashMap();
//获取HashMap整个类
Class<?> mapType = m.getClass();
//获取指定属性,也可以调用getDeclaredFields()方法获取属性数组
Field threshold = mapType.getDeclaredField("threshold");
//将目标属性设置为可以访问
threshold.setAccessible(true);
//获取指定方法,因为HashMap没有容量这个属性,但是capacity方法会返回容量值
Method capacity = mapType.getDeclaredMethod("capacity");
//设置目标方法为可访问
capacity.setAccessible(true);
//打印刚初始化的HashMap的容量、阈值和元素数量
System.out.println("容量:" + capacity.invoke(m) + " 阈值:" + threshold.get(m) + " 元素数量:" +m.size());
for (int i = 0; i < 30; i++) {
m.put(i, i);
//动态监测HashMap的容量、阈值和元素数量
System.out.println("容量:" + capacity.invoke(m) + " 阈值:" + threshold.get(m) + " 元素数量:" +m.size());
}
}
}
3、put流程
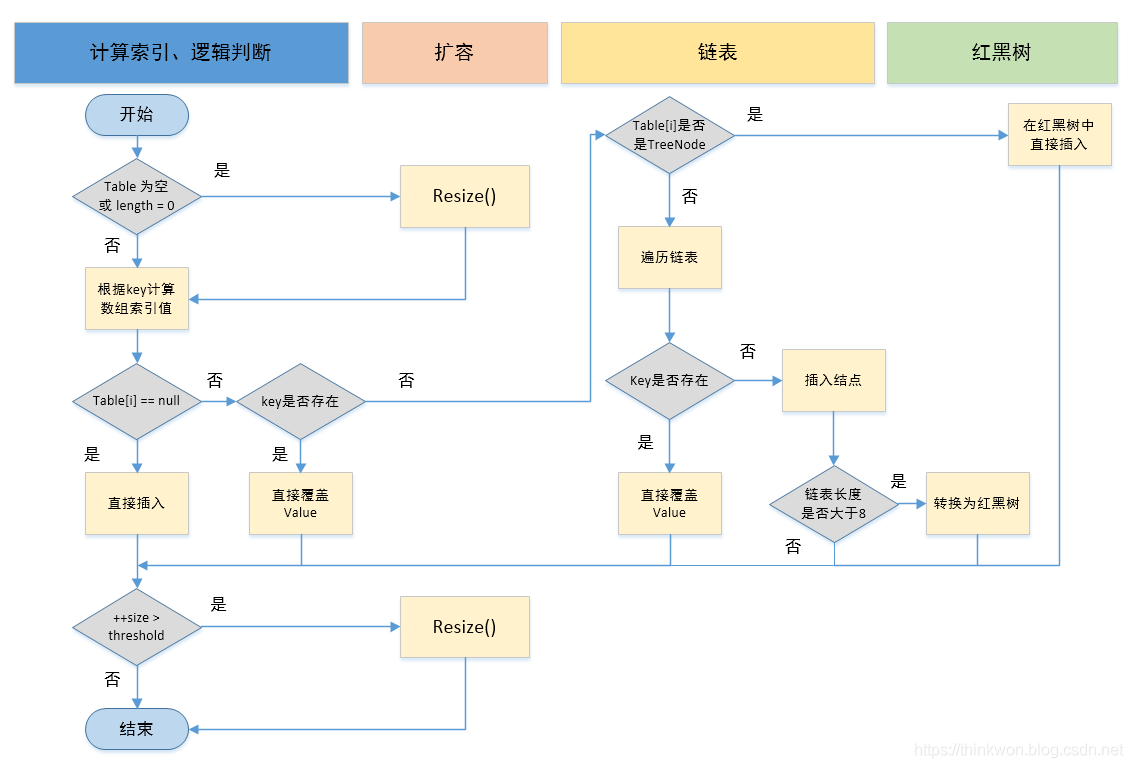
- 判断数组是否为空,为空进行初始化;
- 不为空,计算 k 的 hash 值,通过
(n - 1) & hash计算应当存放在数组中的下标 index; - 查看 table[index] 是否存在数据,没有数据就构造一个Node节点存放在 table[index] 中;
- 存在数据,说明发生了hash冲突(存在二个节点key的hash值一样), 继续判断key是否相等,相等,用新的value替换原数据(onlyIfAbsent为false);
- 如果不相等,判断当前节点类型是不是树型节点,如果是树型节点,创造树型节点插入红黑树中;(如果当前节点是树型节点证明当前已经是红黑树了)
- 如果不是树型节点,创建普通Node加入链表中;判断链表长度是否大于 8并且数组长度大于64, 大于的话链表转换为红黑树;
- 插入完成之后判断当前节点数是否大于阈值,如果大于开始扩容为原数组的二倍。
4、HashMap怎么设定初始容量大小的吗?
一般如果new HashMap() 不传值,默认大小是16,负载因子是0.75, 如果自己传入初始大小k,初始化大小为 大于k的 2的整数次方,例如如果传10,大小为16。
5、HashMap的哈希函数怎么设计的吗?
hash函数是先拿到 key 的hashcode,是一个32位的int值,然后让hashcode的高16位和低16位进行异或操作
6、那你知道为什么这么设计吗?
-
一定要尽可能降低hash碰撞,越分散越好;
-
算法一定要尽可能高效,因为这是高频操作, 因此采用位运算;
7、为什么采用hashcode的高16位和低16位异或能降低hash碰撞?hash函数能不能直接用key的hashcode?
1、原因:当数组的长度很短时,只有低位数的hashcode值能参与运算。而让高16位参与运算可以更好的均匀散列,减少碰撞,进一步降低hash冲突的几率。并且使得高16位和低16位的信息都被保留了
2、因为key.hashCode()函数调用的是key键值类型自带的哈希函数,返回int型散列值。int值范围为-2 ^32 =>+2^32 或者**-2147483648~2147483647**,前后加起来大概40亿的映射空间。只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但问题是一个40亿长度的数组,内存是放不下的。你想,如果HashMap数组的初始大小才16,用之前需要对数组的长度取模运算,得到的余数才能用来访问数组下标。
8、1.8对hash函数做了优化,1.8还有别的优化吗?
- 数组+链表改成了数组+链表或红黑树;
- 链表的插入方式从头插法改成了尾插法,简单说就是插入时,如果数组位置上已经有元素,1.7将新元素放到数组中,原始节点作为新节点的后继节点,1.8遍历链表,将元素放置到链表的最后;
- 扩容的时候1.7需要对原数组中的元素进行重新hash定位在新数组的位置,1.8采用更简单的判断逻辑,位置不变或索引+旧容量大小;
- 在插入时,1.7先判断是否需要扩容,再插入,1.8先进行插入,插入完成再判断是否需要扩容;
9、为什么要做这几点优化
-
防止发生hash冲突,链表长度过长,将时间复杂度由
O(n)降为O(logn); -
因为1.7头插法扩容时,头插法会使链表发生反转,多线程环境下会产生环;
10、那HashMap是线程安全的吗?
不是,在多线程环境下,1.7 会产生死循环、数据丢失、数据覆盖的问题,1.8 中会有数据覆盖的问题,以1.8为例,当A线程判断index位置为空后正好挂起,B线程开始往index位置的写入节点数据,这时A线程恢复现场,执行赋值操作,就把A线程的数据给覆盖了;还有++size这个地方也会造成多线程同时扩容等问题。
JDK 7 的 HashMap 解决冲突用的是拉链法,在拉链的时候用的是头插,每次在链表的头部插入新元素。resize() 的时候用的依然是头插,头插的话,如果某个下标中的链表在新的 table 中依然索引到同一个下标中,那么原链表的顺序会反转。因为链表是顺序访问的,那么每次访问一个节点,会把当前节点插到新 table 链表的头部,这样原链表的最后一个元素在 resize() 后,就变成新链表的头部了(如果它们索引到新 table 的同一个下标中)。这在并发的情况下可能产生环。
11、那你平常怎么解决这个线程不安全的问题?
Java中有HashTable、Collections.synchronizedMap、以及ConcurrentHashMap可以实现线程安全的Map
12、那有没有有序的Map?
LinkedHashMap 和 TreeMap
13、TreeMap怎么实现有序的?LinkedHashMap怎么实现有序的?
TreeMap是按照Key的自然顺序或者Comprator的顺序进行排序,内部是通过红黑树来实现。所以要么key所属的类实现Comparable接口,或者自定义一个实现了Comparator接口的比较器,传给TreeMap用于key的比较;如果是字符串类型,一个个字符ASCII比较,数字类型的话,按照从小到大排列(自然排序);
// key 为 string类型
String s = new String();
t3(s);
// key 为 bigdecimal类型
BigDecimal bigDecimal = new BigDecimal("1");
t3(bigDecimal);
@Test
public void t3(Object obj) {
TreeMap<Object, Object> map = new TreeMap<>(new Comparator<Object>() {
@Override
public int compare(Object o1, Object o2) {
if (o1 instanceof String && o2 instanceof String) {
return ((String) o1).compareTo((String) o2);
} else if (o1 instanceof BigDecimal && o2 instanceof BigDecimal) {
return ((BigDecimal) o1).compareTo((BigDecimal) o2);
}
return 0;
}
});
for (int i = 1; i < 20; i++) {
if (obj instanceof String) {
map.put(String.valueOf(i), String.valueOf(i));
}
if (obj instanceof BigDecimal) {
map.put(BigDecimal.valueOf(i), BigDecimal.valueOf(i));
}
}
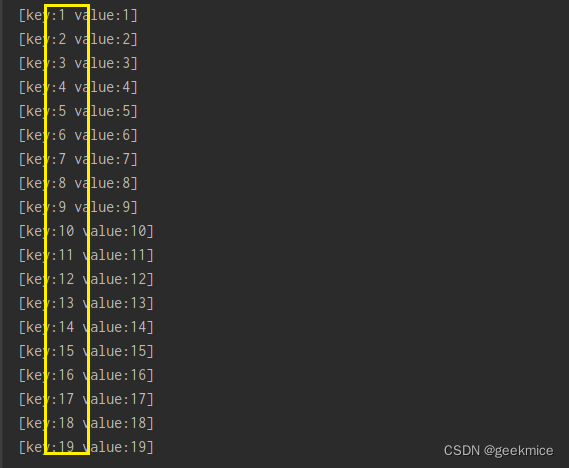
for (Map.Entry item : map.entrySet()) {
System.out.println("[key:" + item.getKey() + " value:" + item.getValue() + "]");
}
}
String类型键结果展示
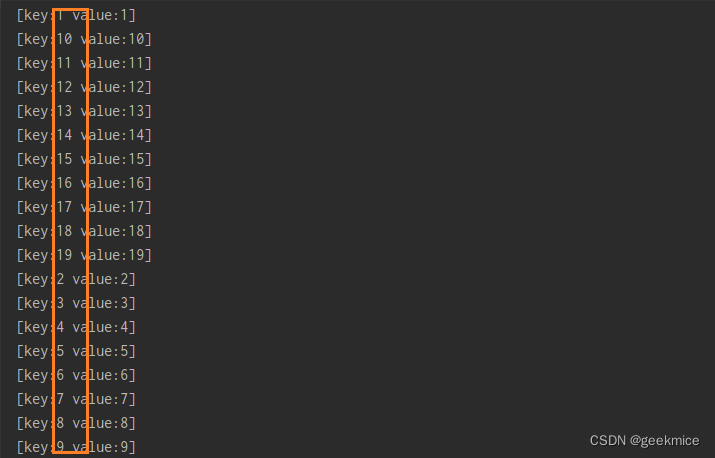
Bigdecimal类型键结果展示
TreeMap<String, Object> tree = new TreeMap<String, Object>() {{
// 1、数字类型字符串 直接按照大小排序1
// put("1", new StudentMapT("张胜男", 18, LocalDate.now()));
// put("2", new StudentMapT("张胜男", 18, LocalDate.now()));
// put("3", new StudentMapT("张胜男", 18, LocalDate.now()));
// put("-1", new StudentMapT("张胜男", 18, LocalDate.now()));
// 2、两个字符串 s1, s2 如果s1和s2是父子串关系,则 子串 < 父串
// 如果非为父子串关系, 则从第一个非相同字符来比较。
// 字符间的比较,是按照字符的字节码(ascii)来比较
put("1", new StudentMapT("张胜男", 18, LocalDate.now()));
put("2", new StudentMapT("张胜男", 18, LocalDate.now()));
put("3", new StudentMapT("张胜男", 18, LocalDate.now()));
put("-1", new StudentMapT("张胜男", 18, LocalDate.now()));
}};
for (Map.Entry item : tree.entrySet()) {
System.out.println("[key:" + item.getKey() + " value:" + item.getValue() + "]");
}
LinkedHashMap内部维护了一个单链表,有头尾节点,同时LinkedHashMap节点Entry内部除了继承HashMap的Node属性,还有before 和 after用于标识前置节点和后置节点。可以实现按插入的顺序或访问顺序排序。
@Test
public void t5() {
LinkedHashMap<String, Object> stringObjectLinkedHashMap = new LinkedHashMap<String, Object>() {{
put("1", 1);
put("5", 1);
put("3", 1);
}};
for (Map.Entry item : stringObjectLinkedHashMap.entrySet()) {
System.out.println("[key:" + item.getKey() + " value:" + item.getValue() + "]");
}
}
[key:1 value:1]
[key:5 value:1]
[key:3 value:1]
14、hashmap为什么是线程不安全?
HashMap在put的时候,插入的元素超过了容量(由负载因子决定)的范围就会触发扩容操作,就是rehash,这个会重新将原数组的内容重新hash到新的扩容数组中,在多线程的环境下,存在同时其他的元素也在进行put操作,如果hash值相同,可能出现同时在同一数组下用链表表示,造成闭环,导致在get时会出现死循环,所以HashMap是线程不安全的。
15、为什么初始化容量为16
HashMap作为一种数据结构,元素在put的过程中需要进行hash运算,目的是计算出该元素存放在hashMap中的具体位置。hash运算的过程其实就是对目标元素的Key进行hashcode,再对Map的容量进行取模,而JDK 的工程师为了提升取模的效率,使用位运算代替了取模运算,这就要求Map的容量一定得是2的幂。而作为默认容量,太大和太小都不合适,所以16就作为一个比较合适的经验值被采用了。为了保证任何情况下Map的容量都是2的幂,HashMap在两个地方都做了限制。首先是,如果用户制定了初始容量,那么HashMap会计算出比该数大的第一个2的幂作为初始容量。另外,在扩容的时候,也是进行成倍的扩容,即4变成8,8变成16
初始长度为16。当长度为2^n时,在计算index时length-1的二进制全是1,既能加快运算的速度,也可以保证均匀分布
16、为什么负载因子是0.75
负载因子是和扩容机制有关的,意思是如果当前容器的容量,达到了我们设定的最大值,就要开始执行扩容操作
比如说当前的容器容量是16,负载因子是0.75,16*0.75=12,也就是说,当容量达到了12的时候就会进行扩容操作
他的作用很简单,相当于是一个扩容机制的阈值。当超过了这个阈值,就会触发扩容机制
负载因子的作用肯定也是节省时间和空间。
当负载因子是1.0的时候,也就意味着,只有当数组的8个值(这个图表示了8个)全部填充了,才会发生扩容。这就带来了很大的问题,因为Hash冲突时避免不了的。当负载因子是1.0的时候,意味着会出现大量的Hash的冲突,底层的红黑树变得异常复杂。对于查询效率极其不利。这种情况就是牺牲了时间来保证空间的利用率。
因此一句话总结就是负载因子过大,虽然空间利用率上去了,但是时间效率降低了。
负载因子是0.5的时候,这也就意味着,当数组中的元素达到了一半就开始扩容,既然填充的元素少了,Hash冲突也会减少,那么底层的链表长度或者是红黑树的高度就会降低。查询效率就会增加。
但是,兄弟们,这时候空间利用率就会大大的降低,原本存储1M的数据,现在就意味着需要2M的空间。
一句话总结就是负载因子太小,虽然时间效率提升了,但是空间利用率降低了。
大致意思就是说负载因子是0.75的时候,空间利用率比较高,而且避免了相当多的Hash冲突,使得底层的链表或者是红黑树的高
17、HashMap允许空键空值么
HashMap最多只允许一个键为Null(多条会覆盖),但允许多个值为Null
18、影响HashMap性能的重要参数
初始容量:创建哈希表(数组)时桶的数量,默认为 16
负载因子:哈希表在其容量自动增加之前可以达到多满的一种尺度,默认为 0.75
19、HashMap的工作原理
HashMap是基于hashing的原理,我们使用put(key, value)存储对象到HashMap中,使用get(key)从HashMap中获取对象
20、HashMap 的底层数组长度为何总是2的n次方
HashMap根据用户传入的初始化容量,利用无符号右移和按位或运算等方式计算出第一个大于该数的2的幂。使数据分布均匀,减少碰撞;当length为2的n次方时,h&(length - 1) 就相当于对length取模,而且在速度、效率上比直接取模要快得多。
21、为什么1.8改用红黑树
比如某些人通过找到你的hash碰撞值,来让你的HashMap不断地产生碰撞,那么相同key位置的链表就会不断增长,当你需要对这个HashMap的相应位置进行查询的时候,就会去循环遍历这个超级大的链表,性能及其地下。java8使用红黑树来替代超过8个节点数的链表后,查询方式性能得到了很好的提升,从原来的是O(n)到O(logn)。
22、1.8中的扩容为什么逻辑判断更简单
元素在重新计算hash之后,因为n变为2倍,那么n-1的mask范围在高位多1bit(红色),因此新的index就会发生这样的变化:
因此,我们在扩充HashMap的时候,不需要像JDK1.7的实现那样重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”,可以看看下图为16扩充为32的resize示意图
这个设计确实非常的巧妙,既省去了重新计算hash值的时间,而且同时,由于新增的1bit是0还是1可以认为是随机的,因此resize的过程,均匀的把之前的冲突的节点分散到新的bucket了。这一块就是JDK1.8新增的优化点。有一点注意区别,JDK1.7中rehash的时候,旧链表迁移新链表的时候,如果在新表的数组索引位置相同,则链表元素会倒置,但是从上图可以看出,JDK1.8不会倒置。
23、hashmap重复数据校验
class SpringbootMybatisCrudApplicationTests {
@Test
public static void contextLoads() {
Person p1 = new Person("xiaoer", 1);
Person p2 = new Person("san", 4);
Map<Person, String> maps = new HashMap<Person, String>();
maps.put(p1, "1111");
maps.put(p2, "2222");
System.out.println(maps);
maps.put(p2, "333");
System.out.println(maps);
System.out.println(p1.hashCode());
p1.setAge(5);
System.out.println(maps);
maps.put(p1, "1111");
System.out.println(p1.hashCode());
System.out.println(p1.hashCode());
System.out.println(maps);
System.out.println(maps.get(p1));
}
public static void main(String[] args) {
contextLoads();
}
}
在数组中存的是对象的引用,不是对象。
我对上面的程序debug了一遍,发现原来是因为在p1刚放进去的时候是由Person的name和age的hashcolde散列码共同构成的,但是,但是,但是,重要说3遍!由于放进去的只是对象的引用,所以当下面的p1.setAge(5); 时候所以数组中的值发生变化,也说明他本身的hashcode即hash发生变化,但是,但是,但是,重要说3遍!尽管现在他的散列码发生变化,然而他已经在hashmap数组中了,他位置没有发生变化,即意味着他现在变化后的hash的位置空着,所以对hashmap添加的时候就又添加进去,方在现在的位置上.
24、何时链表转换为红黑树
HashMap在jdk1.8之后引入了红黑树的概念,表示若桶中链表元素超过8时,会自动转化成红黑树;若桶中元素小于等于6时,树结构还原成链表形式。
原因:
红黑树的平均查找长度是log(n),长度为8,查找长度为log(8)=3,链表的平均查找长度为n/2,当长度为8时,平均查找长度为8/2=4,这才有转换成树的必要;链表长度如果是小于等于6,6/2=3,虽然速度也很快的,但是转化为树结构和生成树的时间并不会太短。
还有选择6和8的原因是:
中间有个差值7可以防止链表和树之间频繁的转换。假设一下,如果设计成链表个数超过8则链表转换成树结构,链表个数小于8则树结构转换成链表,如果一个HashMap不停的插入、删除元素,链表个数在8左右徘徊,就会频繁的发生树转链表、链表转树,效率会很低
25、HashMap 和 ConcurrentHashMap 的区别
ConcurrentHashMap对整个桶数组进行了分割分段(Segment),然后在每一个分段上都用lock锁进行保护,相对于HashTable的synchronized锁的粒度更精细了一些,并发性能更好,而HashMap没有锁机制,不是线程安全的。(JDK1.8之后ConcurrentHashMap启用了一种全新的方式实现,利用CAS算法。)
HashMap的键值对允许有null,但是ConCurrentHashMap都不允许
26、平时开发中遍历HashMap方案有哪些
1、通过Map.Entry 遍历map
@Test
public void traverseByEntry() {
Map<String, Object> map = new HashMap<String, Object>() {{
put("name", "豹子头");
put("age", "98");
put("professor", "八十万禁军教头");
}};
for (Map.Entry item : map.entrySet()) {
System.out.println(item);
}
}
professor=八十万禁军教头
name=豹子头
age=98
2、获取对应keyset,values遍历key或者value
@Test
public void traverseByKeySetOrValues() {
Map<String, Object> map = new HashMap<String, Object>() {{
put("name", "豹子头");
put("age", "98");
put("professor", "八十万禁军教头");
}};
for (String str : map.keySet()) {
System.out.println("key:" + str + ",value:" + map.get(str));
}
}
key:professor,value:八十万禁军教头
key:name,value:豹子头
key:age,value:98
3、通过lambda遍历map
@Test
public void traverseByLambda() {
Map<String, Object> map = new HashMap<String, Object>() {{
put("name", "豹子头");
put("age", "98");
put("professor", "八十万禁军教头");
}};
map.forEach((key, value) -> {
System.out.println("[key:" + key + ",value:" + value + "]");
});
}
[key:professor,value:八十万禁军教头]
[key:name,value:豹子头]
[key:age,value:98]
4、通过stream流遍历map
@Test
public void traverseByStream() {
Map<String, Object> map = new HashMap<String, Object>() {{
put("name", "豹子头");
put("age", "98");
put("professor", "八十万禁军教头");
}};
map.entrySet().stream().forEach((Map.Entry entry) -> {
System.out.println(entry);
});
}
professor=八十万禁军教头
name=豹子头
age=98
27、hashmap遍历修改数据
1、如果在遍历的过程中,对数据进行删除操作,就一定要使用Iterator,否则会抛出java.util.ConcurrentModificationException 异常。因为在遍历HashMap的元素过程中删除了当前所在元素,下一个待访问的元素的指针也由此丢失了。
2、遍历过程修改,没有效果
// for (Map.Entry item : map.entrySet()) {
// if ("age".equals(item.getKey())) {
// map.remove(item);
// }
// }
// System.out.println(map);
// {professor=八十万禁军教头, name=豹子头, age=98}
@Test
public void traverseByEntryContinueDel() {
Map<String, Object> map = new HashMap<String, Object>() {{
put("name", "豹子头");
put("age", "98");
put("professor", "八十万禁军教头");
}};
// for (Map.Entry item : map.entrySet()) {
// if ("age".equals(item.getKey())) {
// map.remove(item);
// }
// }
// System.out.println(map);
// {professor=八十万禁军教头, name=豹子头, age=98}
System.out.println("正确解法");
Set<Map.Entry<String, Object>> entrySet = map.entrySet();
Iterator<Map.Entry<String, Object>> entryIterator = entrySet.iterator();
while (entryIterator.hasNext()) {
Map.Entry<String, Object> en = entryIterator.next();
String key = en.getKey();
Object value = en.getValue();
System.out.println("key:" + key + ",value:" + value);
if ("age".equals(key)) {
//
// System.out.println("删除key:" + key + ",删除value:" + value);
// 删除操作
entryIterator.remove();
// 修改操作
map.put("age","8");
map.put("age1","8");
}
}
System.out.println("删除之后map:" + map);
}
28、谈一下hashmap扩容机制
扩容时机
- 如果数组为空,则进行首次扩容。
- 添加后,如果数组中元素超过阈值,即比例超出限制(默认为0.75),则扩容。
数据迁移
每次扩容时都是将容量翻倍,即创建一个2倍大的新数组,然后再将旧数组中的数组迁移到新数组里。由于HashMap中数组的容量为2^N,所以可以用位移运算计算新容量,效率很高。
在数据迁移时,为了兼顾性能,不会重新计算一遍每个key的哈希值,而是根据位移运算后(左移翻倍)多出来的最高位来决定,如果高位为0则元素位置不变,如果高位为1则元素的位置是在原位置基础上加上旧的容量。
hashmap如何解决hash冲突
Hash 表又叫做“散列表”,它是通过 key 直接访问在内存存储位置的数据结构,
在具体实现上,我们通过 hash 函数把 key 映射到表中的某个位置,来获取这个
位置的数据,从而加快查找速度
所谓 hash 冲突,是由于哈希算法被计算的数据是无限的,而计算后的结果范围有限,所以总会存在不同的数据经过计算后得到的值相同,这就是哈希冲突。
通常解决 hash 冲突的方法有 4 种
开放定址法
也称为线性探测法,就是从发生冲突的那个位置开始,按照一定的次序从 hash 表中找到一个空闲的位置,然后把发生冲突的元素存入到这个空闲位置中。ThreadLocal 就用到了线性探测法来解决 hash 冲突的
场景分析
比如这样一种情况,在 hash 表索引 1 的位置存了一个 key=name,当再次添加key=hobby 时,hash 计算得到的索引也是 1,这个就是 hash 冲突。而开放定址法,就是按顺序向前找到一个空闲的位置来存储冲突的 key。
链式寻址法
这是一种非常常见的方法,简单理解就是把存在 hash 冲突的 key,以单向链表的方式来存储,比如 HashMap 就是采用链式寻址法来实现的。
再hash法
就是当通过某个 hash 函数计算的 key 存在冲突时,再用另外一个hash 函数对这个 key 做 hash,一直运算直到不再产生冲突。这种方式会增加计算时间,性能影响较大。
建立公共溢出区
就是把 hash 表分为基本表和溢出表两个部分,凡事存在冲突的元素,一律放入到溢出表中
总结
HashMap 在JDK1.8版本中,通过链式寻址法+红黑树的方式来解决 hash 冲突问题,其中红黑树是为了优化 Hash 表链表过长导致时间复杂度增加的问题。当链表长度大于 8 并且 hash 表的容量大于 64 的时候,再向链表中添加元素就会触发转化。
ArrayList
29、ArrayList理解,谈谈你的理解(重点)
ArrayList是基于数组实现的,是一个动态数组,get和set效率高;其容量能自动增长,内存连续。
30、说说ArrayList为什么增删慢
ArrayList本质是数组的操作
增删慢:
1.每当插入或删除操作时 对应的需要向前或向后的移动元素
2.当插入元素时 需要判定是否需要扩容操作
扩容操作:创建一个新数组 增加length 再将元素放入进去
较为繁琐
查询快:
数组的访问 实际上是对地址的访问 效率是挺高的
列如 new int arr[5];
arr数组的地址假设为0x1000
arr[0] ~ arr[5] 地址可看作为 0x1000 + i * 4
首地址 + 下标 * 引用数据类型的字节大小
添加元素
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return <tt>true</tt> (as specified by {@link Collection#add})
*/
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!! 是否扩容
elementData[size++] = e; // 最后一个位置添加元素,数组长度+1
return true;
}
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
1 直接添加元素,先判断添加元素之后容量是否够用,再遍历list数组,到最后一个位置,元素添加进去,长度+1
2 指定位置添加元素,先判断指定位置是否超过数组范围,在判断添加元素之后容量是否够用,最后
在指定位置添加元素,原来在这个位置的元素后移 数组长度-索引位置
删除元素
// 指定位置删除
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
// 指定元素删除
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
/*
* Private remove method that skips bounds checking and does not
* return the value removed.
*/
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
}
分析:如果查看这个元素是否存在list数组,遍历存在的话进行删除操作,指定元素前移
如果不存在,遍历数组,存在为空的元素位置,将其删除,数组长度减一
根据指定位置元素,首先检查索引位置是否正确,其次删除指定位置元素,元素前移,数组长度减一
最后一个位置置为null
31、ArrayList的底层实现是数组,但是数组的⼤⼩是定⻓的,如果我们不断的往⾥⾯添加数据的话,不会有问题吗?
通过⽆参构造⽅法的⽅式ArrayList()初始化,则赋值底层数Object[] elementData为⼀个默认空数组 Object[]DEFAULTCAPACITY_EMPTY_ELEMENTDATA ={}所以数组容量为0,只有真正对数据进⾏添加add时,才分配默认DEFAULT_CAPACITY = 10的初始容量。 private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
32、ArrayList常用方法
1、add(Object element): 向列表的尾部添加指定的元素。
2、size(): 返回列表中的元素个数。
3、get(int index): 返回列表中指定位置的元素,index从0开始。
4、add(int index, Object element): 在列表的指定位置插入指定元素。
5、set(int i, Object element): 将索引i位置元素替换为元素element并返回被替换的元素。
6、clear(): 从列表中移除所有元素。
7、isEmpty(): 判断列表是否包含元素,不包含元素则返回 true,否则返回false。
8、contains(Object o): 如果列表包含指定的元素,则返回 true。
9、remove(int index): 移除列表中指定位置的元素,并返回被删元素。
10、remove(Object o): 移除集合中第一次出现的指定元素,移除成功返回true,否则返回false。
11、iterator(): 返回按适当顺序在列表的元素上进行迭代的迭代器。
33、ArrayList⽤来做队列合适么
队列一般是FIFO的,如果用ArrayList做队列,就需要在数组尾部追加数据,数组头部删除数组,反过来也可以。但是无论如何总会有一个操作会涉及到数组的数据搬迁,这个是比较耗费性能的。
这个回答是错误的!
ArrayList固然不适合做队列,但是数组是非常合适的。比如ArrayBlockingQueue内部实现就是一个环形队列,它是一个定长队列,内部是用一个定长数组来实现的。另外著名的Disruptor开源Library也是用环形数组来实现的超高性能队列,具体原理不做解释,比较复杂。简单点说就是使用两个偏移量来标记数组的读位置和写位置,如果超过长度就折回到数组开头,前提是它们是定长数组。
34、可以手写一个ArrayList的简单实现
确定数据结构
我们知道,ArrayList中无论什么数据都能放,是不是意味着它是一个Object类型,既然是数组,那么是不是Object[]数组类型的?所以我们定义的数据结构如下:
private Object[] elementData;
private int size;
12
设置自定义的MyArrayList的长度为10
public MyArrayList(){
this(10);
}
public MyArrayList(int initialCapacity){
if(initialCapacity<0){
try {
throw new Exception();
} catch (Exception e) {
e.printStackTrace();
}
}
elementData = new Object[initialCapacity];
}
1234567891011121314
有了存放数据的位置,接下来,我们想想如何将数据放入数组?
添加数据
public void add(Object obj){
elementData[size++]=obj;
}
123
每添加一个元素,size就会自增1,我们定义的数组长度为10,当我们添加到11个元素的时候,显然没有地方存放新添加的数据,这个时候我们需要对数组进行扩容处理
对上面代码做如下修改:
public void add(Object obj){
if(size==elementData.length){
//创建一个新的数组,并且这个数组的长度是原数组长度的2倍
Object[] newArray = new Object[size*2];
//使用底层拷贝,将原数组的内容拷贝到新数组
System.arraycopy(elementData, 0, newArray, 0, elementData.length);
//并将新数组赋值给原数组的引用
elementData = newArray;
}
//新来的元素,直接赋值
elementData[size++]=obj;
}
123456789101112
查询数据
接着我们看一下删除的操作。ArrayList支持两种删除方式:
- 按照下标删除
- 按照元素删除,这会删除ArrayList中与指定要删除的元素匹配的第一个元素
对于ArrayList来说,这两种删除的方法差不多,都是调用的下面一段代码:
public void remove(int index){
//删除指定位置的对象
//a b d e
int numMoved = size - index - 1;
if (numMoved > 0){
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
}
elementData[--size] = null; // Let gc do its work
}
12345678910
其实做的事情就是两件:
- 把指定元素后面位置的所有元素,利用System.arraycopy方法整体向前移动一个位置
- 最后一个位置的元素指定为null,这样让gc可以去回收它
指定位置添加数据
把从指定位置开始的所有元素利用System,arraycopy方法做一个整体的复制,向后移动一个位置(当然先要用ensureCapacity方法进行判断,加了一个元素之后数组会不会不够大),然后指定位置的元素设置为需要插入的元素,完成了一次插入的操作。
public void add(int index,Object obj){
ensureCapacity(); //数组扩容
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = obj;
size++;
}
1234567
总结一下
从上面的几个过程总结一下ArrayList的特点:
- ArrayList底层以数组实现,是一种随机访问模式,通过下标索引定位数据,所以查找非常快
- ArrayList在顺序添加一个元素的时候非常方便,只是往数组里面添加了一个元素而已(这里指的末尾添加数据)
- 当删除元素的时候,涉及到一次元素复制移位,如果要复制的元素很多,那么就会比较耗费性能
- 当插入元素的时候,涉及到一次元素复制移位,如果要复制的元素很多,那么就会比较耗费性能
因此,ArrayList比较适合顺序添加、随机访问的场景。
35、你什么时候要选择 ArrayList,什么时候选择 LinkedList
1、如果应用程序对数据有较多的随机访问,ArrayList对象要优于LinkedList对象;
2、如果应用程序有更多的插入或者删除操作,较少的随机访问,LinkedList对象要优于ArrayList对象;
3、不过ArrayList的插入,删除操作也不一定比LinkedList慢,如果在List靠近末尾的地方插入,那么ArrayList只需要移动较少的数据,而LinkedList则需要一直查找到列表尾部,反而耗费较多时间,这时ArrayList就比LinkedList要快。
36、ArrayList中elementData为什么被transient修饰
ArrayList在序列化的时候会调用writeObject,直接将size和element写入ObjectOutputStream;反序列化时调用readObject,从ObjectInputStream获取size和element,再恢复到elementData。
为什么不直接用elementData来序列化,而采用上诉的方式来实现序列化呢?原因在于elementData是一个缓存数组,它通常会预留一些容量,等容量不足时再扩充容量,那么有些空间可能就没有实际存储元素,采用上诉的方式来实现序列化时,就可以保证只序列化实际存储的那些元素,而不是整个数组,从而节省空间和时间。
37、ArrayList添加第一个元素过程
1、当通过 ArrayList() 构造一个空集合,初始长度是为0的,第 1 次添加元素,会创建一个长度为10的数组,并将该元素赋值到数组的第一个位置。
2、第 2 次添加元素,集合不为空,而且由于集合的长度size+1是小于数组的长度10,所以直接添加元素到数组的第二个位置,不用扩容。
3、第 11 次添加元素,此时 size+1 = 11,而数组长度是10,这时候创建一个长度为10+10*0.5 = 15 的数组(扩容1.5倍),然后将原数组元素引用拷贝到新数组。并将第 11 次添加的元素赋值到新数组下标为10的位置。
4、第 Integer.MAX_VALUE - 8 = 2147483639,然后 2147483639%1.5=1431655759(这个数是要进行扩容) 次添加元素,为了防止溢出,此时会直接创建一个 1431655759+1 大小的数组,这样一直,每次添加一个元素,都只扩大一个范围。
5、第 Integer.MAX_VALUE - 7 次添加元素时,创建一个大小为 Integer.MAX_VALUE 的数组,在进行元素添加。
6、第 Integer.MAX_VALUE + 1 次添加元素时,抛出 OutOfMemoryError 异常
38、ArrayList扩容机制说一下
new一个ArrayList进行初始化list,底层给该list赋值空数组,当我们添加第一个元素,才会给初始容量10,后面添加元素知道第11个元素开进行扩容,调用grow方法,通过Arrays.copy方法返回新数组,新数组容量是原数组的1.5倍,通过原数组容量+原数组向右移位1位;
扩容代价是很高得,因此再实际使用时,我们因该避免数组容量得扩张。尽可能避免数据容量得扩张。尽可能,就至指定容量,避免数组扩容的发生
39、ArrayList 底层实现就是数组,访问速度本身就很快,为何还要实现 RandomAccess
RandomAccess是一个空的接口, 空接口一般只是作为一个标识, 如Serializable接口. JDK文档说明RandomAccess是一个标记接口(Marker interface), 被用于List接口的实现类, 表明这个实现类支持快速随机访问功能(如ArrayList). 当程序在遍历这中List的实现类时, 可以根据这个标识来选择更高效的遍历方式
40、ArrayList 中的 elementData 为什么是 Object 而不是泛型 E
Java 中泛型运用的目的就是实现对象的重用,泛型T和Object类其实在编写时没有太大区别,只是JVM中没有T这个概念,T只是存在于编写时,进入虚拟机运行时,虚拟机会对泛型标志进行擦除,也就是替换T会限定类型替换(根据运行时类型),如果没有限定就会用Object替换。同时Object可以new Object(),就是说可以实例化,而T则不能实例化。在反射方面来说,从运行时,返回一个T的实例时,不需要经过强制转换,然后Object则需要经过转换才能得到。
41、ArrayList 的插入删除一定慢么?
首部插入元素
如果可以确定在首部增加,删除,获取元素,可以使用LinkedList,这个集合里面很对效率高的方法,addFirst,addLast,getFirst,getLast,removeFirst,removeLast,这些方法的时间复杂度都是O(1)常量级别;而ArrayList需要数据迁移,时间复杂度比较高,耗时
尾部插入
若添加元素数量很少时,则两种List的效率都很高,从使用方面来说,其效率差距一般可以忽略不计;
若添加元素数量达到一定规模时,则LinkedList的效率要高于ArrayList,因为ArrayList会频繁触发扩容复制,扩容耗费了很多时间,拉低了效率;
如果添加元素数量非常大时,则ArrayList的效率要高于LinkedList。因为随着ArrayList长度的增大,其扩容的次数会大大降低。对于单个元素,ArrayList只需要一个简单赋值操作,而LinkedList需要不断分配新的内存空间再进行赋值,本身在效率上是低于ArrayList的,巨大的数量积累将这个差距放大了很多;
中间插入
当向List添加元素的位置比较靠近中间位置时,LinkedList的效率要低于ArrayList,因为LinkedList添加元素时需要通过从首尾向中间遍历来寻找节点,遍历耗时比较长,而ArrayList迁移的元素则相对少了。
42、ArrayList默认容量
ArrayList默认构造的容量为10,没错。ArrayList的底层是由一个Object[]数组构成的,而这个Object[]数组,默认的长度是10,所以有的文章会说ArrayList长度容量为10。然而你所指的size()方法,只的是“逻辑”长度。所谓“逻辑”长度,是指内存已存在的“实际元素的长度”,而“空元素不被计算”,即:当你利用add()方法,向ArrayList内添加一个“元素”时,逻辑长度就增加1位。 而剩下的9个空元素不被计算。
ArrayList相当于在没指定initialCapacity时就是会使用延迟分配对象数组空间,当第一次插入元素时才分配10(默认)个对象空间。假如有20个数据需要添加,那么会分别在第一次的时候,将ArrayList的容量变为10 ,之后扩容会按照1.5倍增长。也就是当添加第11个数据的时候,Arraylist继续扩容变为10*1.5=15
1、ArrayList构造函数
/**
* E : Default initial capacity.
* C : 默认初始容量大小
*/
private static final int DEFAULT_CAPACITY = 10;
/**
* The size of the ArrayList (the number of elements it contains).
* 数组元素个数
*/
private int size;
/**
* E : Shared empty array instance used for empty instances.
* C : 用于存放空数据的空数组
*/
private static final Object[] EMPTY_ELEMENTDATA = {};
/**inflte : 膨胀,充气
* Shared empty array instance used for default sized empty instances.
* 默认用来存放空数据的空数组
* We distinguish this from EMPTY_ELEMENTDATA to know how much to inflate
* 用来区分用于存放空数据的空数组
* when first element is added .
* 当第一次添加数据的时候
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
* The array buffer into which the elements of the ArrayList are stored.
* arraylist中数据存储在array缓存中
* The capacity of the ArrayList is the length of this array buffer.
* arraylist容量就是数组内存的长度
* Any empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
* will be expanded to DEFAULT_CAPACITY when the first element is added.
* 任何一个空的arraylist都是用 elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
* 第一次添加数据时进行扩容
*/
transient Object[] elementData; // non-private to simplify nested class access
/**
* 默认构造函数,使用初始容量10构造一个空列表(无参数构造)
**/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
/**
* 带初始容量参数的构造函数。(用户自己指定容量)
*/
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {//初始容量大于0
//创建initialCapacity大小的数组
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {//初始容量等于0
//创建空数组
this.elementData = EMPTY_ELEMENTDATA;
} else {//初始容量小于0,抛出异常
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
/**
* 构造包含指定collection元素的列表,这些元素利用该集合的迭代器按顺序返回
* 如果指定的集合为null,throws NullPointerException。
*/
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}
以无参数构造方法创建 ArrayList 时,实际上初始化赋值的是一个空数组。当真正对数组进行添加元素操作时,才真正分配容量。即向数组中添加第一个元素时,数组容量扩为10
2、分析 ArrayList 扩容机制
无参构造函数创建的 ArrayList 为例分析
add方法
/**
* 将指定的元素追加到此列表的末尾。
*/
public boolean add(E e) {
// 添加元素之前,先调用ensureCapacityInternal方法
ensureCapacityInternal(size + 1) ; // Increments modCount!!
// 这里看到ArrayList添加元素的实质就相当于为数组赋值
elementData[size++] = e ;
return true ;
}
ensureCapacityInternal()方法
//得到最小扩容量
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
// 获取默认的容量和传入参数的较大值
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
当要add 进第1个元素时,minCapacity为1,在Math.max()方法比较后,minCapacity 为10。
ensureExplicitCapacity()方法
//判断是否需要扩容
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
//调用grow方法进行扩容,调用此方法代表已经开始扩容了
grow(minCapacity);
}
当我们要 add 进第1个元素到 ArrayList 时,elementData.length 为0 (因为还是一个空的 list),因为执行了 ensureCapacityInternal() 方法 ,所以 minCapacity 此时为10。此时,minCapacity - elementData.length > 0 成立,所以会进入 grow(minCapacity) 方法。
当add第2个元素时,minCapacity 为2,此时e lementData.length(容量)在添加第一个元素后扩容成 10 了。此时,minCapacity - elementData.length > 0 不成立,所以不会进入 (执行)grow(minCapacity) 方法。
添加第3、4···到第10个元素时,依然不会执行grow方法,数组容量都为10;直到添加第11个元素,minCapacity(为11)比elementData.length(为10)要大。进入grow方法进行扩容。
4、grow方法
/**
* 要分配的最大数组大小
*/
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
/**
* ArrayList扩容的核心方法。
*/
private void grow(int minCapacity) {
// oldCapacity为旧容量,newCapacity为新容量
int oldCapacity = elementData.length;
//将oldCapacity 右移一位,其效果相当于oldCapacity /2,
//我们知道位运算的速度远远快于整除运算,整句运算式的结果就是将新容量更新为旧容量的1.5倍,
int newCapacity = oldCapacity + (oldCapacity >> 1);
//然后检查新容量是否大于最小需要容量,若还是小于最小需要容量,那么就把最小需要容量当作数组的新容量,
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
// 如果新容量大于 MAX_ARRAY_SIZE,进入(执行) `hugeCapacity()` 方法来比较 minCapacity 和 MAX_ARRAY_SIZE,
//如果minCapacity大于最大容量,则新容量则为`Integer.MAX_VALUE`,否则,新容量大小则为 MAX_ARRAY_SIZE 即为 `Integer.MAX_VALUE - 8`。
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
int newCapacity = oldCapacity + (oldCapacity >> 1),所以 ArrayList 每次扩容之后容量都会变为原来的 1.5 倍左右(oldCapacity为偶数就是1.5倍,否则是1.5倍左右)! 奇偶不同,比如 :10+10/2 = 15, 33+33/2=49。如果是奇数的话会丢掉小数.
①java 中的 length 属性是针对数组说的,比如说你声明了一个数组,想知道这个数组的长度则用到了 length 这个属性.
②java 中的 length() 方法是针对字符串说的,如果想看这个字符串的长度则用到 length() 这个方法.
③java 中的 size() 方法是针对泛型集合说的,如果想看这个泛型有多少个元素,就调用此方法来查看!
5、hugeCapacity()方法
从上面 grow() 方法源码我们知道: 如果新容量大于 MAX_ARRAY_SIZE,进入(执行) hugeCapacity() 方法来比较 minCapacity 和 MAX_ARRAY_SIZE,如果minCapacity大于最大容量,则新容量则为Integer.MAX_VALUE,否则,新容量大小则为 MAX_ARRAY_SIZE 即为 Integer.MAX_VALUE - 8。
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
//对minCapacity和MAX_ARRAY_SIZE进行比较
//若minCapacity大,将Integer.MAX_VALUE作为新数组的大小
//若MAX_ARRAY_SIZE大,将MAX_ARRAY_SIZE作为新数组的大小
//MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
43、遍历一个 List 有哪些不同的方式 每种方法的实现原理是什么 Java 中 List 遍历的最佳实践是什么
for 循环遍历,基于计数器。在集合外部维护一个计数器,然后依次读取每一个位置的元素,当读取到最后一个元素后停止。
迭代器遍历,Iterator。Iterator 是面向对象的一个设计模式,目的是屏蔽不同数据集合的特点,统一遍历集合的接口。Java 在 Collections 中支持了 Iterator 模式。
foreach 循环遍历。foreach 内部也是采用了 Iterator 的方式实现,使用时不需要显式声明 Iterator 或计数器。优点是代码简洁,不易出错;缺点是只能做简单的遍历,不能在遍历过程中操作数据集合,例如删除、替换。
44、说一下 ArrayList 的优缺点
ArrayList的优点如下:
ArrayList 底层以数组实现,是一种随机访问模式。ArrayList 实现了 RandomAccess 接口,因此查找的时候非常快。
ArrayList 在顺序添加一个元素的时候非常方便。
ArrayList 的缺点如下:
删除元素的时候,需要做一次元素复制操作。如果要复制的元素很多,那么就会比较耗费性能。
插入元素的时候,也需要做一次元素复制操作,缺点同上。
ArrayList 比较适合顺序添加、随机访问的场景。
45、如何实现数组和 List 之间的转换
数组转 List:使用 Arrays. asList(array) 进行转换。
List 转数组:使用 List 自带的 toArray() 方法。
代码示例:
// list convertTo array
List<String> list = new ArrayList<String>();
list.add("123");
list.add("456");
String[] str = list.toArray(new String[0]);
for (String item : str) {
System.out.println(item);
}
// 123,456
// array convertTo list
String[] array = new String[]{"123", "456"};
List<String> newList = Arrays.asList(array);
newList.forEach(i -> System.out.println(i));
// 123,456
说明:使用 toArray 带参方法,数组空间大小的 length:
1) 等于 0,动态创建与 size 相同的数组,性能最好。
2) 大于 0 但小于 size,重新创建大小等于 size 的数组,增加 GC 负担。
3) 等于 size,在高并发情况下,数组创建完成之后,size 正在变大的情况下,负面影响与 2 相同。
4) 大于 size,空间浪费,且在 size 处插入 null 值,存在 NPE 隐患。
46、ArrayList与LinkedList区别
底层实现
ArrayList底层通过动态数组实现,实现RandomAccess接口,故而get,set操作效率高
LinkedList底层通过双向链表,里面包含两个node类型节点,首节点,尾结点;每个节点通过引用记住上一个节点和下一个节点的地址,从而使得所有元素彼此连接起来,当添加,删除元素时候,修改彼此的引用即可。
读写操作
对于插入操作而言
头插法
LinkedList快一些,ArrayList需要大量的位移和复制操作,另外容量不够时候需要扩容;LinkedList直接定位元素在首位,修改引用即可插入
尾插法
ArrayList快一些,ArrayList不需要大量位移和复制操作,LinkedList需要大量创建对象
中间插入
ArrayList定位时间很快,常量级别的时间复杂度,比较耗时就是数据迁移和容量不足时候扩容;
LinkedList插入元素不怎么耗时,主要是定位元素需要耗费O(n),以及元素实例化操作
获取元素
ArrayList获取元素,常量级别复杂度,O(1),底层是通过数组实现,获取元素很快
LinkedList获取元素,需要根据指定位置获取对应node节点,获取对应节点过程,这个过程需要遍历链表一半元素,这个遍历过程有点特殊,获取指定索引位置大于链表元素一般,从最后一个节点往前遍历;如果索引位置小于链表一半元素,从头遍历到后面
应用场景
1、两者均有自己的应用场景,如果不确定使用哪种集合,使用ArrayList;
2、如果可以确定在首部增加,删除,获取元素,可以使用LinkedList,这个集合里面很对效率高的方法,addFirst,addLast,getFirst,getLast,removeFirst,removeLast,这些方法的时间复杂度都是O(1)常量级别
3、添加元素在尾部这种情况,ArrayList效率高一些,ArrayList不需要数据拷贝,而LinkedList需要创建大量node对象
4、对于这两种结构的集合,并不是说添加删除元素LinkedList就是很快,获取元素ArrayList效率高;需要具体问题具体分析
47、多线程场景下如何使用 ArrayList
ArrayList 不是线程安全的,如果遇到多线程场景,可以通过 Collections 的 synchronizedList 方法将其转换成线程安全的容器后再使用。例如像下面这样:
List<String> synchronizedList = Collections.synchronizedList(list);
synchronizedList.add("aaa");
synchronizedList.add("bbb");
for (int i = 0; i < synchronizedList.size(); i++) {
System.out.println(synchronizedList.get(i));
}
48、为什么 ArrayList 的 elementData 加上 transient 修饰?
transient 的作用是说不希望 elementData 数组被序列化,重写了 writeObject 实现
private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException{
*// Write out element count, and any hidden stuff*
int expectedModCount = modCount;
s.defaultWriteObject();
*// Write out array length*
s.writeInt(elementData.length);
*// Write out all elements in the proper order.*
for (int i=0; i<size; i++)
s.writeObject(elementData[i]);
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
每次序列化时,先调用 defaultWriteObject() 方法序列化 ArrayList 中的非 transient 元素,然后遍历 elementData,只序列化已存入的元素,这样既加快了序列化的速度,又减小了序列化之后的文件大小
49、ArrayList是线程安全的么?
不是,可以用Vector,Collections.synchronizedList(),原理都是給方法套个synchronized,CopyOnWriteArrayList
50、初始化ArrayList几种方案
add添加元素
@Test
public void initList(){
List<String> list = new ArrayList<>();
list.add("南兰");
list.add("南兰");
list.add("南兰");
list.add("南兰");
list.add("程灵素");
list.add("袁紫衣");
list.add("袁紫衣");
list.add("袁紫衣");
System.out.println(list);
}
[南兰, 南兰, 南兰, 南兰, 程灵素, 袁紫衣, 袁紫衣, 袁紫衣]
匿名内部类,双括号语法
@Test
public void initList() {
List<String> list = new ArrayList<String>() {{
add("南兰");
add("南兰");
add("田归宗");
add("袁紫衣");
add("南兰");
}};
System.out.println(list);
}
[南兰, 南兰, 田归宗, 袁紫衣, 南兰]
stream流处理
@Test
public void initList() {
List<String> list = Stream.of("南兰", "田归农", "苗人凤", "胡斐").collect(Collectors.toList());
System.out.println(list);
}
[南兰, 田归农, 苗人凤, 胡斐]
51、list遍历几种方案
@Test
public void traverseList() {
List<String> list = Stream.of("南兰", "苗人凤", "田归农", "胡一刀").collect(Collectors.toList());
System.out.println("__________________普通for循环__________________");
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
System.out.println("__________________foreach循环遍历__________________");
for (String str : list) {
System.out.println(str);
}
System.out.println("__________________迭代器遍历__________________");
Iterator<String> listIterator = list.iterator();
while (listIterator.hasNext()) {
System.out.println(listIterator.next());
}
System.out.println("__________________stream流遍历__________________");
list.forEach(str -> System.out.println(str));
}
52、ArrayList对于删除元素特殊处理
List<String> list = Stream.of("南兰", "苗人凤", "胡一刀", "胡一刀", "胡一刀", "苗人凤", "苗人凤", "苗人凤", "田归农", "田归农", "田归农", "田归农", "田归农").collect(Collectors.toList());
// 刪除操作
System.out.println("普通for循环删除");
for (int i = 0; i < list.size(); i++) {
if ("苗人凤".equals(list.get(i))) {
list.remove(i);
i--;
}
}
System.out.println("此时list:" + list);
System.out.println("倒序for循环删除元素");
for (int j = list.size() - 1; j >= 0; j--) {
if ("南兰".equals(list.get(j))) {
list.remove(j);
}
}
System.out.println("此时list:" + list);
System.out.println("迭代器删除元素");
Iterator<String> listIterator = list.iterator();
while (listIterator.hasNext()) {
if ("田归农".equals(listIterator.next())) {
listIterator.remove();
}
}
System.out.println("此时list:" + list);
System.out.println("stream流删除元素");
list.removeIf(item -> "胡一刀".equals(item));
System.out.println("此时list:" + list);
普通for循环删除
此时list:[南兰, 胡一刀, 胡一刀, 胡一刀, 田归农, 田归农, 田归农, 田归农, 田归农]
倒序for循环删除元素
此时list:[胡一刀, 胡一刀, 胡一刀, 田归农, 田归农, 田归农, 田归农, 田归农]
迭代器删除元素
此时list:[胡一刀, 胡一刀, 胡一刀]
stream流删除元素
此时list:[]
53、ArrayList对于添加删除元素操作
@Test
public void updateList() {
List<String> list = Stream.of("南兰", "苗人凤", "胡一刀", "胡一刀", "胡一刀", "苗人凤", "苗人凤", "苗人凤", "田归农", "田归农", "田归农", "田归农", "田归农").collect(Collectors.toList());
// 修改操作
// 方法一
for(int i=0;i<list.size();i++){
if("南兰".equals(list.get(i))){
list.set(i,"南蓝");
}
}
System.out.println(list);
// 方法二
Iterator<String> listIterator = list.iterator();
while (listIterator.hasNext()){
Object element = listIterator.next();
if("胡一刀".equals(element)){
int index = list.indexOf(element);
list.set(index,"哈哈哈");
}
}
System.out.println("修改元素之后:"+list);
// 添加元素
// 方法一
ListIterator<String> addListIterator = list.listIterator();
while (addListIterator.hasNext()){
if("胡一刀".equals(addListIterator.next())){
addListIterator.add("条小儿");
}
}
System.out.println("添加元素之后:"+list);
// 方法二
for (int k = 0; k < list.size(); k++) {
if ("苗人凤".equals(list.get(k))) {
list.add( "10");
}
}
System.out.println(list);
}
[南蓝, 苗人凤, 苗人凤, 胡一刀, 胡一刀, 田归农, 田归农]
修改元素之后:[南蓝, 苗人凤, 苗人凤, 哈哈哈, 哈哈哈, 田归农, 田归农]
添加元素之后:[南蓝, 苗人凤, 苗人凤, 哈哈哈, 哈哈哈, 田归农, 田归农]
[南蓝, 苗人凤, 苗人凤, 哈哈哈, 哈哈哈, 田归农, 田归农, 10, 10]
54、ArrayList中modCount的作用
在AbstractList中,有一个全局变量modCount,记录了结构性改变的次数。结构性改变指的是那些修改了列表大小的操作,在迭代过程中可能会造成错误的结果。
modCount交由迭代器(Iterator)和列表迭代器(ListIterator)使用,当进行next()、remove()、previous()、set()、add()等操作时,如果modCount的值意外改变,那么迭代器或者列表迭代器就会抛出ConcurrentModificationException异常。
如果希望提供快速失败(fail-fast)机制,那么其子类就应该在add(int, E)、remove(int)等结构性改变的方法中将modCount变量自增,否则可以忽略该变量。
/**
* The number of times this list has been <i>structurally modified</i>.
* Structural modifications are those that change the size of the
* list, or otherwise perturb it in such a fashion that iterations in
* progress may yield incorrect results.
*
* <p>This field is used by the iterator and list iterator implementation
* returned by the {@code iterator} and {@code listIterator} methods.
* If the value of this field changes unexpectedly, the iterator (or list
* iterator) will throw a {@code ConcurrentModificationException} in
* response to the {@code next}, {@code remove}, {@code previous},
* {@code set} or {@code add} operations. This provides
* <i>fail-fast</i> behavior, rather than non-deterministic behavior in
* the face of concurrent modification during iteration.
*
* <p><b>Use of this field by subclasses is optional.</b> If a subclass
* wishes to provide fail-fast iterators (and list iterators), then it
* merely has to increment this field in its {@code add(int, E)} and
* {@code remove(int)} methods (and any other methods that it overrides
* that result in structural modifications to the list). A single call to
* {@code add(int, E)} or {@code remove(int)} must add no more than
* one to this field, or the iterators (and list iterators) will throw
* bogus {@code ConcurrentModificationExceptions}. If an implementation
* does not wish to provide fail-fast iterators, this field may be
* ignored.
*/
protected transient int modCount = 0;
在开发中可能遇到过这样的代码
List<String> strList = new ArrayList<>();
strList.add("a");
strList.add("b");
strList.add("c");
for (String str : strList) {
if ("b".equals(str)) {
strList.remove(str);
}
}
在执行了remove操作之后就会抛出ConcurrentModificationException,原因是加强for循环利用了迭代器进行遍历,遍历时发生了异常并抛出。
在ArrayList中就继承了AbstractList并在每个结构性改变的方法中让modCount变量自增1,并且实现了自己的迭代器
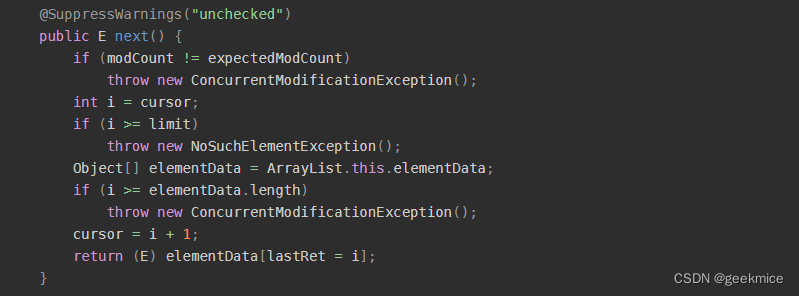
在next()方法中,判断了当前的modCount跟初始化Itr时的expectedModCount是否相同,不同则说明列表数据进行了结构性改变,此时就会抛出ConcurrentModificationException。
因此在遍历中删除元素的正确做法应该是使用Iterator
List<String> strList = new ArrayList<>();
strList.add("a");
strList.add("b");
strList.add("c");
Iterator<String> iterator = strList.iterator();
while (iterator.hasNext()) {
String str = iterator.next();
if ("c".equals(str)) {
iterator.remove();
}
}
55、ArrayList删除重复数据
@Test
public void removeRepeatItem() {
List<String> list = new ArrayList<String>() {{
add("1");
add("2");
add("3");
add("1");
add("1");
}};
System.out.println(list);
// 经过linkedhashset处理
LinkedHashSet<String> stringLinkedHashSet = new LinkedHashSet<>(list);
ArrayList<String> newList = new ArrayList<>(stringLinkedHashSet);
System.out.println(newList);
// jdk1.8stream流处理
List<String> listNonDuplicates = list.stream().distinct().collect(Collectors.toList());
System.out.println(listNonDuplicates);
// hashset处理
HashSet<String> set = new HashSet<>(list.size());
List<String> arrayList = new ArrayList<>(list.size());
for (String str:list){
if(set.add(str)){
arrayList.add(str);
}
}
list.clear();
list.addAll(arrayList);
System.out.println(arrayList);
}
ConcurrentHashmap
56、多线程并发环境下,如果需要一个hash结构,如何实现
我们可以通过ConcurrentHashMap实现这样一个需求
57、chm底层实现原理
concurrenthashmap分为两种情况来介绍,一个是jdk1.7和1.8各自情况不太一样,在jdk1.7它的底层是通过数组+链表实现的,然后使用了一种分段锁来保证线程安全,它是将数组分为16段,也就是说给每个segment配一把锁,然后读取每个segment时候,先获取锁,所以它最多有16个线程并发去操作;到了jdk1.8时候,它跟hashmap一样,引入红黑树这种数据结构,同时在并发处理方面不再使用分段锁而是采用cas+synchronize关键字来实现更为细粒度的锁,相当于是把锁的控制位于hash桶这个级别,然后写入键值对可以锁住hash桶这种链表头结点,这样的话不会影响其他hash桶写入,从而去提高并发处理能力
58、concurrenthashmap可以使用reentrantlock作为锁
理论上是可以的,但是我认为synchronize关键字更合适,因为synchronize在jdk1.6之后进行升级优化,里面引入的偏向锁,轻量级锁,重量级锁,那么这些锁在reentrantlock是没有的,并且随着jdk版本升级,synchronize也在进一步优化,reentrantlock通过java代码实现的,所以在之后很难有特别大的提升空间,所以让我选择的话,我首先考虑synchronize,其次reentrantlock
59、synchronized锁升级的过程
synchronized默认采用的是偏向锁,然后程序运行过程中始终是只有一个线程去获取,这个synchronized的这个锁,那么java对象中记录一个线程id,我们下次再获取这个synchronize的锁时候,只需要比较这个线程id就行了,在运行过程中如果出现第二个线程请求synchronized的锁时候,分两种情况,在没有发生并发竞争锁情况下,这个synchronized就会自动升级为轻量级锁,这个时候,第二个线程就会尝试自旋锁方式获取锁,很快便可以拿到锁,所以第二个线程也不会阻塞,但是如果出现两个线程竞争锁情况,这个synchronize就会升级为重量级锁,这个时候就是只有一个线程获取锁,那么另外一个线程就是阻塞状态,需要等待第一个线程释放锁之后,才能拿到锁。
HashMap 链表和红黑树的转换
ArrayList常见面试题
Arrays.copyOf方法
今天伪装三年经验的开发小白,看看一面都问了哪些问题
linkedlist删除,添加预算















 110
110











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









