







目录
Kubernetes/KubeSphere 安装踩坑记:从 context deadline exceeded 到成功部署的完整排障笔记
Kubernetes/KubeSphere 安装踩坑记:从 context deadline exceeded 到成功部署的完整排障笔记
适用版本:Kubernetes 1.31.x / KubeSphere 4.1
运行时:containerd
操作系统:CentOS 7.9
一、问题现象
执行 ./kk create cluster -f config-sample.yaml 初始化节点,安装脚本在 wait-control-plane 阶段反复重试并最终报错:
context deadline exceeded
error execution phase wait-control-plane: could not initialize a Kubernetes cluster
此时主节点 kubelet 日志刷屏,集群始终无法启动。
二、第一手日志采集
# kubelet 当前状态
systemctl status kubelet -l
# 10 分钟内关键错误
sudo journalctl -u kubelet --since "10 minutes ago" | grep -Ei "error|failed|cgroup"
核心错误片段:
failed to get sandbox image "registry.k8s.io/pause:3.8":
dial tcp 173.194.203.82:443: i/o timeout
以及后续安装 KubeSphere 组件时:
failed to pull image "docker.io/kubesphere/kube-apiserver:v1.31.0":
500 Internal Server Error
三、定位思路
| 线索 | 结论 |
|---|---|
| pod sandbox 创建失败 无法拉取 pause:3.8 | 根因:国外镜像仓库被墙,pull 超时 |
| kube-apiserver 镜像 500 错误 | Docker Hub 临时故障 / 国内网络劣化 |
两个核心镜像拉取失败 → kubelet 无法启动沙箱容器 → control plane 卡死。
四、分步解决
详细离线导入方法请见:
《从零实现 registry.k8s.io/pause:3.8 镜像的导出与导入》
《从零实现 crictl pull kubesphere/kube-apiserver:v1.31.0 的全流程操作》
4-1 处理 pause:3.8
-
在能出网的跳板机
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.8 docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.8 \ registry.k8s.io/pause:3.8 docker save registry.k8s.io/pause:3.8 -o pause-3.8.tar -
拷贝至目标节点并导入 containerd
scp pause-3.8.tar node1:/tmp/ sudo ctr -n k8s.io images import /tmp/pause-3.8.tar -
确认导入成功
crictl images | grep pause
4-2 处理 kube-apiserver:v1.31.0
-
预拉镜像并导出
docker pull kubesphere/kube-apiserver:v1.31.0 docker save kubesphere/kube-apiserver:v1.31.0 -o kube-apiserver-1.31.0.tar -
目标节点导入
sudo ctr -n k8s.io images import kube-apiserver-1.31.0.tar
技巧:直接用
crictl pull --image-endpoint也行,但离线文件更稳妥,可反复使用。
五、再次安装并验证
./kk create cluster -f config-sample.yaml --with-local-storage
-
kubelet 不再报
failed to get sandbox image。 -
control-plane 组件全部
Running。 -
kubectl get node -o wide显示所有节点Ready。
六、经验总结
| 类别 | 建议 |
|---|---|
| 镜像策略 | 对所有 基础镜像(pause、coredns、etcd) 与 控制面镜像 预先离线导入,彻底规避外网依赖 |
| containerd 命名空间 | 使用 ctr -n k8s.io images import,否则镜像导入到 default 后 kubelet 依旧找不到 |
| crictl 调试 | `crictl ps -a |
| 自动化脚本 | 建议编写 image-cache.sh 批量处理 docker pull/tag/save,上线时一键导入 |
| 网络排障 | 镜像 HEAD/GET 超时 ≈ DNS 劫持 / 443 被阻断,优先切换国内镜像源或自建 Harbor |
七、尾声
这次“context deadline exceeded” 看似是 kubeadm 的错误,实则暴露了离线镜像策略的不完备。只要掌握 日志定位 → 镜像补全 → 再次验证 的闭环套路,类似问题能在 10 分钟内搞定。希望本文的实战笔记能帮助你在下一次部署 Kubernetes / KubeSphere 时一路绿灯 🚦。
以下是完整的错误记录
报错详情
Unfortunately, an error has occurred:
context deadline exceeded
This error is likely caused by:
- The kubelet is not running
- The kubelet is unhealthy due to a misconfiguration of the node in some way (required cgroups disabled)
If you are on a systemd-powered system, you can try to troubleshoot the error with the following commands:
- 'systemctl status kubelet'
- 'journalctl -xeu kubelet'
Additionally, a control plane component may have crashed or exited when started by the container runtime.
To troubleshoot, list all containers using your preferred container runtimes CLI.
Here is one example how you may list all running Kubernetes containers by using crictl:
- 'crictl --runtime-endpoint unix:///run/containerd/containerd.sock ps -a | grep kube | grep -v pause'
Once you have found the failing container, you can inspect its logs with:
- 'crictl --runtime-endpoint unix:///run/containerd/containerd.sock logs CONTAINERID'
error execution phase wait-control-plane: could not initialize a Kubernetes cluster
To see the stack trace of this error execute with --v=5 or higher: Process exited with status 1
14:35:44 CST retry: [node1]
检查日志 systemctl status kubelet
看到报错内容
Apr 23 14:39:42 node1 kubelet[44232]: E0423 14:39:42.697307 44232 eviction_manager.go:285] "Eviction manager: failed to get summary stats" err="failed to get node info: node \"node1\" not found"
Apr 23 14:39:48 node1 kubelet[44232]: E0423 14:39:48.736613 44232 event.go:368] "Unable to write event (may retry after sleeping)" err="Post \"https://lb.kubesphere.local:6443/api/v1/namespaces/default/events\": dial tcp 10.33.34.166:6443: connect: connection refused" event="&Event{ObjectMeta:{node1.1838df18aab26a9c default 0 0001-01-01 00:00:00 +0000 UTC <nil> <nil> map[] map[] [] [] []},InvolvedObject:ObjectReference{Kind:Node,Namespace:,Name:node1,UID:node1,APIVersion:,ResourceVersion:,FieldPath:,},Reason:NodeHasSufficientMemory,Message:Node node1 status is now: NodeHasSufficientMemory,Source:EventSource{Component:kubelet,Host:node1,},FirstTimestamp:2025-04-23 14:35:52.642095772 +0800 CST m=+0.729483809,LastTimestamp:2025-04-23 14:35:52.642095772 +0800 CST m=+0.729483809,Count:1,Type:Normal,EventTime:0001-01-01 00:00:00 +0000 UTC,Series:nil,Action:,Related:nil,ReportingController:kubelet,ReportingInstance:node1,}"
Apr 23 14:39:49 node1 kubelet[44232]: E0423 14:39:49.241750 44232 controller.go:145] "Failed to ensure lease exists, will retry" err="Get \"https://lb.kubesphere.local:6443/apis/coordination.k8s.io/v1/namespaces/kube-node-lease/leases/node1?timeout=10s\": dial tcp 10.33.34.166:6443: connect: connection refused" interval="7s"
Apr 23 14:39:49 node1 kubelet[44232]: I0423 14:39:49.468021 44232 kubelet_node_status.go:72] "Attempting to register node" node="node1"
Apr 23 14:39:49 node1 kubelet[44232]: E0423 14:39:49.468592 44232 kubelet_node_status.go:95] "Unable to register node with API server" err="Post \"https://lb.kubesphere.local:6443/api/v1/nodes\": dial tcp 10.33.34.166:6443: connect: connection refused" node="node1"
Apr 23 14:39:52 node1 kubelet[44232]: E0423 14:39:52.698356 44232 eviction_manager.go:285] "Eviction manager: failed to get summary stats" err="failed to get node info: node \"node1\" not found"
Apr 23 14:39:53 node1 systemd[1]: Stopping kubelet: The Kubernetes Node Agent...
Apr 23 14:39:53 node1 systemd[1]: kubelet.service: Deactivated successfully.
Apr 23 14:39:53 node1 systemd[1]: Stopped kubelet: The Kubernetes Node Agent.
Apr 23 14:39:53 node1 systemd[1]: kubelet.service: Consumed 5.322s CPU time.
仔细检查日志, 发现报错
sudo journalctl -u kubelet --since "10 minutes ago" | grep -iE "error|cgroup|failed"
Apr 23 15:17:13 node1 kubelet[48293]: E0423 15:17:13.238787 48293 log.go:32] "RunPodSandbox from runtime service failed" err="rpc error: code = Unknown desc = failed to get sandbox image \"registry.k8s.io/pause:3.8\": failed to pull image \"registry.k8s.io/pause:3.8\": failed to pull and unpack image \"registry.k8s.io/pause:3.8\": failed to resolve reference \"registry.k8s.io/pause:3.8\": failed to do request: Head \"https://us-west2-docker.pkg.dev/v2/k8s-artifacts-prod/images/pause/manifests/3.8\": dial tcp 173.194.203.82:443: i/o timeout"
解决pause:3.8的问题参考文章 从零实现 registry.k8s.io/pause:3.8 镜像的导出与导入
另外查看日志也可能遇到 kube-apiserver下载失败的情况
pull image failed: Failed to exec command: sudo -E /bin/bash -c "env PATH=$PATH crictl pull kubesphere/kube-apiserver:v1.31.0"
E0424 10:32:36.669380 14293 remote_image.go:180] "PullImage from image service failed" err="rpc error: code = Unknown desc = failed to pull and unpack image \"docker.io/kubesphere/kube-apiserver:v1.31.0\": failed to resolve reference \"docker.io/kubesphere/kube-apiserver:v1.31.0\": unexpected status from HEAD request to https://docker.1ms.run/v2/kubesphere/kube-apiserver/manifests/v1.31.0?ns=docker.io: 500 Internal Server Error" image="kubesphere/kube-apiserver:v1.31.0"
FATA[0031] pulling image: failed to pull and unpack image "docker.io/kubesphere/kube-apiserver:v1.31.0": failed to resolve reference "docker.io/kubesphere/kube-apiserver:v1.31.0": unexpected status from HEAD request to https://docker.1ms.run/v2/kubesphere/kube-apiserver/manifests/v1.31.0?ns=docker.io: 500 Internal Server Error: Process exited with status 1
10:32:36 CST retry: [node1]
参考: 从零实现 crictl pull kubesphere/kube-apiserver:v1.31.0 的全流程操作
然后再执行安装即可成功了
./kk create cluster -f config-sample.yaml --with-local-storage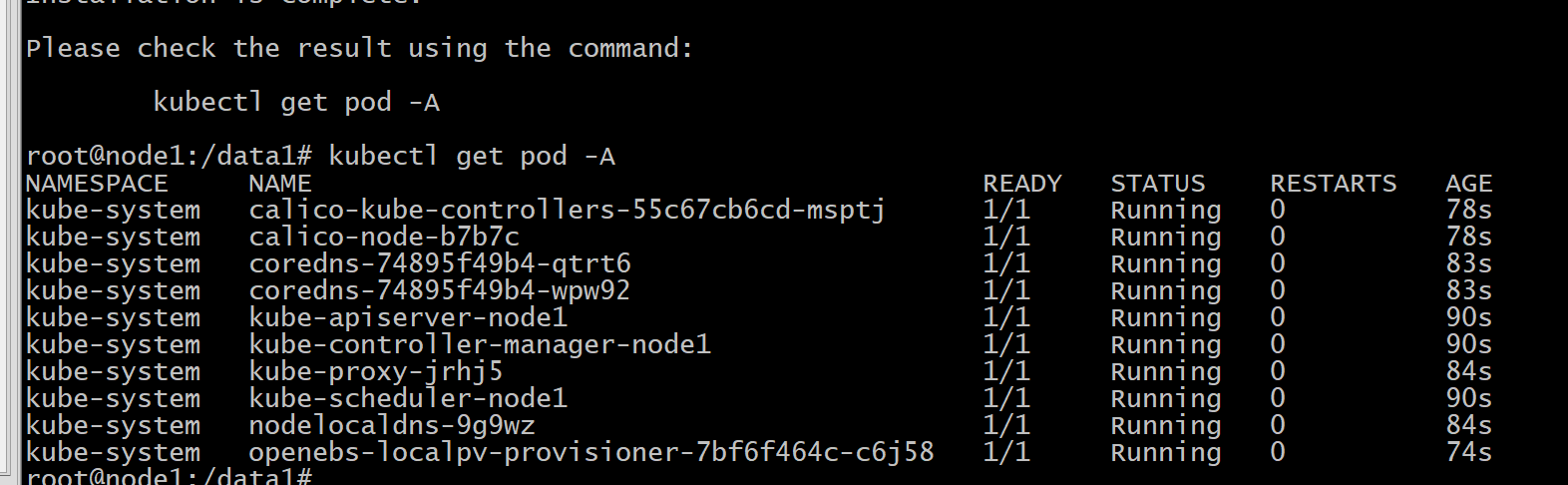


















 1222
1222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









