







论文题目:Adaptive Quantitative Trading: An Imitative Deep Reinforcement Learning Approach
论文链接:https://ojs.aaai.org/index.php/AAAI/article/view/5587
会议:Proceedings of the AAAI Conference on Artificial Intelligence. 2020, 34(02): 2128-2135. (AAAI’2020)
Abstract
本文提出了一种自适应交易模型,即iRDPG。我们的模型通过深度强化学习和模仿学习 (imitation learning)得到增强。
将量化交易过程看作部分可观察的马尔可夫决策过程(POMDP)。
我们使用真实的金融市场分钟频率的数据进行训练,实验表明,模型具有鲁棒性,能适应不同市场。
Introduction
Related work
总的来说,相关的工作可以分为以下两类:
-
技术分析
技术分析是量化交易中使用最广泛的方法。 技术人员认为,部分市场信息反映在价格和数量数据中,建立技术指标来产生交易信号。
两种主要类型的指标是基于移动均线(moving averages)和振荡器(the oscillators)的指标。
基于移动均线的策略倾向于通过数据平滑识别价格趋势,而基于振荡器的策略(例如,Dual Thrust)用于识别动量。 但是,技术指标不能适应不同的市场。 -
Reinforcement Learning for Quantitative Trading
value based的方法通过state-action的值函数学习最优策略。但value based的方法不擅长大规模的问题。
Problem Definition
Preliminaries 预备知识
价格:
p
=
[
p
1
,
p
2
,
.
.
.
,
p
t
,
.
.
.
]
p=[p_1, p_2, ..., p_t, ...]
p=[p1,p2,...,pt,...]
其中
p
t
=
[
p
t
o
,
p
t
h
,
p
t
l
,
p
t
c
]
p_t=[p_t^o, p_t^h, p_t^l, p_t^c]
pt=[pto,pth,ptl,ptc] (开盘,高,低,收盘)
技术指标:
Q
=
[
q
1
,
.
.
.
,
q
t
.
.
.
]
Q=[q_1,...,q_t...]
Q=[q1,...,qt...]
收益:
R
=
[
r
1
,
.
.
.
,
r
t
,
.
.
.
]
R=[r_1, ..., r_t, ...]
R=[r1,...,rt,...]

Partially Observable MDP
市场是有噪声的,不能直接观察实际的市场状态。我们可以使用的数据是历史价格和交易量,体现了市场状态的一部分。
通常MDP是一个五元组:
[
S
,
A
,
T
,
R
,
γ
]
[S, A, T, R, \gamma]
[S,A,T,R,γ]
T是状态转移函数,由状态间的条件转移概率组成;R(花体)是奖励函数,是连续奖励的集合;R表示某种状态下采取行动的即时奖励;

Observation
我们将观察集分为两部分:账户观察集(累计账户收益)和市场观察集(与价格、技术指标有关)。对大部分强化学习的任务来说,状态会受到动作的影响。与一般的情况不同,个人投资者的交易行为对整个市场的影响不大。换句话说,交易行为与市场观察的转移函数无关。而个人账户的观察集完全依赖于动作。

然而,如果把这两部分加在一起,整个观察集的转移函数可以适用于POMDP的框架:
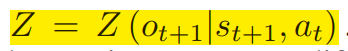
借鉴技术分析,我们从Dual Thrust策略中选择技术指标(BuyLine、SellLine)作为对价格趋势的观察。因此,整个观测集可以表示为:
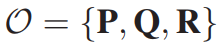
Action
为了比较不同的交易策略,我们规定agent以最低安全金额进行交易。交易行为定义为连续的概率向量:
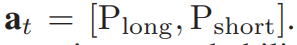
agent执行概率最大的行动。在时刻t,行动可以表示如下,分别对应做多和做空:

这种设置在一定程度上可以减轻仓位的挑战。此外,可以减轻市场容纳能力的影响(可能不会以预期的价格交易)。特别是,考虑到交易动作的连续性,我们将某个策略的动作视为交易信号,这意味着实际执行的动作取决于仓位。
规则如下:
- 如果信号为空(close信号除外),则建立新的仓位(以特定的价格做空或做多目标);
- 只有在接收到不同的信号之后,原始的仓位才会改变。同时,该仓位会被平仓,下相反方向的订单。然后根据新的信号建立新的仓位;
Reward
我们考虑了市场摩擦因素的关键部分:交易费用δ和滑点ζ。
在时间t,账户收益的计算方式为(按收盘价计算):
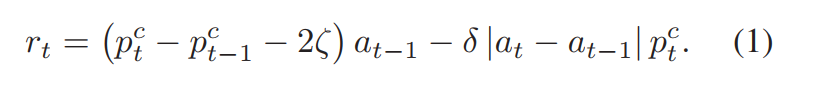
采用上述账户收益作为reward函数可能效果并不好。我们将差分的夏普比率作为reward函数,超额收益(累计收益减去无风险收益)与单位风险的比率:
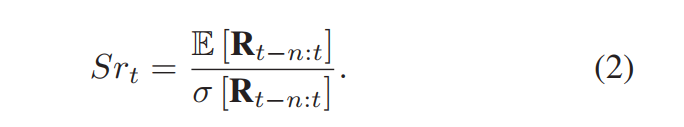
差分夏普比率:

Imitative RDPG
iRDPG的框架:
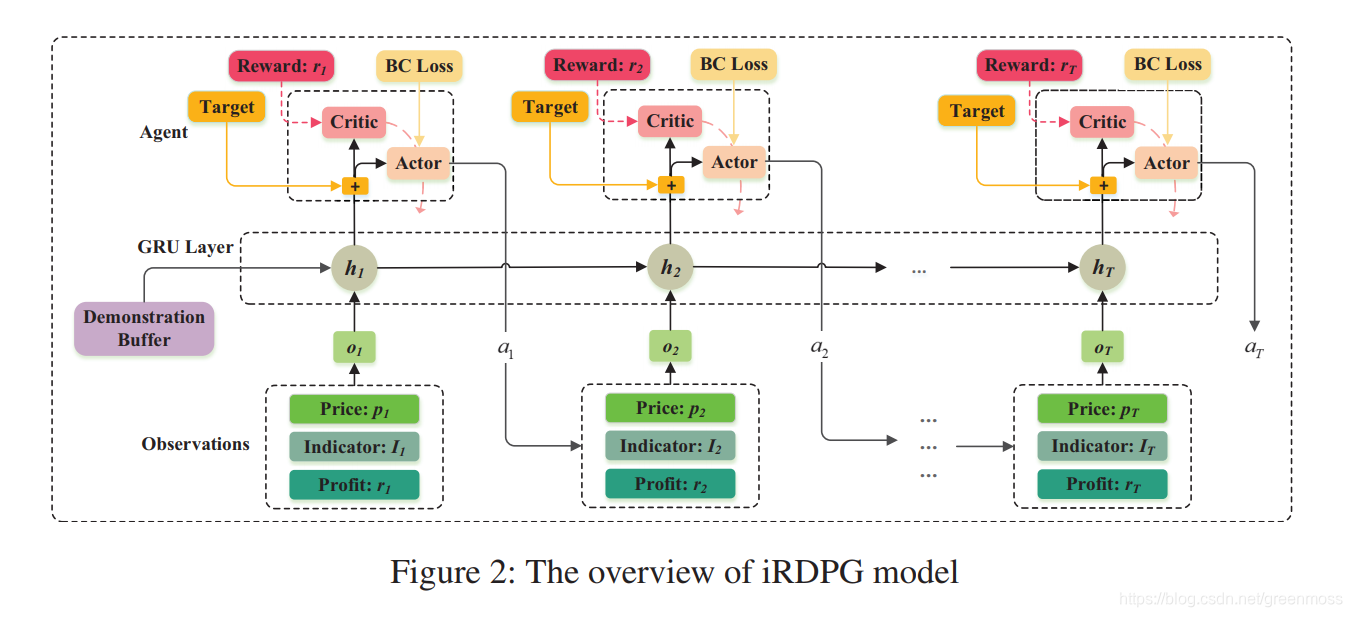
Recurrent Deterministic Policy Gradient
确定性的策略梯度Deterministic Policy Gradient (DPG)适用于连续控制问题。高频的量化交易非常关注交易的连续性,因为频繁交易的成本很高。所以采用Recurrent Deterministic Policy Gradient (RDPG)。
在我们的POMDP框架中,每个时间t,来自市场和个人账户的观察结果会输入agent。观察包括:市场价格、技术指标、账户收益。尽管潜在的市场状态不能全部直接观察到,我们的交易agent可能会从历史中学到一些东西。观察的动作历史可以描述为:
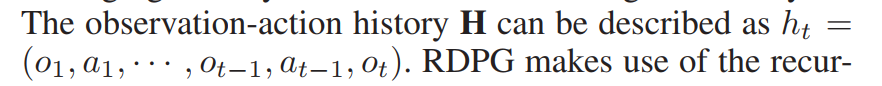

我们将GRU(the Gate Recurrent Unit)引入量化交易中。我们将之前的观察动作历史 h(t-1) 视为RNN在时间 t-1 返回的隐藏状态。
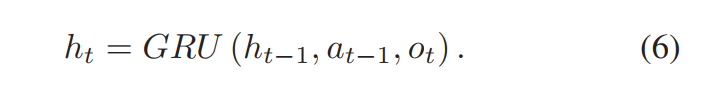
agent的动作可以写为:
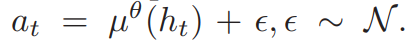
agent执行交易动作后,将获得市场和个人账户返回的reward d(t)和下一次的观察o(t+1)。达到最大时间长度后,整个episode放入优先重播缓冲区D(the prioritized replay buffer D)。随后,从缓冲区中取出N个(minibatch)完整的episode,用于模型更新。

Imitative Learning
model-free的强化学习算法在量化交易中效果不好。此外,还需要考虑交易的连续性和市场摩擦因素,没有目标的随机探索可能效率低下。但是,model-free的RDPG可以用于训练目标,是一种off-policy的方法。我们引入了演示缓冲区(demonstration buffer)和行为克隆(behavior cloning)来指导RDPG的agent,这两个模块分别代表被动和主动模仿学习算法。
Demonstration Buffer
最初,我们设置了优先重播的缓冲区D,D中存放的是来自Dual Thrust策略的演示episode。我们在实际交互前使用演示对agent进行预训练。借助技术分析预训练,agent可以在开始的时候学习基本的交易策略。在训练过程中,每个minibatch由演示和agent episode组成,通过优先经验重播(PER)进行采样。PER鼓励更频繁地采样更有价值的经验,P(i)被采样的概率与其优先级成正比:
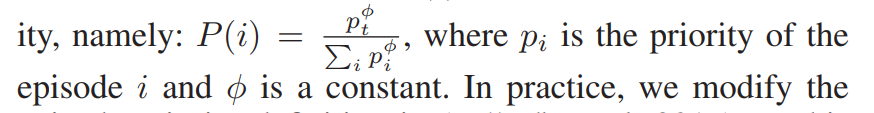
优先级的定义:

考虑到样本分布的变化,对网络的更新使用重要性采样进行加权:
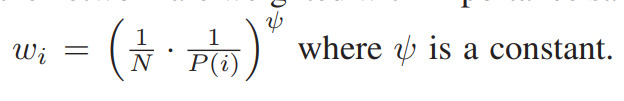
因此,优先演示缓冲区控制着演示和agent episode之间的数据比例。它可以有效地传播reward。
Behavior Cloning
为了给每个action设定目标,我们引入了单日内贪婪算法作为专家行为(假设可以预知未来的股票价格),总是以最低价格持有多头头寸,以最高价格持有空头头寸。对每个训练步骤,我们使用行为克隆技术来衡量agent动作和专家动作之间的差距。此外,我们仅在critic Q(h, a)表明专家动作比actor动作好的时候,才记录行为克隆的Loss(BC Loss):
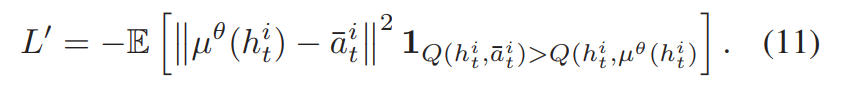
行为克隆的loss是辅助更新用的。因此,修改后的actor策略梯度如下:

在专家行动的帮助下,我们为每个训练步骤设定目标,缩短了低效探索的阶段。
Experiments
在具有实际约束的分钟频率期货数据上对我们的模型进行回溯测试。
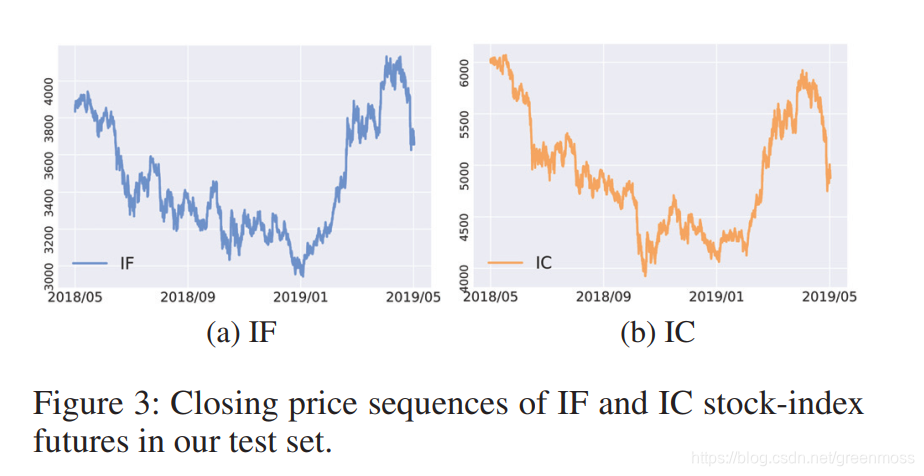
数据为IF和IC,IF是沪深300指数,IC是中证500指数,分钟频率的收盘价如图3所示:
Experimental Setup
在我们的实验中,我们使用期货的分钟数据:开盘、最高、最低、收盘价,用蜡烛图表示。我们从JoinQuant.com收集数据。
训练集:2016年1月1日到2018年5月8日,测试集为2018年5月9日到2019年5月8日。
我们考虑了交易费用和恒定的滑点:

此外,我们假设每个订单可以在每分钟的开盘时间进行交易,在每日收盘时计算收益。此外,还考虑了期货有关的保证金、交割等规则。一旦损失达到50%或缺乏保证金,训练的epoch将被打断。测试时,初始现金为50w元。
评价性能的指标:

Imitation Learning Detail
我们选择Dual Thrust策略作为演示交易策略。在技术分析领域,Dual Thrust是基于振荡器的代表性策略之一。Dual Thrust策略利用前n个周期的最高价、最低价和收盘价的序列来确定合理的价格振荡区间Range。在每个交易日,上面的曲线Buyline和下面的曲线Sellline以当日的开盘价加减一定比例的Range来确定。

实验中,当前价格突破Range上/下一定的百分比,交易者就认为形成了涨/跌的趋势。同时,执行多头/空头头寸。在时间t,演示动作可以表示为:

在行为克隆中,将单日内的贪婪算法作为专家的行动。以最低价做多,以最高价做空,是相对较好的贪婪策略。在训练中,这种预测策略可以作为专家动作。每个时间t,专家行动的计算方法如下:

Baseline Methods
我们将iRDPG与几个基准策略进行比较:
- Long & Hold:开始时持有多头头寸,一直持有直到结束,这只是期货本身的回报;
- Short & Hold:开始时持有空头头寸并一直持有;
- DDPG:off-policy model-free actor-critic的强化学习方法,常用于连续控制任务。
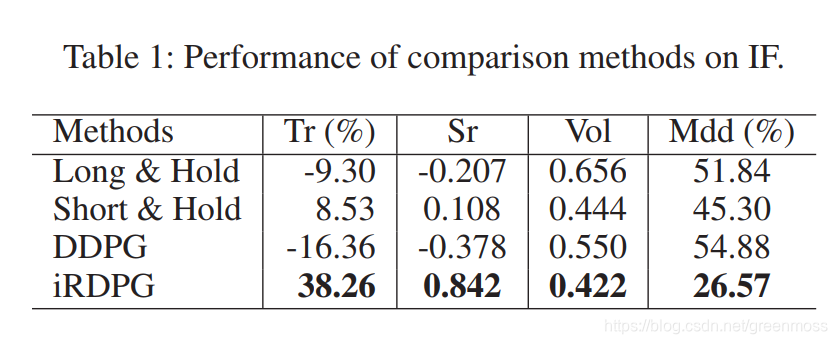
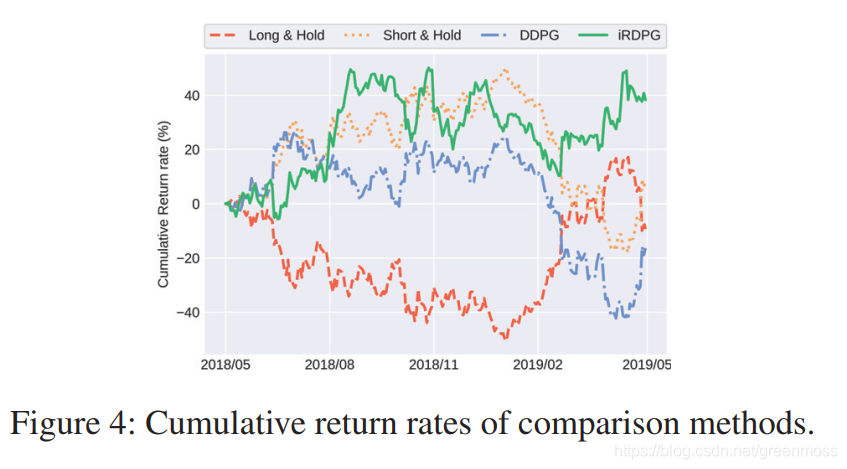
Experimental Results
本节中,我们将iRDPG与基准策略进行比较,并进行了消融实验。我们用两个不同的期货市场数据进行了实验。
Data Representation
Ablation Experiments 消融实验
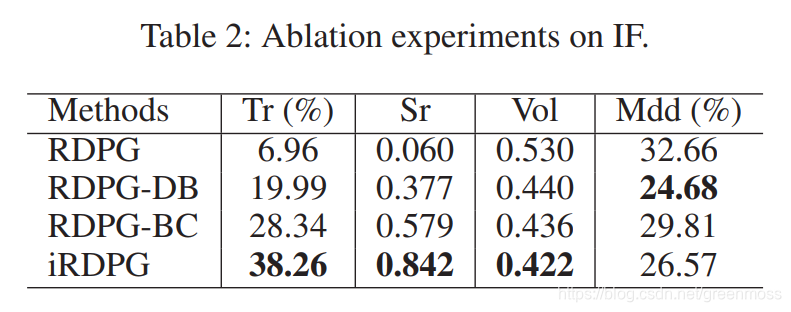
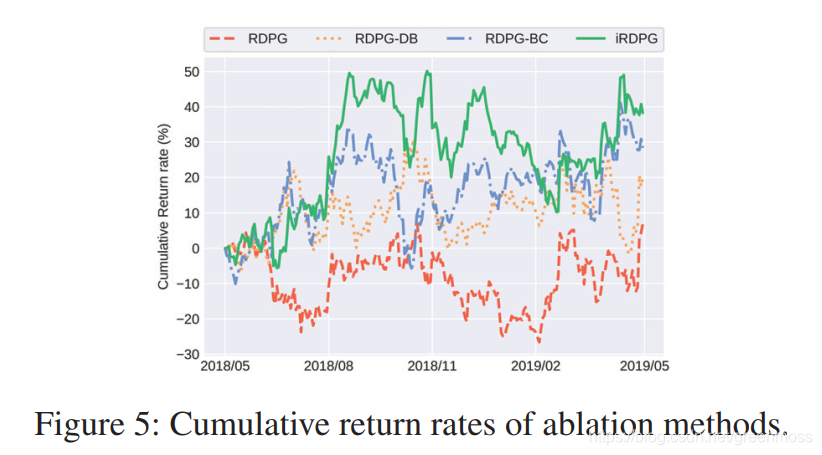
RDPG:只有GRU神经网络的iRDPG;
RDPG-DB:带有演示缓冲区的RDPG;
RDPG-BC:行为克隆的RDPG;
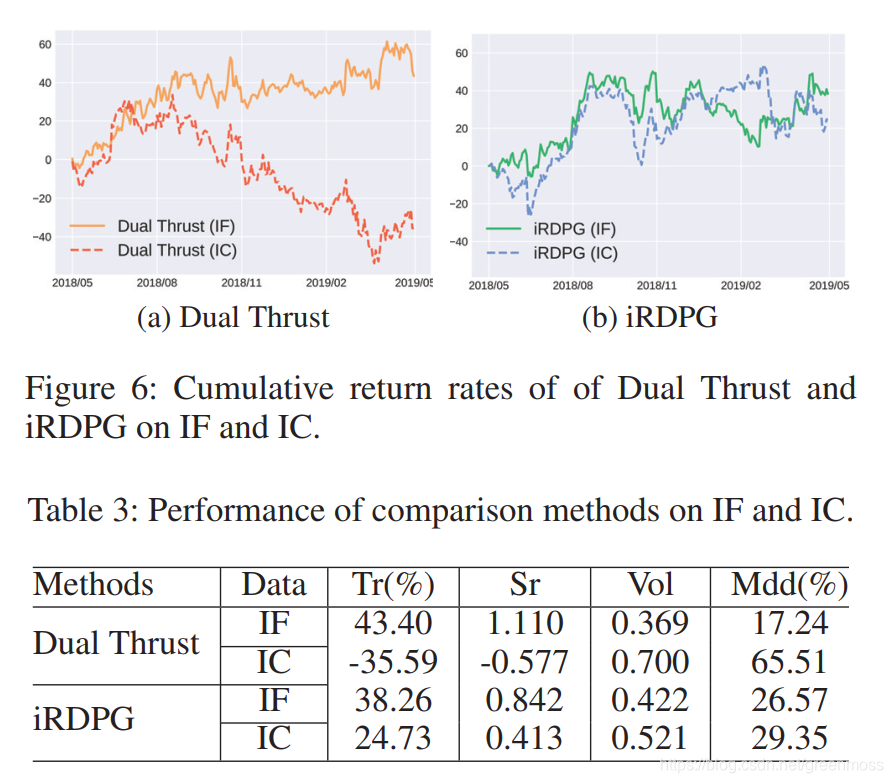
Generalization Ability 泛化能力
展示了iRDPG在不同市场(IF和IC)中的泛化能力。IF和IC具有相似的价格趋势,见图3。
我们在IF训练集中训练agent,分别在IF和IC测试集中进行测试。
Conclusion 结论
我们提出了iRDPG模型,设计了POMDP框架来表示分钟频率的金融数据。我们使用模仿学习来平衡agent的探索和利用。在实际股指期货数据上进行测试,验证了模型的盈利能力、抗风险能力和泛化能力。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









