






k8s源于google的borg集群管理系统,是cncf云原生的重要一员。是目前容器编排的事实标准,提供了集群编排、弹性伸缩、滚动更新回滚、自愈等多种能力。
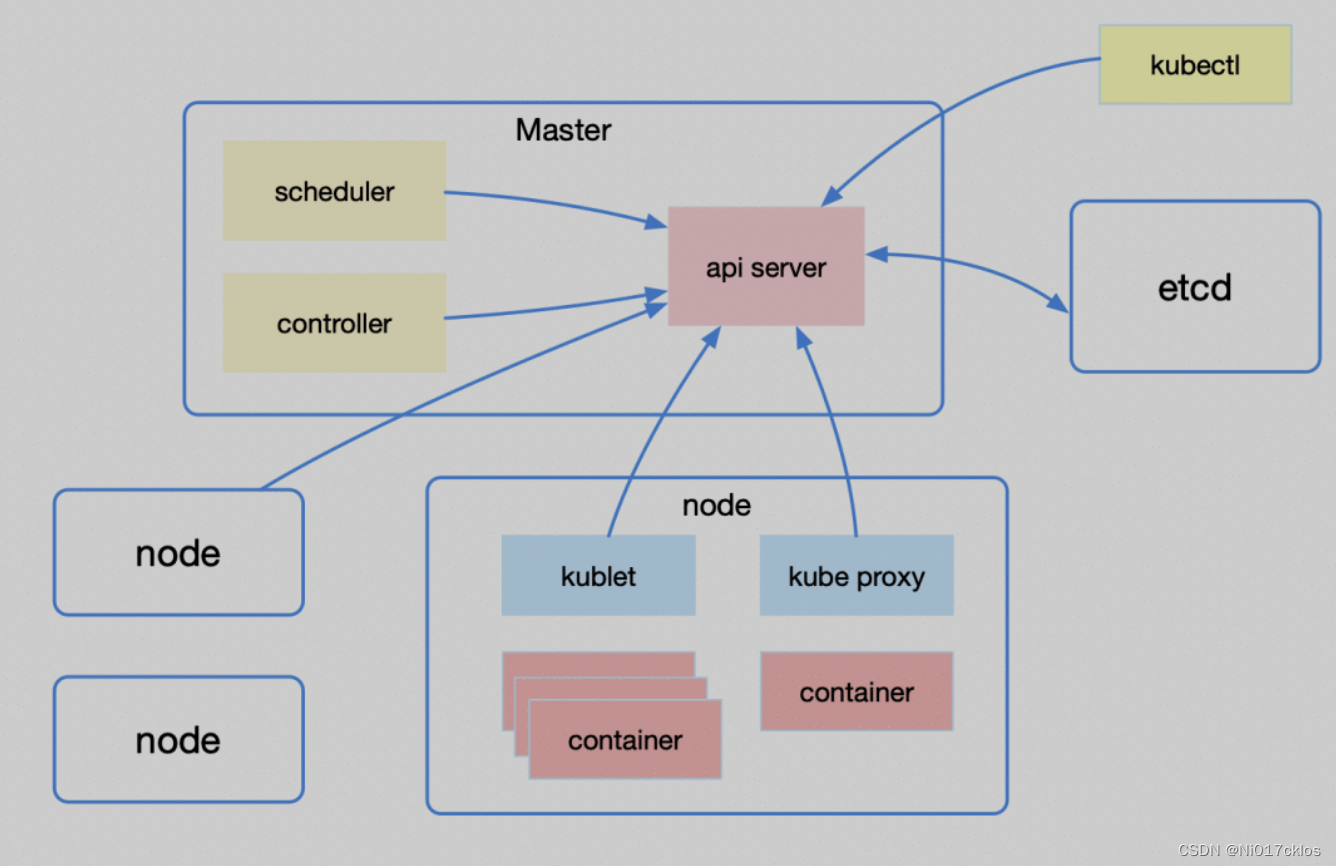
一、 k8s主要部件:
1.1 master 主节点,负责控制整个k8s集群
1.1.1 apiserver 提供操作k8s资源的统一入口
1.1.2 scheduler:按照一定的规则把pod调度到合适的node上
1.1.3 controller:资源控制中心,确保资源处于预期的工作状态
1.2 node 工作节点。容器工作的地方,提供计算能力
1.2.1 kubelet: 管理容器的生命周期,通过cAdvisor监控节点的工作状态,健康检查,定期上报自身节点的状态
1.2.2 kube-proxy:负载均衡,服务发现;同时监听services/endpoints变化并刷新负载均衡
1.3 etcd:所有服务都在这里注册,提供高可用高一致性的键值存储服务
1.4 kubectl:命令工具
二、k8s工作流程
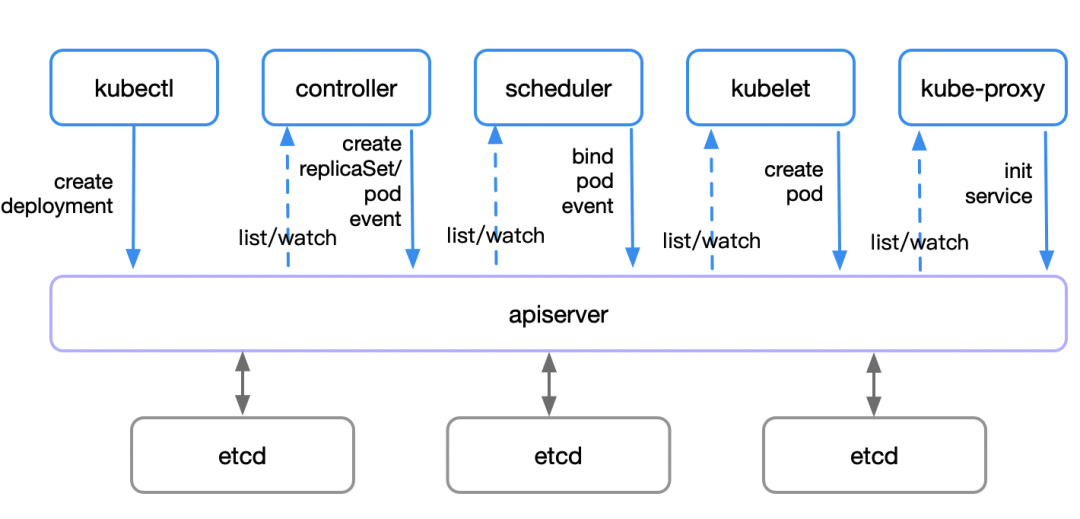
deployment是用于编排pod的控制器资源,以此为例:
2.1 使用kubectl create 命令发起创建deployment请求
2.2 apiserver收到请求,将相关资源写入etcd
2.3 deployment controller list/watch资源变化并发起rs创建请求
2.4 rs controller list/watch资源变化并发起创建pod的请求
2.5 scheduler 检测到有个pod未绑定,随即通过规则匹配和过滤以后,将pod调度到合适的node上
2.6 该node上的kubelet这时发现需要创建新的pod,开始着手创建,在完成以后负责对该pod的生命周期管理
2.7 该node上的kube-proxy负责提供该pod的service初始化资源,包括网络规划、负责均衡、服务发现等
各组件分工合作,共同完成一个service从deployment创建请求到pod创建完成,再到对外提供可用的service的过程。
三、pod
pod是k8s最小最基础的部署单元。通过把若干个紧密相连的容器封装在一起,共享网络、存储、pod配置等资源,就像处于同一物理主机上一样。同一pod的几个container通过infra contianer的方式统一识别外部网络,通过挂在同一份volume就自然可以共享存储。
k8s不能直接管理容器,因此就算一个容器也需要通过pod创建和管理
四、容器编排
无状态的应用deployment、有状态的statefulSet、后台守护进程daemonSet、离线业务job等都是k8s都在编排服务之列。
以deployment为例。
deployment、rs、pod是层层控制的关系,通过这种架构可以实现许多平滑操作,这也是rs存在的重大意义。rs可以控制pod的数量,deployment则控制rs的版本
一、水平扩缩容
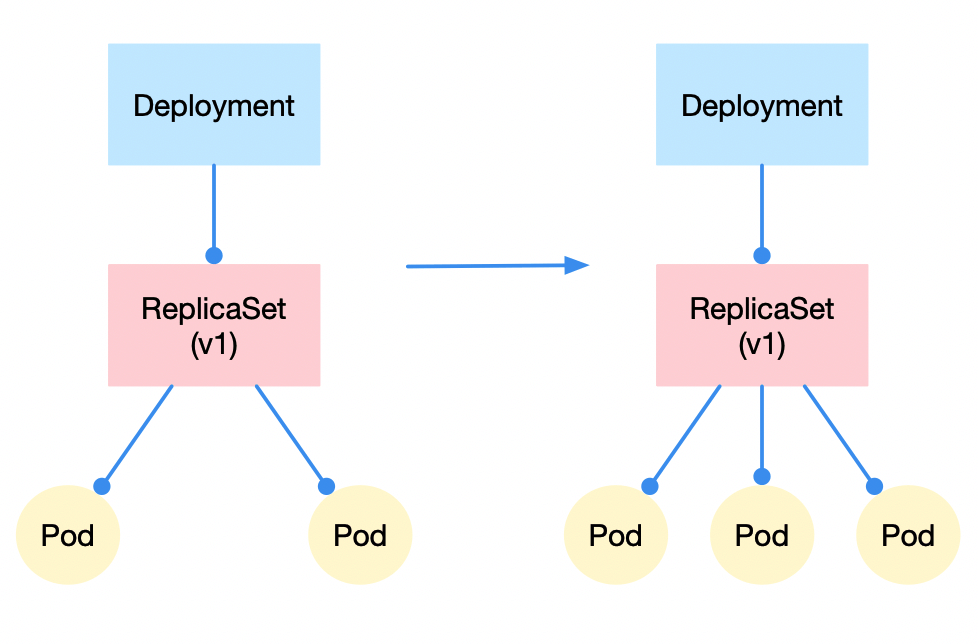
修改rs的pod控制数量,比如从2修改成3,即可完成水平扩容,反之则为缩容
二、升级/回滚
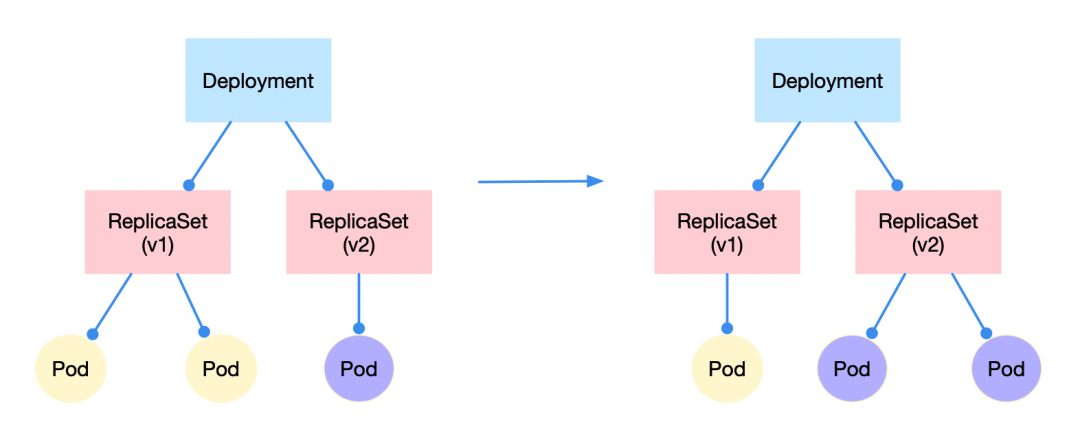
此功能体现了rs的必要性。将不同的rs设置为不同的版本,如图。这时只要修改v1的数量,假设从3到0,修改v2的数量从0到3,那么v1为0、v2为3到时候,就代表升级完成
反正则可视为回滚。
三、滚动更新
在实际过程中,我们通过rollingUpdateStrategy来控制滚动更新策略,maxSurge设置deployment最多还可以创建多少个pod,maxUnavailable设置最多可以删除多少个旧pod
pod总是一个一个升级,通过上面的设置,我们可以保证最少有2个pod处于可用状态,最多有4个pod提供服务。这种“滚动更新”的好处是,一旦新的版本有bug,那么剩下的2个pod仍可以正常服务,同时方便快速回滚。
四、k8s的网络
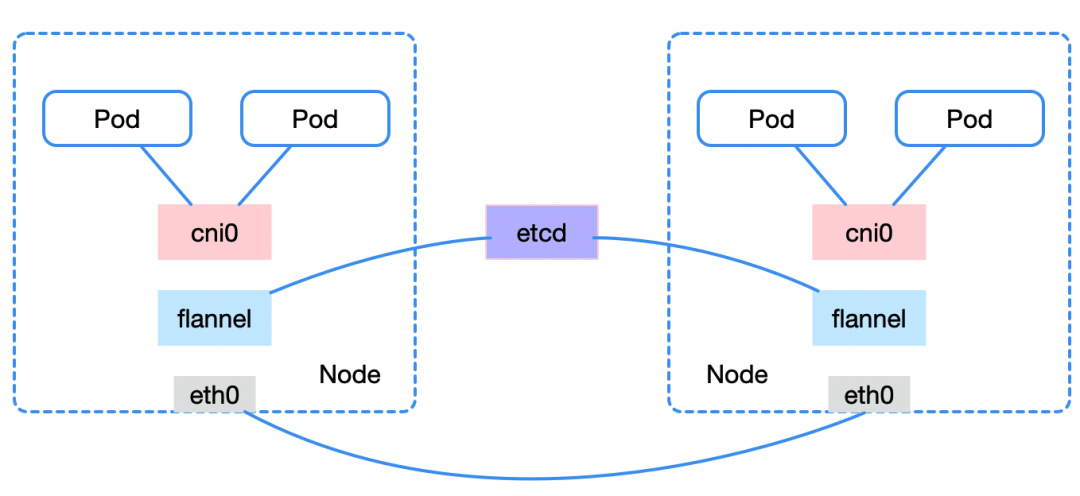
k8s的网络有三个方面:
1.node-pod的通信:通过cni0/docker0网桥实现
2.同一个node里面,不同pod之间的通信:通过cni0/docker0网桥实现
3.不同node里面,pod之间的通信:比较普遍的做法是通过flannel的vxlan/hostgw实现,flannel通过etcd获知其他node的网络信息,并会为本node创建路由表,最终使得不同node间实现通信。
flannel:为每个使用 Kubernetes 的机器提供一个子网
总结:同一个node,通过cni0/docker0网桥实现;不同node则由flannel通过etcd获得
五、service
每个pod对应着一个实例,而每个service则对应着一个微服务
service主要解决两个问题:
1.每个pod的ip都不是固定的,访问不固定的ip并不现实
2.调用服务时,也需要对不同pod进行负载均衡
总之:一般情况下,属于同一个微服务的不同pod,都会打上app=xxx都标签,该微服务也会打上app=xxx都标签选择器。然后service通过label标签选择器选择合适的pod,构建一个负载均衡列表(endpoints),此后访问这个service就能负载均衡地访问到不同的pod
六、服务发现与网络调用
6.1 横向流量的访问,即微服务间的调用
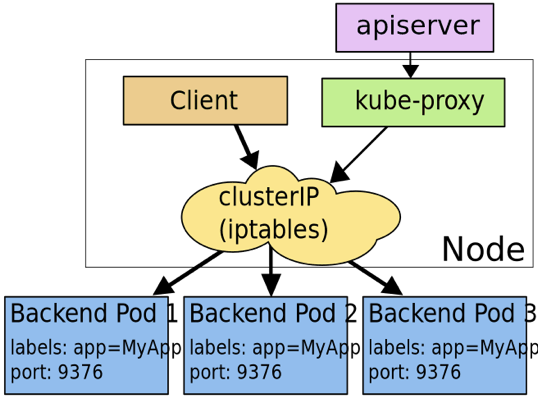
分为:clusterIP模式和dns模式
6.1.1 clusterIP模式
通过iptables/ipvs为服务创建一个虚拟ip(vip),只有访问这个虚拟ip,即可负载均衡地访问到service背后的pod
6.1.2 dns模式
比较好理解,就是通过dns方式将一个service-name的a记录指向clusterip,随后通过service-name即可访问到clusterip背后的服务
6.2 纵向流量的访问,即外部访问k8s
6.2.1 nodePort方式
通过iptables赋予通过访问某个端口就能访问到宿主机对应的pod的能力
6.2.2 loadbalancer
通过公有云的负载均衡器实现
6.2.3 ingress
这种方式成为service的service
因为上两种方式,100个pod就需要创建100个nodeport/loadbalancer。这时我们会希望通过统一的接入层来访问k8s,这就是ingress的能力。
ingress通过统一的访问层,然后通过路由的不同匹配到后端的不同service上
七、借鉴文档















 1412
1412











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









