






1、图示生态架构
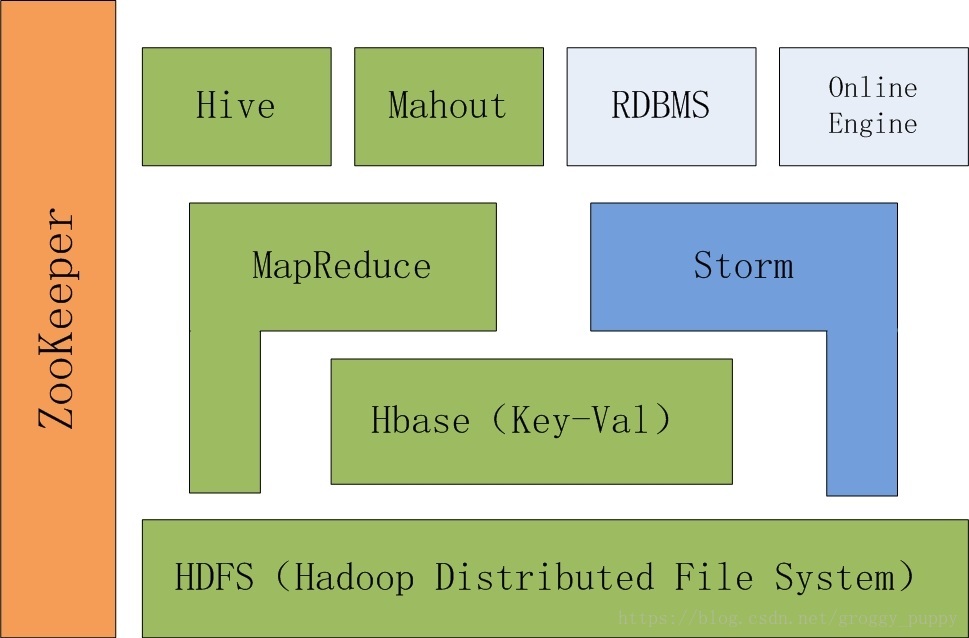
2、从低往上学
- HDFS
直译分布式文件系统,相当于windows机器上的视频、图片、文档等都是存到硬盘上,硬盘再需要做一些格式化。
在Hadoop上需要存储大数据,而且是存储在各个不同的机器上的。所以HDFS也就是一个分布式系统(分布式意思就是一个集群里面有很多台机器)。
HDFS作为一个最基本的文件系统就是存储大数据用的。
- Hbase(Key-Val)
列存取数据库,可以理解为一个数据库,也是一个分布式的数据库。
可以把数据存到HDFS上,也可以存到Hbase。那为什么要存到Hbase呢?
Hbase既然是一个数据库,那么就更侧重于结构化的数据,有字段和列等等,方便上游的读取,然后快速检索。
那为什么Hbase为什么要在HDFS之上呢?因为Hbase的数据基本上都存在了HDFS上,所以Hbase也可以理解为HDFS的一层框架,有利于数据的快速读取,但是实际上数据仍让存储在HDFS里。
这一层负责存储。例如日志收集与数据存储、和数据预处理(Hbase,把非结构化数据结构化,就是数据预处理)
- MapReduce和Storm
以上HDFS和Hbase都是帮我们解决了数据存储问题。那么数据要怎么应用呢,通常需要写程序,那么程序由谁来执行呢,由计算框架执行,也就是MapReduce,和Storm。MapReduce是整个Hadoop最核心的计算框架,由它来执行计算任务。
比如统计一篇文章每一个单词的出现次数,那么MapReduce就是我们写的程序,由整个程序来读取HDFS上的文件,然后具体数数过程需要自己写代码实现。
两者之间的区别:MapReduce适合做离线,Storm适合做在线。离线和在线后续再了解。
这一层只负责计算,不负责存储,后写入在线数据库(NoSql)。例如推荐策略算法模块
- Hive
像一个数据库,但是本质上更是一个语言的转化工具。之前习惯了使用SQL语句读写数据库,为了方便我们对大数据操作,通过Hive支持SQL语句,叫做HSQL。和标准的MySql有一些细节不一样,但是整体差不多。
相当于一个翻译程序,把Sql语句翻译给MapReduce,然后再由MapReduce作数据处理(HDFS和Hbase)
本质上也是一个MapReduce或多个MapReduce执行程序。
- Mahout
Mahout是在hadoop里封装的一个机器学习算法库,比如数据挖掘需要的分类算法、回归算法、推荐算法等等。主流算法Mahout都支持。提高效率。
Mahout和Hive一样,本质也是一个MapReduce或多个MapReduce,执行达到数据挖掘的目的。
Mahout是凌驾于整个计算框架之上的一个工具封装。
- Online Engine
在线检索引擎,这是一个Web Server。
每个计算框架生成的数据之所以能体现它的价值是因为它能实现对外服务,数据是怎么服务呢,就是通过Online Engine。
- Zookeeper
最拽的一个,横跨了这么多层。它是用来全局协调集群用的。Hbase和Storm需要zookeeper。
Hadoop2.0整套架构都是依赖于Zookeeper,Hadoop1.0不需要。
以上只是各个组件大概认知,只有在学习各个组件之后才有更多了解。














 1394
1394











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









