







分批次读取数据
数据模板:
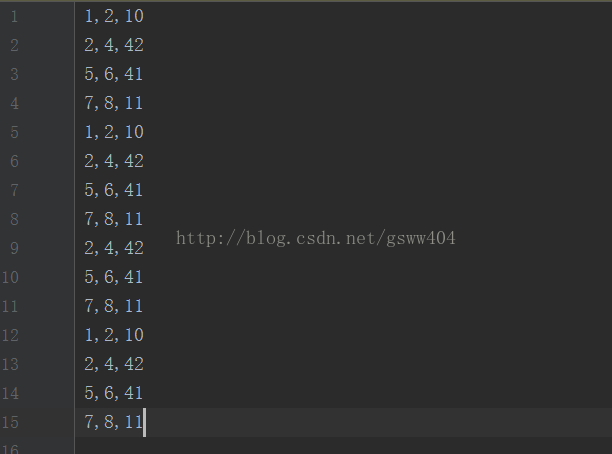
源代码
-------------------------------------------------
import tensorflow as tf
import numpy as np
def readMyFileFormat(fileNameQueue):
reader = tf.TextLineReader()
key, value = reader.read(fileNameQueue)
record_defaults = [[1.0], [1.0], [1.0]]
x1, x2, x3 = tf.decode_csv(value, record_defaults=record_defaults)
features = tf.stack([x1, x2])
label = x3
return features, label
def inputPipeLine(fileNames=["Test.csv"], batchSize = 4, numEpochs = None):
fileNameQueue = tf.train.string_input_producer(fileNames, num_epochs = numEpochs)
example, label = readMyFileFormat(fileNameQueue)
min_after_dequeue = 8
capacity = min_after_dequeue + 3 * batchSize
exampleBatch, labelBatch = tf.train.shuffle_batch([example, label], batch_size=batchSize, num_threads=3, capacity=capacity, min_after_dequeue=min_after_dequeue)
return exampleBatch, labelBatch
featureBatch, labelBatch = inputPipeLine(["Test.csv"], batchSize=4)
with tf.Session() as sess:
# Start populating the filename queue.
coord = tf.train.Coordinator()
threads = tf.train.start_queue_ru 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











