







前言
WHY 云:为什么我们需要云,大数据时代我们面对两个问题,一个是大数据的存储,一个是大数据的计算。由于数据量过大,在单个终端上运行效率过差,所以人们用云来解决这两个问题。
WHAT IS 云:云得益于分布式计算的思想。举个简单的例子,执行一千万个数据每个数据都乘以10并输出,在个人pc上需要大概20分钟。如果是100台电脑做这个工作,可能只用几十秒就可以完成。云就是我们将复杂的工作通过一定的算法分配给云端的n个服务器,这样可以大大提高运算效率。
How 云:云的实现也就是分步式计算的过程。分布式的思想起源于MapReduce,是google最先发表的一篇论文中提到的,现在很多的分布式计算方法都是从中演变过来的。大体的思路是,将任务通过map分离——计算——合并——reduce——输出。
云的价值不光是存储数据,更是用来分析和处理数据,得益于云,更多的算法可以快捷的实现,所以说云计算和大数据倔是不可分割的,可能大家在平时的学习过程中还没有机会在云端接触大数据运算,下面就分享一下本人的一次云计算的经历。
1.背景
2.工具的简单说明
select distinct * from table_name;
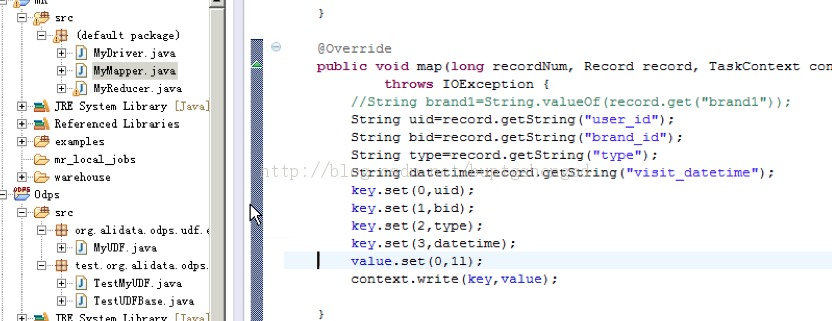
3.TRY


信息理论的鼻祖之一Claude E. Shannon把信息(熵)定义为离散随机事件的出现概率。说白了就是信息熵的值越大就表明这个信息集越混乱。
信息熵的计算公式,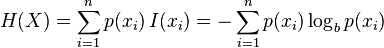 (建议去wiki学习一下)
(建议去wiki学习一下)
这里我们通过计算目标指数的熵和特征值得熵的差,也就是熵的增益来确定哪些特征值对于目标指数的影响最大。
第一部分-计算熵:函数主要是找出有几种目标指数,根据他们出现的频率计算其信息熵。
- def calcShannonEnt(dataSet):
- numEntries=len(dataSet)
- labelCounts={}
- for featVec in dataSet:
- currentLabel=featVec[-1]
- if currentLabel not in labelCounts.keys():
- labelCounts[currentLabel]=0
- labelCounts[currentLabel]+=1
- shannonEnt=0.0
- for key in labelCounts:
- prob =float(labelCounts[key])/numEntries
- shannonEnt-=prob*math.log(prob,2)
- return shannonEnt
第二部分-分割数据 因为要每个特征值都计算相应的信息熵,所以要对数据集分割,将所计算的特征值单独拿出来。
- def splitDataSet(dataSet, axis, value):
- retDataSet = []
- for featVec in dataSet:
- if featVec[axis] == value:
- reducedFeatVec = featVec[:axis] #chop out axis used for splitting
- reducedFeatVec.extend(featVec[axis+1:])
- retDataSet.append(reducedFeatVec)
- return retDataSet
第三部分-找出信息熵增益最大的特征值
- def chooseBestFeatureToSplit(dataSet):
- numFeatures = len(dataSet[0]) - 1 #the last column is used for the labels
- baseEntropy = calcShannonEnt(dataSet)
- bestInfoGain = 0.0; bestFeature = -1
- for i in range(numFeatures): #iterate over all the features
- featList = [example[i] for example in dataSet]#create a list of all the examples of this feature
- uniqueVals = set(featList) #get a set of unique values
- newEntropy = 0.0
- for value in uniqueVals:
- subDataSet = splitDataSet(dataSet, i, value)
- prob = len(subDataSet)/float(len(dataSet))
- newEntropy += prob * calcShannonEnt(subDataSet)
- infoGain = baseEntropy - newEntropy #calculate the info gain; ie reduction in entropy
- if (infoGain > bestInfoGain): #compare this to the best gain so far
- bestInfoGain = infoGain #if better than current best, set to best
- bestFeature = i
- return bestFeature #returns an integer
- def createTree(dataSet,labels):
- #把所有目标指数放在这个list里
- classList = [example[-1] for example in dataSet]
- #下面两个if是递归停止条件,分别是list中都是相同的指标或者指标就剩一个。
- if classList.count(classList[0]) == len(classList):
- return classList[0]
- if len(dataSet[0]) == 1:
- return majorityCnt(classList)
- #获得信息熵增益最大的特征值
- bestFeat = chooseBestFeatureToSplit(dataSet)
- bestFeatLabel = labels[bestFeat]
- #将决策树存在字典中
- myTree = {bestFeatLabel:{}}
- #labels删除当前使用完的特征值的label
- del(labels[bestFeat])
- featValues = [example[bestFeat] for example in dataSet]
- uniqueVals = set(featValues)
- #递归输出决策树
- for value in uniqueVals:
- subLabels = labels[:] #copy all of labels, so trees don't mess up existing labels
- myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value),subLabels)
- return myTree
4.具体实现
(1)特征提取
 ,就会变为一条曲线,更容易实现拟合。
,就会变为一条曲线,更容易实现拟合。
(2)随机森林参数调试

5.总结
 (
github.com/jimenbian
,里面有很多算法的实现。
(
github.com/jimenbian
,里面有很多算法的实现。
/********************************
* 本文来自博客 “李博Garvin“
* 转载请标明出处:http://blog.csdn.net/buptgshengod
******************************************/















 1567
1567

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









