







1.什么是决策树
决策树是一种基本的分类与回归方法,在分类问题中,表示基于特征对实例进行分类的过程。它可以认为是if-then规则的集合,也可以认为是定义在特征空间与类空间上的条件概率分布,其主要优点是模型具有可读性,分类速度快。学习时,利用训练数据,根据损失函数最小化的原则建立决策树模型。预测时,对新的数据利用决策树模型进行分类。决策树学习通常包括三个步骤:特征选择,决策树的生成和决策树的修剪。
2.特征选择
特征选择在于选取对训练数据具有分类能力的特征。这样可以提高决策树的学习效率。如果利用一个特征进行分类的结果与随机分类的结果没有很大的区别。则称这个特征是没有分类能力的。经验上扔掉这些特征对决策树学习的精度影响不大,通常特征选择的准则是信息增益或信息增益比。
3.信息增益
在信息论与概率统计中,熵是表示随机变量不确定性的度量,设X是一个取有限值的离散随机变量,其概率分布为
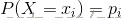
则随机变量X的熵定义为
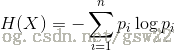
通常,式(1)中的对数以2为底或以e为底,这时熵的单位分别称为比特(bit)或纳特(nat)。由定义可知熵只依赖与X的分布,而与X的取值无关。
信息增益:特征A对训练数据集D的信息增益g(D,A),定义为集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(D|A)之差,即
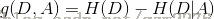
决策树学习应用信息增益准则选择特征。给定训练数据集D和特征A,经验熵H(D)表示对数据集D进行分类的不确定性,而经验条件熵H(D|A)表示在特征A给定的条件下对数据集D进行分类的不确定性。那么他们的差,即信息增益,就表示由于特征A给定的条件下对数据集D的分类的不确定性减少的程度。显然,对于数据集D而言,信息增益依赖于特征,不同的特征往往具有不同的信息增益,信息增益大的特征具有更强的分类能力。
4.决策树的生成
4.1 ID3算法
ID3算法的核心是在决策树各个节点上应用信息增益准则选择特征,递归的构建决策树。具体方法是:从根节点开始,对节点计算所有可能的特征的信息增益,选择信息增益最大的特征作为节点的特征,由该特征的不同取值建立子节点,再对子节点递归的调用以上的方法,构建决策树;直到所有特征的信息增益均很小或者没有特征可以选择为止
算法:
输入:训练数据集D,特征集A,阈值e;
输出:决策树T。
1.若D中所有实例属于同一类Ck,则T为单节点树,并将类Ck作为该节点的类标记,返回T;
2.若A=Φ,则T为单节点树,并将D中实例数最大的类Ck作为该节点的类标记,返回T;
3.否则,计算A中各特征对D的信息增益,选择信息增益大的特征Ag;
4.如果Ag的信息整增益小于阈值ε,则置T为单节点树,并将D中实例数量大的类Ck作为该节点的类标记,返回T;
5.否则,对Ag的每一可能值ai,依Ag=ai将D分割为若干非空子集Di,将Di中实例数最大的作为标记,构建子节点,由节点及其子节点构成树T返回T;
6.对第I个子节点,以Di为训练集,以A-{Ag}为特征集,递归的调用1~5步,得到子树Ti,返回Ti。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









