






从默认构造函数说起
如果没有为类编写构造函数,C++ 编译器会自动为其生成一个默认构造函数。
class A
{
private:
int n;
};
int main()
{
A i; // 编译器生成的默认构造函数
}如果为类编写了构造函数,C++ 编译器则不会自动为其生成默认构造函数。
class A
{
public:
A(int i) : n(i) {} // 自定义构造函数
private:
int n;
};
int main()
{
A i1; // 编译错误:不会自动生成默认构造函数
A i2(100); // 编程成功:调用自定义构造函数
}如果需要默认构造函数,需要手动加上。有两种方式可以:
class A
{
public:
// ...
A() {} // 定义一个空的默认构造函数
A() = default; // 主动让编译器生成默认构造函数
// ...
};那么,这两种方式有没有区别?= default 是 C++11 开始引入的语法。如果两者没有区别,又何必多此一举。所以,答案是肯定的,这两种方式是有区别的。那区别在哪里呢?
Trivial Type
C++ 中有概念叫 trivial type ,可以简单翻译成“普通(平凡)类型”。
当一个类型(class / struct )同时满足以下几个条件时,它就是 trivial type:
没有虚函数或虚基类。
由编译器生成默认的特殊成员函数,包括默认构造函数、拷贝构造函数、移动构造函数、赋值运算符、移动赋值运算符和析构函数。
数据成员同样需要满足条件 1 和 2。
所以,上面的例子中,如果使用了 A() {} 则 class A 是 non-trivial type;如果使用的是 A() = default; 则 class A 是 trivial type 。
#include <type_traits>
class A
{
public:
A(int i) : n(i) {}
A() {}
private:
int n;
};
class B
{
public:
B(int i) : n(i) {}
B() = default;
private:
int n;
};
static_assert(!std::is_trivial<A>::value);
static_assert(std::is_trivial<B>::value);Standard Layout
当类(class 或 struct )同时满足以下几个条件时是标准布局(standard-layout)类型:
没有虚函数或虚基类。
所有非静态数据成员都具有相同的访问说明符(
public/protected/private)。在继承体系中最多只有一个类中有非静态数据成员。
子类中的第一个非静态成员的类型与其基类不同。
前 3 个条件都很好理解。第 4 条起来就有点不好理解了,来看一个例子。
struct A
{};
struct B : A
{
A a;
int i;
};
struct C : A
{
int i;
A a;
};
static_assert(!std::is_standard_layout<B>::value);
static_assert(std::is_standard_layout<C>::value);struct B 和 struct C 都满足前 3 个条件。
struct B 不满足第 4 个条件,所以它不是 standard layout。
struct C 满足第 4 个条件,所以它是 standard layout。
第 4 个条件的产生是因为 C++ 允许优化不包含成员基类:
在 C++ 标准中,如果基类没有任何数据成员,基类应不占用空间。所以,C++ 标准允许派生类的第一个成员与基类共享同一地址空间。
但是,如果派生类的第一个非静态成员的类型和基类相同,由于 C++ 标准要求相同类型的不同对象的地址必须不同,编译器就会为基类分派一个字节的地址空间。
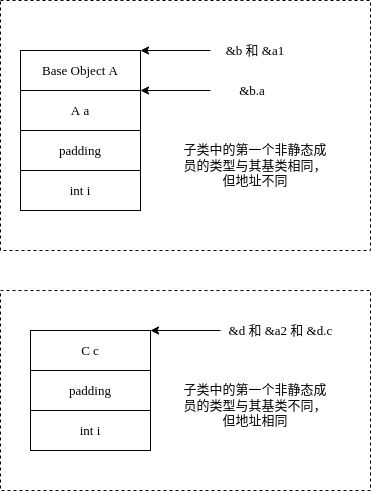
#include <iostream>
struct A
{};
struct B : A
{
A a;
int i;
};
struct C
{};
struct D : A
{
C c;
int i;
};
int main()
{
B b;
A & a1 = b;
// &b == &a1 == &b.a - 1
std::cout << &b << std::endl;
std::cout << &a1 << std::endl;
std::cout << &b.a << std::endl;
D d;
A & a2 = d;
// &d == &a2 == &d.c
std::cout << &d << std::endl;
std::cout << &a2 << std::endl;
std::cout << &d.c << std::endl;
}画个图简单理解一下;
Plain Old Data
Plain Old Data 简称 POD,是从 C++11 开始引入的概念。Plain 代表一个对象是一个普通类型;Old 代表一个对象可以与 C 语言兼容。
POD 类型的一个重要特点就是与 C 语言兼容:
可以使用字节赋值,比如用
memset、memcpy对 POD 类型对象进行赋值操作。与 C 语言内存布局兼容,POD 类型的数据可以使用 C 函数进行操作且是安全的。
保证了静态初始化的安全有效。
C++ 提供了 std::is_pod<T> 来判断一个类型是不是 POD 类型。
不过,从 C++20 开始,POD 这个概念被开始淡化,std::is_pod<T> 这个模板库也被废弃,转而用 trivial 和 standard-layout 两个概念代替。
所以,如果一个对象既是 trivial 又是 standard-layout,那么这个对象就是 POD 类型。
std::is_pod<T> == std::is_trivial<T> && std::is_standard_layout<T>














 4180
4180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









