







原文地址:http://www.ibm.com/developerworks/cn/xml/x-xslt/
级别: 初级
Michael H. Kay (mhkay@iclway.co.uk)
2001 年 2 月 01 日
XSLT是什么类型的语言,其用途是什么,为什么要这样设计它?这些问题可以有许多不同的答案,初学者往往会感到困惑,因为这种语言与他们以前习惯使用的语言之间有很大差别。本文尝试说明XSLT。本文并不试图教您编写 XSLT样式表,它将说明这种语言的起源,它擅长什么,以及您为什么应该使用它。
我撰写本文的初衷是为一篇关于 Saxon 的技术文章提供必要的背景知识,打算提供在传统 XSLT 处理器中使用的实现技巧内幕,从而帮助用户使其样式表的性能达到最大化。但 developerWorks 的编辑们劝说我:这篇介绍应该吸引更广泛的读者,值得作为 XSLT 语言的独立说明而单独发表。
---------------------------------------------------
什么是 XSLT?
XSLT 语言由万维网联盟 (W3C) 定义,并且该语言的 1.0 版本在 1999 年 11 月 16 日作为“推荐书”发布(请参阅 参考资料)。我已经在拙作 XSLT Programmers' Reference 中提供了全面的规范和用户指南,因此我不打算在本文中涵盖相同内容。确切地讲,本文的目的只是使读者理解 XSLT 适合大规模事物的哪些位置。
---------------------------------------------------
XSLT 的角色
XSLT 的最初目的是将信息内容与 Web 显示分离。如其最初定义那样,HTML 通过按抽象概念(如段落、重点和编号列表)定义显示来实现设备独立性。随着 Web 变得越来越商业化,出版人希望其输出质量能达到与印刷品相同的质量。这逐渐导致越来越多地使用具体显示控件,如页面上材料的明确字体和绝对位置。然而不幸的是完全可以预料其副作用,即将相同的内容传递到替代设备,如数字电视机和 WAP 电话(印刷业的行话 再现效果)将会变得日益困难。
由于吸收了印刷业使用 SGML 的经验,在 1998 年初定义了一种标记语言 XML,它用于表示独立于显示的结构化内容。与 HTML 使用一组固定概念(如段落、列表和表)不同,XML 标记中使用的标记完全是用户定义的,其用意是这些标记应该与所关注的对象(如人、地点、价格和日期)相关。尽管 HTML 中的元素本质上都是印刷样式(虽然处于抽象级别),而 XML 的目标是元素应该描述实际对象。例如,清单 1 显示了表示足球锦标赛结果的 XML 文档。
清单 1. 表示足球锦标赛结果的 XML 文档
 <
results
group
="A"
>
<
match
>
<
date
>
10-Jun-1998
</
date
>
<
team
score
="2"
>
Brazil
</
team
>
<
team
score
="1"
>
Scotland
</
team
>
</
match
>
<
match
>
<
date
>
10-Jun-1998
</
date
>
<
team
score
="2"
>
Morocco
</
team
>
<
team
score
="2"
>
Norway
</
team
>
</
match
>
<
match
>
<
date
>
16-Jun-1998
</
date
>
<
team
score
="1"
>
Scotland
</
team
>
<
team
score
="1"
>
Norway
</
team
>
</
match
>
<
match
>
<
date
>
16-Jun-1998
</
date
>
<
team
score
="3"
>
Brazil
</
team
>
<
team
score
="0"
>
Morocco
</
team
>
</
match
>
<
match
>
<
date
>
23-Jun-1998
</
date
>
<
team
score
="1"
>
Brazil
</
team
>
<
team
score
="2"
>
Norway
</
team
>
</
match
>
<
match
>
<
date
>
23-Jun-1998
</
date
>
<
team
score
="0"
>
Scotland
</
team
>
<
team
score
="3"
>
Morocco
</
team
>
</
match
>
</
results
>
<
results
group
="A"
>
<
match
>
<
date
>
10-Jun-1998
</
date
>
<
team
score
="2"
>
Brazil
</
team
>
<
team
score
="1"
>
Scotland
</
team
>
</
match
>
<
match
>
<
date
>
10-Jun-1998
</
date
>
<
team
score
="2"
>
Morocco
</
team
>
<
team
score
="2"
>
Norway
</
team
>
</
match
>
<
match
>
<
date
>
16-Jun-1998
</
date
>
<
team
score
="1"
>
Scotland
</
team
>
<
team
score
="1"
>
Norway
</
team
>
</
match
>
<
match
>
<
date
>
16-Jun-1998
</
date
>
<
team
score
="3"
>
Brazil
</
team
>
<
team
score
="0"
>
Morocco
</
team
>
</
match
>
<
match
>
<
date
>
23-Jun-1998
</
date
>
<
team
score
="1"
>
Brazil
</
team
>
<
team
score
="2"
>
Norway
</
team
>
</
match
>
<
match
>
<
date
>
23-Jun-1998
</
date
>
<
team
score
="0"
>
Scotland
</
team
>
<
team
score
="3"
>
Morocco
</
team
>
</
match
>
</
results
>
如果要通过 Web 浏览器显示这些足球赛的结果,不要指望系统会产生合理的布局。需要其它一些机制来告诉系统如何在浏览器屏幕、电视机、WAP 电话或真正在纸张上显示数据。这就是使用样式表的目的。样式表是一组说明性的规则,它定义了应如何表示源文档中标记标识的信息元素。
W3C 已经定义了两个系列的样式表标准。第一个是在 HTML 中广泛使用的 CSS(级联样式表),当然它也可以在 XML 中使用。例如,可以使用 CSS 来表示何时显示发票,应支付的总额应该用 16 点 Helvetica 粗体字显示。但是,CSS 不能执行计算、重新整理或排序数据、组合多个源码中的数据或根据用户或会话的特征个性化显示的内容。在这个足球赛结果的例子中,CSS 语言(即使是最新版本 CSS2,尚未在产品中完全实现)的功能还不够强大,不能处理这项任务。由于这些原因,W3C 已着手开发更强大的样式表语言 XSL(可扩展样式表语言),并采纳了 SGML 社区中开发的 DSSSL(文档样式、语义和规范语言)中许多好的构思。
在 XSL 的开发过程中(这在 DSSSL 中已有所预示),发现在准备 XML 文档以备显示的过程中执行的任务可以分成两个阶段:转换和格式化。转换是将一个 XML 文档(或其内存中的表示法)转换成另一个 XML 文档的过程。格式是将已转换的树状结构转换成两维图形表示法或可能是一维音频流的过程。XSLT 是为控制第一阶段“转换”而开发的语言。第二阶段“格式化”的开发工作还是进行中。但实际上,大多数人现在使用 XSL 将 XML 文档转换成 HTML,并使用 HTML 浏览器作为格式化引擎。这是可行的,因为 HTML 实际上只是 XML 词汇表的一个示例,而 XSLT 可以使用任何 XML 词汇表作为其目标。
将转换成一种语言和格式化成另一种语言这两个操作分离经证实的确是一种好的决策,因为转换语言的许多应用程序经证明无法向用户显示文档。随着 XML 日益广泛地用作电子商务中的数据互换语法,对于应用程序将数据从一个 XML 词汇表转换成另一个 XML 词汇表的需求也在不断增加。例如,某个应用程序可能从电视收视指南中抽取电视节目的细节,并将它们插入按次付费客户的月帐单中。同样,还有许多实用的数据转换,在这些转换中源词汇表和目标词汇表是相同的。它们包括数据过滤,以及商务操作,如施行涨价。因此,随着在系统中开始越来越多地以 XML 语法的形式使用数据,XSLT 就逐渐成为由于处理这些数据的随处可见的高级语言。
在拙作中,我做了这样一个比喻:XSLT 与 XML 的关系,就好象 SQL 与表格化数据的关系一样。关系模型的强大功能并非来自用表存储数据的思想,而是源于 SQL 中可行的基于关系运算的高级数据操作。同样,XML 的层次化数据模型对应用程序开发者的帮助实际上也非常小。正是因为 XSLT 作为 XML 数据的高级操作语言提供了如此强大的功能。
---------------------------------------------------
XSLT 作为语言
就某些方面而言,XSLT 作为一种语言来说是非常古怪的。我不打算在本文中讨论已做出的设计决策的基本原理,尽管可以通过它们在逻辑上追溯到语言设计者确定的对 XSLT 的要求。如需更完整的说明,请参阅拙作的第 1 章。
以下概述了 XSLT 语言的部分主要特性。
XSLT 样式表是一个 XML 文档 。通过使用 XML 的尖括号标记语法来表示文档的结构。这种语法在某种程度上是比较笨拙的,而此决策可以使该语言变得更罗嗦。但是,它确实有好处。它表示可以自动使用 XML 的所有词汇设备(例如,Unicode 字符编码和转义,使用外部实体等等)。它表示很容易使 XSLT 样式表变成转换的输入或输出,使该语言可以作用于自身。它还使将期望的 XML 输出块嵌入样式表变得很容易。实际上,许多简单的样式表基本上可以写作期望输出文档的模板,并且可以将一些特殊指令嵌入文本中,以便插入输入中的变量数据或计算某个值。这就使 XSLT 在这个简单的级别上非常类似于许多现有的专用 HTML 模板语言。
基本处理范例是模式匹配。 在这方面,XSLT 继承了文本处理语言(如 Perl)的传统,这种传统可以一直追溯到 1960 年代的语言,如 SNOBOL。XSLT 样式表包括一组模板规则,每条规则都使用以下方式:“如果在输入中遇到此条件,则生成下列输出。”规则的顺序是无关紧要的,当有几条规则匹配同一个输入时,将应用冲突解决算法。然而,XSLT 与串行文本处理语言的不同之处是 XSLT 对输入并非逐行进行处理。实际上,XSLT 将输入 XML 文档视为树状结构,每条模板规则都适用于树中的一个节点。模板规则本身可以决定下一步处理哪些节点,因此不必按输入文档的原始顺序来扫描输入。
---------------------------------------------------
XSLT 处理器的操作
XSLT 处理器使用树状结构作为其输入,并生成另一个树状结构作为输出。图 1 中显示了这一点。
图 1. XSLT 输入和输出的树状结构 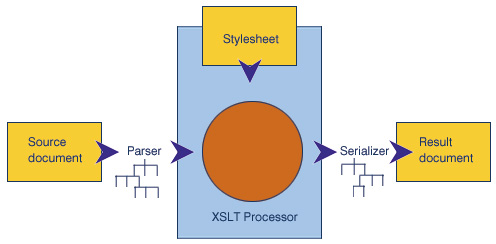
常常通过对 XML 文档进行语法分析来生成输入树状结构,而输出树状结构通常被串行化到另一个 XML 文档中。但 XSLT 处理器本身操作的是树状结构,而不是 XML 字符流。这个概念最初给许多用户的感觉是不切实际的,结果却对理解如何执行更复杂的转换起了关键作用。首先,它表示 XSLT 处理器可以理解源文档中与树状结构无关的特殊之处。例如,无论属性是包括在单引号中还是在双引号中,都不可能应用不同的处理,因为会将这两种形式视为同一个基本文档的不同表示方法。更深入地看,它表示处理输入元素或生成输出元素是一个原子操作。不可能将处理元素的开始标记和结束标记分成单独的操作,因为一个元素会自动表示成树模型的单节点。
XSLT 使用叫作 XPath 的子语言来引用输入树中的节点。XPath 本质上是与具有层次结构的 XML 数据模型相匹配的查询语言。它可以通过按任何方向浏览树来选择节点,并根据节点的值和位置应用谓词。它还包括用于基本字符串处理、数字计算和布尔代数的工具。例如,XPath 表达式 ../@title 选择当前节点的父代元素的标题属性。XPath 表达式用于选择要进行处理的输入节点、在条件处理期间测试条件,以及计算值以便插入结果树中。模板规则中还使用了 XPath 表达式的简化形式“模式”来定义特定模板规则适用于哪些节点。XPath 在单独的 W3C 推荐书中定义,它允许使用在其它上下文中再使用的查询语言,特别是用于定义扩展超链接的 XPointer。
XSLT 以传统语言(如 Lisp、Haskell 和 Scheme)中的功能性编程的概念为基础。样式表由模板组成,这些模板基本上是单一功能 -- 每个模板将输出树的一部分定义成一部分输入树的功能,并且不产生副作用。使用无副作用的规则受到严格控制(除了转义成用类似 Java 的语言编写的外部代码)。XSLT 语言允许定义变量,但不允许现有变量更改它的值 -- 即没有赋值语句。这个策略使许多新用户感到困惑,其目的是为了允许逐步应用样式表。其原理是如果语言没有副作用,那么对输入文档做很小的改动时,不必从头执行整个转换就应该可以计算出对输出文档的最后更改。目前必须说这只是理论上的可能,任何现有 XSLT 处理器还不能实现。(注:虽然 XSLT 以功能性编程概念为基础,但它还不是一个完整的功能性编程语言,因为它缺少将函数当作一级数据类型进行处理的能力。)
---------------------------------------------------
示例样式表
在这个阶段,使用示例会使语言变得更清楚。清单 2 显示了列出足球赛结果的简单样式表。
清单 2. 足球赛结果的基本样式表
<
xsl:transform
xmlns:xsl
="http://www.w3.org/1999/XSL/Transform"
version
="1.0"
>
<
xsl:template
match
="results"
>
<
html
>
<
head
>
<
title
>
Results of Group
<
xsl:value-of
select
="@group"
>
</
title
>
</
head
>
<
body
>
<
h1
>
Results of Group
<
xsl:value-of
select
="@group"
>
</
h1
>
<
xsl:apply-templates
>
</
body
>
</
html
>
</
xsl:template
>
<
xsl:template
match
="match"
>
<
h2
>
<
xsl:value-of
select
="team[1]"
>
versus
<
xsl:value-of
select
="team[2]"
>
</
h2
>
<
p
>
Played on
<
xsl:value-of
select
="date"
></
p
>
<
p
>
Result:
<
xsl:value-of
select
="team[1] "
>
<
xsl:value-of
select
="team[1]/@score"
>
,
<
xsl:value-of
select
="team[2] "
>
<
xsl:value-of
select
="team[2]/@score"
>
</
p
>
</
xsl:template
>
</
xsl:transform
>
这个样式表包括两个模板规则,一个匹配 <results> 元素,另一个匹配 <match> 元素。 <results> 元素的模板规则输出页面的标题,然后调用 <xsl:apply-templates> ,这是一个 XSLT 指令,它将处理当前元素的所有子代,对于每个子代都使用其适当的模板规则。在本例中, <results> 元素的所有子代都是 <match> 元素,所以会用第二个模板规则来处理它们。规则输出了一个标识比赛的次级 HTML 标题(以 "Brazil versus Scotland" 的形式),然后生成 HTML 段落,给出了比赛的日期和两队的比分。
该转换的结果就是一个 HTML 文档,该文档在浏览器中的表示如图 2 所示。
清单 2. 足球赛结果的基本样式表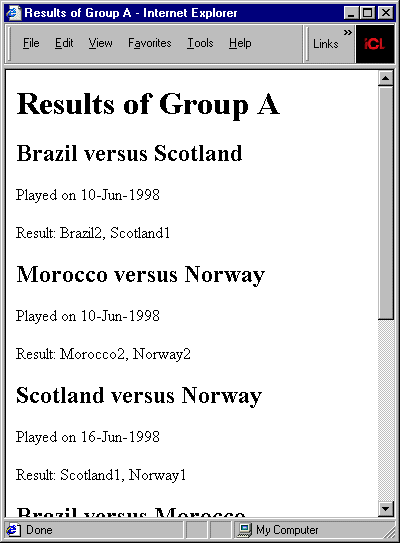
这是一种非常简单的表示信息的方法。然而,XSLT 的功能比这要强大得多。清单 3 包含了另一个可以操作相同源数据的样式表。这次,样式表计算一个比赛名次表,用来显示锦标赛结束时各队的名次。
清单3. 计算球队名次表的样式表
<
xsl:transform
xmlns:xsl
="http://www.w3.org/1999/XSL/Transform"
version
="1.0"
>
<
xsl:variable
name
="teams"
select
="//team[not(.=preceding::team)]"
>
<
xsl:variable
name
="matches"
select
="//match"
>
<
xsl:template
match
="results"
>
<
html
><
body
>
<
h1
>
Results of Group
<
xsl:value-of
select
="@group"
></
h1
>
<
table
cellpadding
="5"
>
<
tr
>
<
td
>
Team
</
td
>
<
td
>
Played
</
td
>
<
td
>
Won
</
td
>
<
td
>
Drawn
</
td
>
<
td
>
Lost
</
td
>
<
td
>
For
</
td
>
<
td
>
Against
</
td
>
</
tr
>
<
xsl:for-each
select
="$teams"
>
<
xsl:variable
name
="this"
select
="."
>
<
xsl:variable
name
="played"
select
="count($matches[team=$this])"
>
<
xsl:variable
name
="won"
select
="count($matches[team[.=$this]/@score > team[.!=$this]/@score])"
>
<
xsl:variable
name
="lost"
select
="count($matches[team[.=$this]/@score < team[.!=$this]/@score])"
>
<
xsl:variable
name
="drawn"
select
="count($matches[team[.=$this]/@score = team[.!=$this]/@score])"
>
<
xsl:variable
name
="for"
select
="sum($matches/team[.=current()]/@score)"
>
<
xsl:variable
name
="against"
select
="sum($matches[team=current()]/team/@score) - $for"
>
<
tr
>
<
td
><
xsl:value-of
select
="."
></
td
>
<
td
><
xsl:value-of
select
="$played"
></
td
>
<
td
><
xsl:value-of
select
="$won"
></
td
>
<
td
><
xsl:value-of
select
="$drawn"
></
td
>
<
td
><
xsl:value-of
select
="$lost"
></
td
>
<
td
><
xsl:value-of
select
="$for"
></
td
>
<
td
><
xsl:value-of
select
="$against"
></
td
>
</
tr
>
</
xsl:for-each
>
</
table
>
</
body
></
html
>
</
xsl:template
>
</
xsl:transform
>
这里没有足够的篇幅来完整地说明这个样式表,简而言之,它为球队声明了一个变量,变量值是一个节点集合,其中每个参赛球队都有一个实例。然后它计算每支球队的胜、平或负的比赛场次总数,以及球队进球或失球的总数。图 3 显示了它在浏览器中的最终输出结果。
图 3. 清单 3 中名次样式表的结果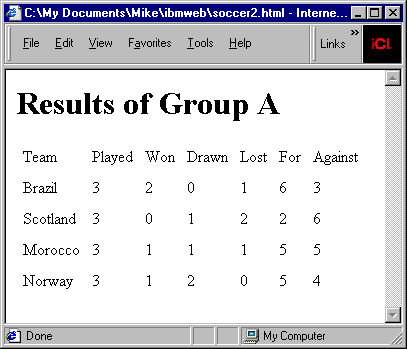
这个示例的目的是说明 XSLT 不单单能够对源文档中出现的文本指定字体和布局。它是一个完整的编程语言,能够以任何方式转换源数据以供显示,或者输入另一个应用程序。
---------------------------------------------------
XSLT 的优点
您为什么考虑使用 XSLT?
XSLT 给了您传统高级声明编程语言的所有好处,特别是对于转换 XML 文档的任务。
高级语言带来的实际好处是开发生产力。但实际上,真正的价值源自于 更改的潜力 。与使用低级 DOM 和 SAX 接口编码的过程性应用程序相比,用于转换 XML 数据结构的 XSLT 应用程序更能适应对 XML 文档细节的更改。在数据库世界中,这种特性叫做 数据独立性 ,正是由于数据独立性导致了诸如 SQL 之类声明性语言的成功,并使旧的引导性数据访问语言走向衰亡。我坚信在 XML 世界中也会这样。
当然与所有声明性语言一样,XSLT 也会降低性能。但是对于大多数应用程序,今天的 XSLT 处理器的性能已经完全能够满足应用程序的需要,并且它会变得越来越好。在我的第二篇文章中,我将讨论 XSLT 处理器中使用的一些优化技巧,如我自己的 Saxon 产品。
---------------------------------------------------
结束语
我想要在本文中展示的是 XSLT 是一种用于操作 XML 文档的完整高级语言,就如同 SQL 是操作关系表的高级语言一样。应该注意到 XSLT 不仅是一种样式设计语言,它比 CSS(或者甚至 CSS2)的功能更强大。
我见到过一些应用程序,它们的所有商务逻辑都用 XSLT 编码。在一个三层在线银行系统中,我看到:
- 从后端操作系统以 XML 消息的形式检索所有数据。
- 在联机会话的持续时间内,用户的帐户数据在内存中以 XML DOM 形式表示。
- 所有给用户的信息首先封装成 XML 消息,然后用服务器或客户机附带的 XSLT 转换根据浏览器的性能将这些消息转换成 HTML。
该应用程序的数据都是 XML 格式的,并且逻辑(包括数据访问逻辑、商务逻辑和显示逻辑)都由 XSLT 来实现。我建议每个项目都采用那种体系结构,但这还需要很长时间,我认为我们会在几年之内见到那种系统。
作为一种编程语言,XSLT 有许多特性 -- 从它使用 XML 语法到其功能性编程原理的基础 -- 还不为一般 Web 程序员所熟悉。那意味着一条陡峭的学习曲线和通常遇到许多挫折。当初对于 SQL 也是如此,所有这些表示 XSLT 与以前的编程语言有着本质的区别。但不要放弃:它是功能非常强大的技术,值得努力学习。
参考资料
- 您可以参阅本文在 developerWorks 全球站点上的 英文原文.
- 同一个作者撰写的 Wrox 书籍 XSLT Programmer's Reference。XSLT 语言的综合指南。
- W3C 出版的 XSLT 1.0 Recommendation。XSLT 语言的权威性规范。
- W3C 出版的 XPath 1.0 Recommendation 。XSLT 样式表中使用的 XPath 表达式语法的权威性规范。
- XSL-List ,一个有关 XSLT 所有事物的繁忙邮件列表,它附带有可搜索档案,由 MulberryTech 进行管理。
- www.xslinfo.com ,一个很好的网络中央页面,带有到 XSLT 资源的链接,内容包括软件、书籍、教程和其它内容。
关于作者
作为 Saxon XSLT 处理器和 Wrox 书籍 XSLT Programmer's Reference 的作者,Michael Kay 在 XML 世界可谓大名鼎鼎。他的背景(以及很久以前的博士学位)是在数据库技术方面。从那时起,他设计了 Codasyl,这个关系型、面向对象和纯文本的数据库软件。















 1449
1449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









