







自己的理解:
根据几个图像,找出来一个关键字可以代表它们,然后我们可以再用这个关键字去生成新的东西。
提出关键字
1 Introduction
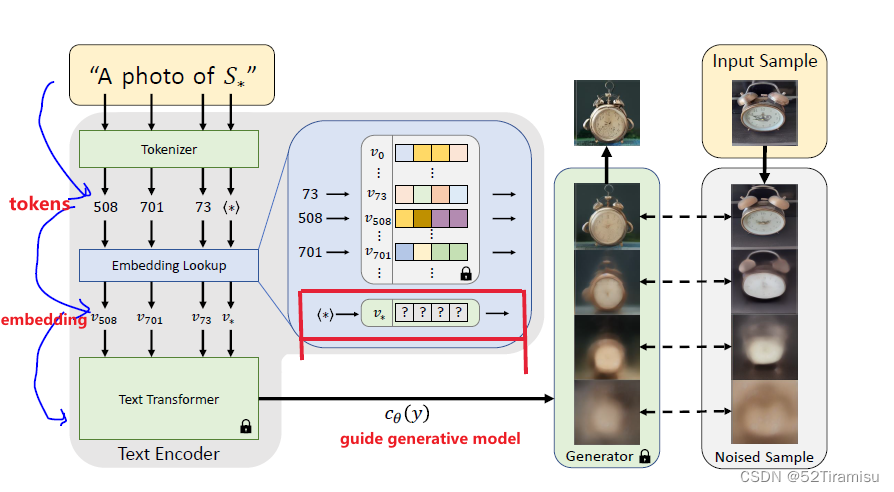
word->token->embedding
Textual Inversion过程
需要:
① a fixed, pre-trained text-to-image model (一个固定的预训练模型)
② a small image set depicting the concept(一个描述概念的小图像集)
目标:
find a single word embedding, such that "A photo of S*" will lead to the reconstructions of images from our small set
3 Method
LDM
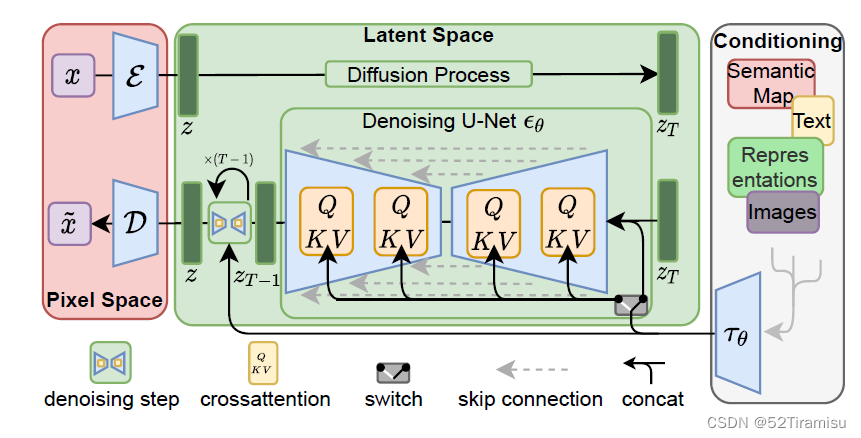
包含两个核心组件:
1.AutoEncoder
Encoder,把
Decoder
2.Diffusion Model
LDM Loss
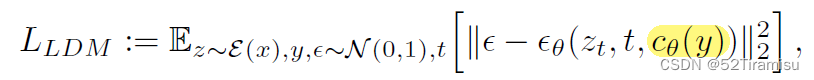

Text embedding

典型的文本编码器(例如 BERT)都从文本处理步骤开始
① word (in a input string) convert to a token ( an index in some pre-defined dictionary某个预定义词典中的索引)
构建一个词汇表,包含数据集中出现的所有唯一token,通常是一个字典,将每个token映射到唯一的整数ID。
②each token then linked to a embedding vector (可以通过基于索引的查找来检索。)
对于每个token,使用词汇表的ID可以查找其对应的 embedding vector。
③learned as part of the text encoder c_{\theta}
in our work
定义一个 placeholder string S_*,表示我们想要学习的 new concept
干涉 embedding process,用 embedding v_* 取代 与标记符相关的向量(本质上是把这个词注入到我们的词典中)
小结:
一串字符串文本,它的每个词可以通过 分词器 变为若干个 token,每个token可以映射到一个词向量,我们通过干预它映射词向量的过程,学得一个可以代表新特征的伪词。
Text Inversion
用 3-5张图片 depict 目标概念。
通过直接优化的方式,最小化 LDM loss,就可以找到 v_*
优化目标:

保持 \epsilon_{\theta} ,c_{\theta} 不变,重新训练LDM,来找到 V_*
小结:
通过几张图片输入到网络中,依据LDM loss,固定某些参数不变,来找到最合适的 V_*
参考资料:
Textual Inversion · AUTOMATIC1111/stable-diffusion-webui Wiki · GitHub
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









