







1、前言
本章节使用的是Apache Kafka,版本:kafka_2.11-2.1.0.tgz;但是实际工作中要考虑CDH环境,使用的是CDH官网的Kafka,所以这里先简单介绍下,如何集成到CDH中,请参考博客:
https://blog.csdn.net/greenplum_xiaofan/article/details/97677328
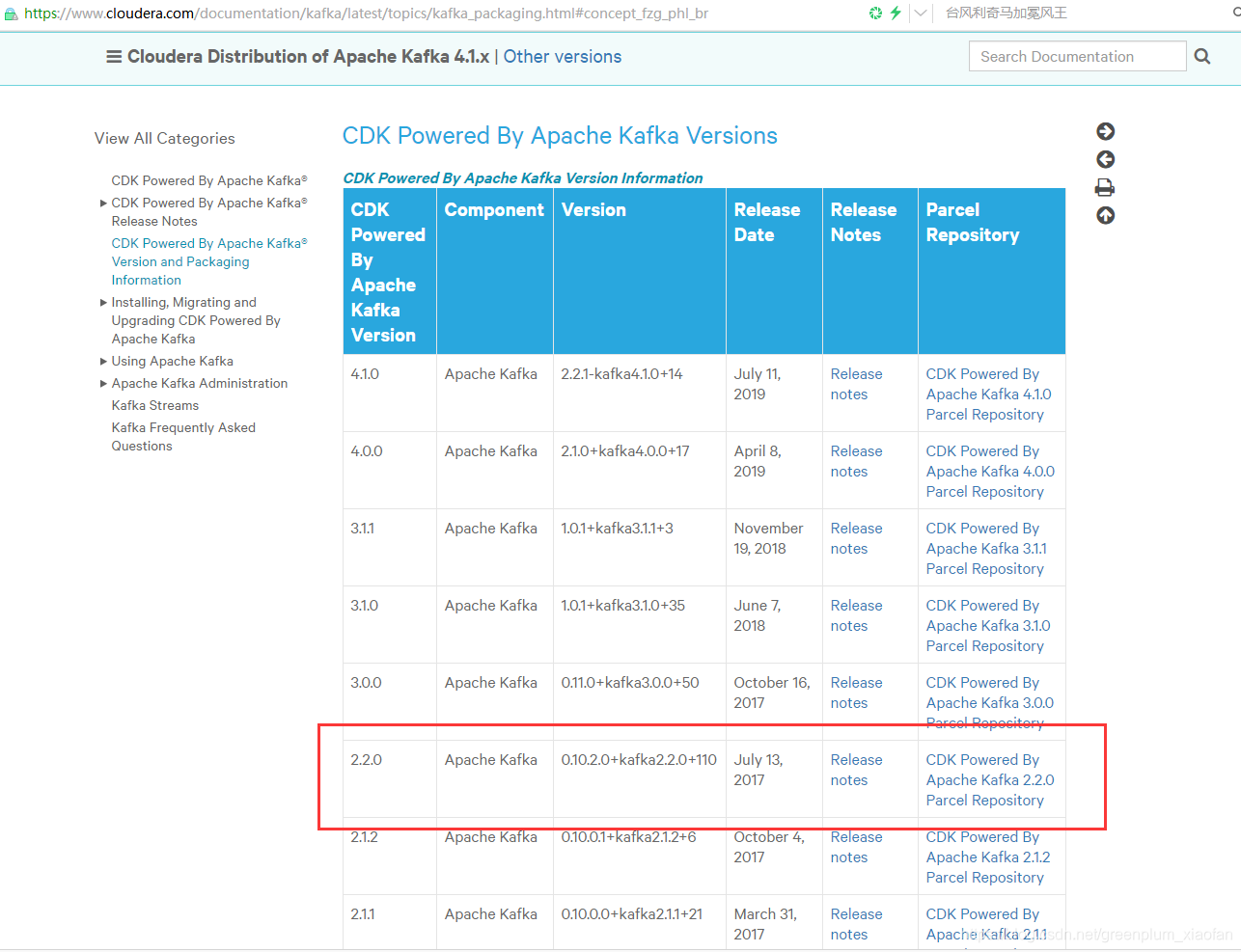
版本选择:使用的是CDH版本的Kafka,在CDH官网上叫做CDK。
比如:
kafka_2.11-0.10.2-kafka-2.2.0.jar
kafka_2.11::表示scala-2.11版本
0.10.2: 指在apache上的 kafka版本
2.2.0: 这个才是CDH官网上的CDK版本
CDK地址:
https://www.cloudera.com/documentation/kafka/latest/topics/kafka_packaging.html#concept_fzg_phl_br
Apache Kafka地址:
http://kafka.apache.org/
SparkStraming2.4.2版本官网推荐:apache kafka版本至少0.10.x及以上。
Kafka 0.8和0.10是个分水岭,对比如下(来自Spark官网):
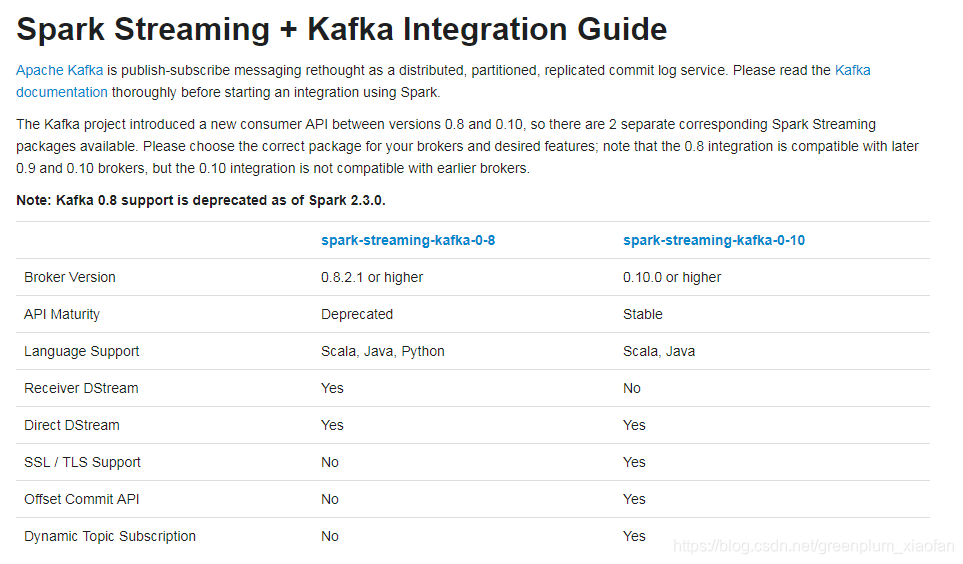
可以看出0.10版本,只有Direct DStream,不再支持Receiver DSstream;Offset维护在Kafka中。
2、Kafka基本概念
kafka是一个高吞吐的分布式消息系统,一般充当消息中间件,一般是跟流式处理挂钩的,比如SparkStreaming。
Kafka的三个角色:
- Broker:Kafka集群中server节点,负责读写请求,存储消息,管理分区,无主从关系,依赖zk协调
- Producer:生产者,负责生产消息,比如从Flume获取数据
- Consumer:消费者,负责消费消息,比如被SparkStreaming、Flink消费
Kafka这三个角色和Flume的三个角色非常类似,但Flume启动后只有一个进程,而Kafka每个角色都需要启动,有三个进程。
Kafka其他重要概念&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1968
1968











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









