







海量数据挖掘Mining Massive Datasets(MMDs) -Jure Leskovec courses学习笔记之社交网络之社区检测:基本技巧-生成模型及其参数的梯度上升方法求解
博客内容:社区检测的基本技巧部分,覆盖"overlapping communities"寻找最好集合的机器学习技术。
Communities in Social Networks: 直觉上, 社区communities就是网络中个体的集合,集合中通常有高密度的边。而overlapping communities就是人们通常属于多个社区,如高中朋友、同事等等。
Note: lz这里这种方法是要自己指定社区个数的,有点类似软分类,通过MLE求解。
How the class fits together
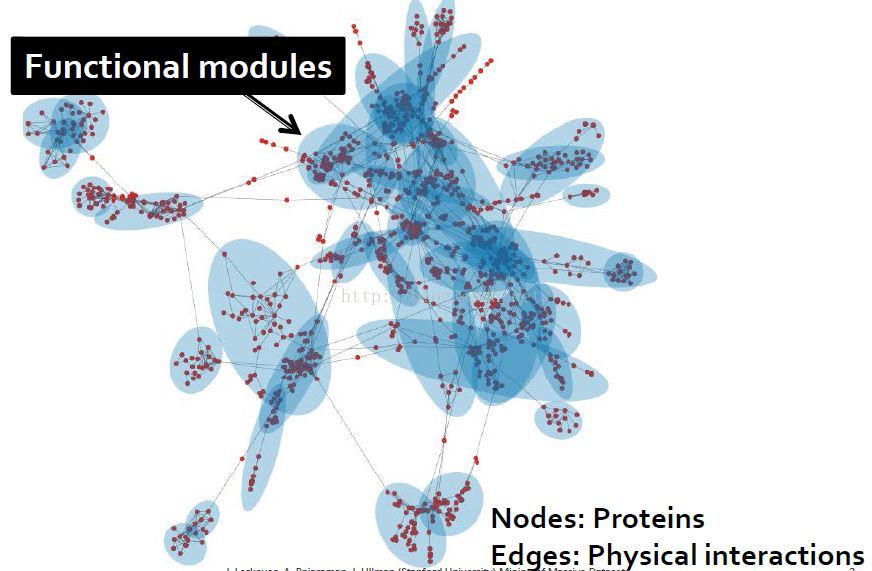
图中社区检测
通过蛋白质连接结构发现细胞中的功能模块 社交网络(facebook)中的社区发现
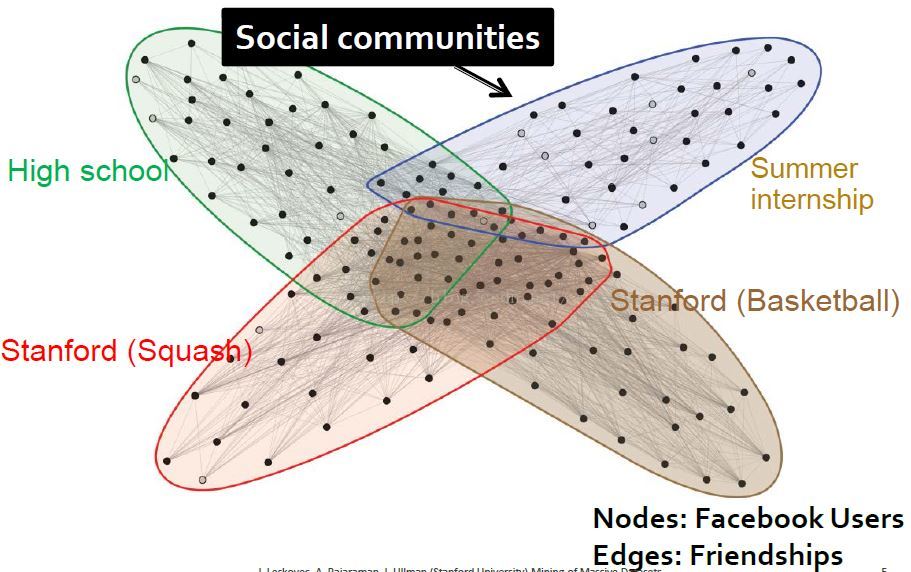
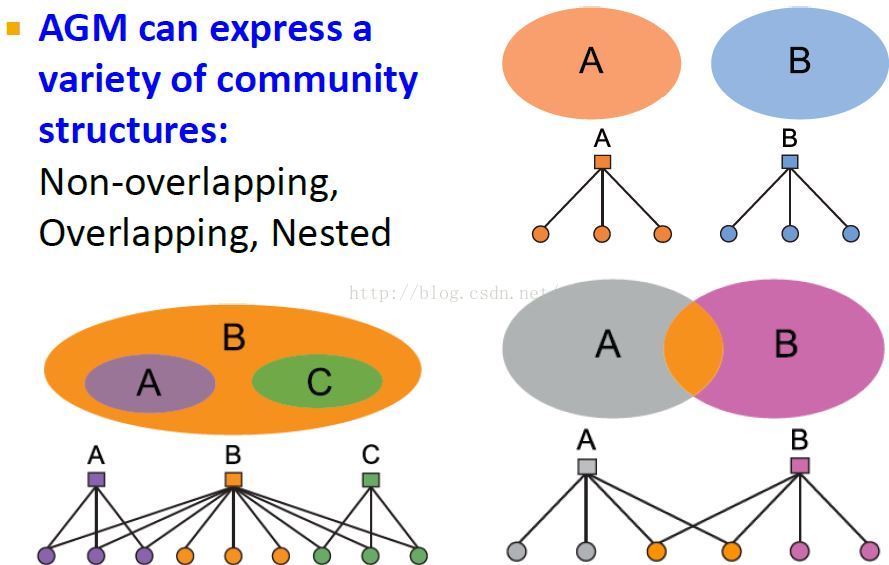
社区类型
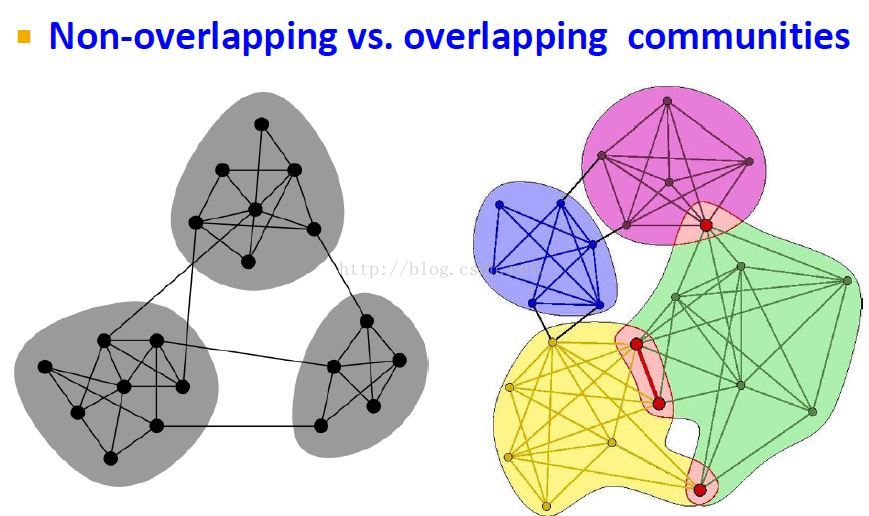
社区表示
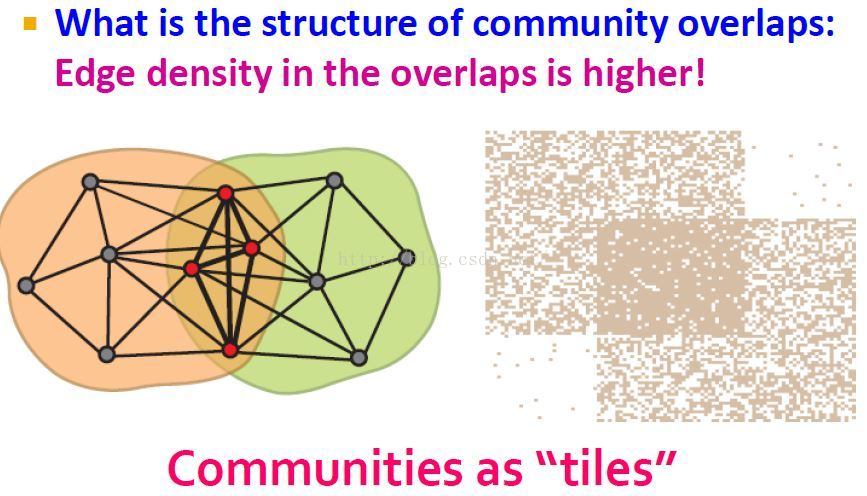
我们可以将社交网络表示成一个graph adjacency matrix:有联系就有值,没有联系就没有值。矩阵中the thicker the tiles,the more edges are there in the network.我们要做的就是从networks中将这些tiles分离开来。
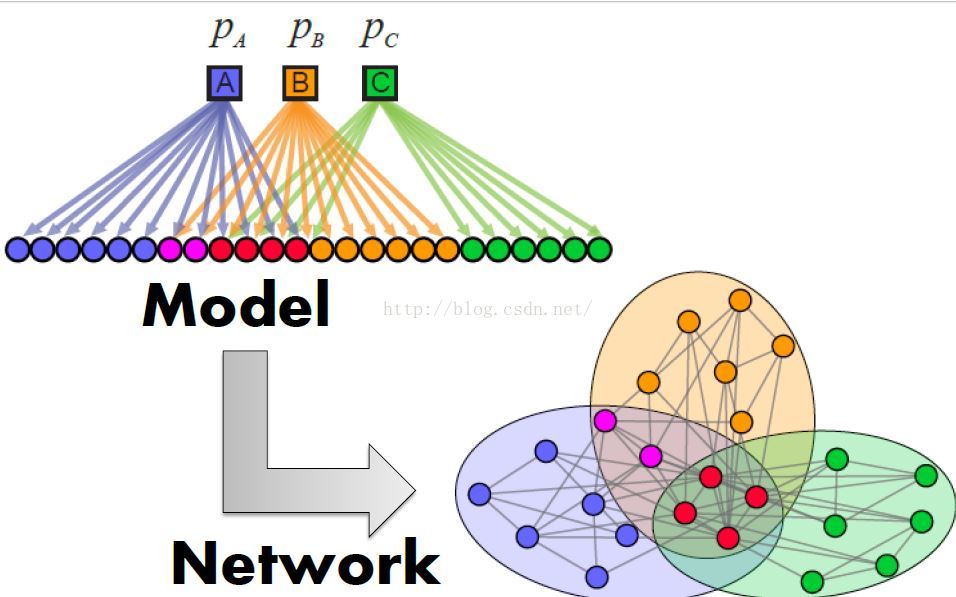
网络生成模型Generative Model for Networks
网络模型
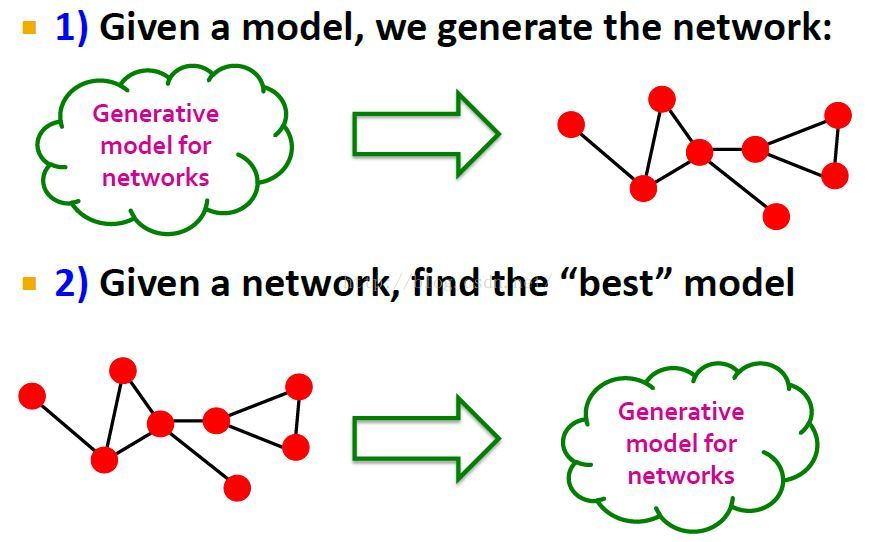
模型会有很多参数,通过估计这些参数,就可以隐含地检测出这些社区。
社区隶属关系图模型AGM(community-affiliation graph model)
模型表示 B(V, C, M, {Pc})
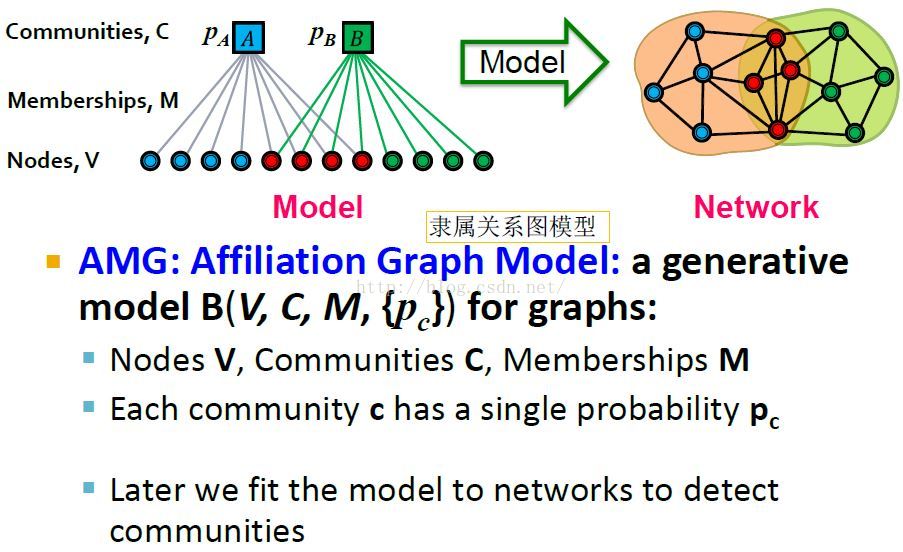
模型中的边M代表成员-社区隶属关系。
AGM模型假定指定社区中的每个成员V(圆点)属于其对应社区C(方块)的概率是一样的,即Pc。
AGM生成Networks边的过程
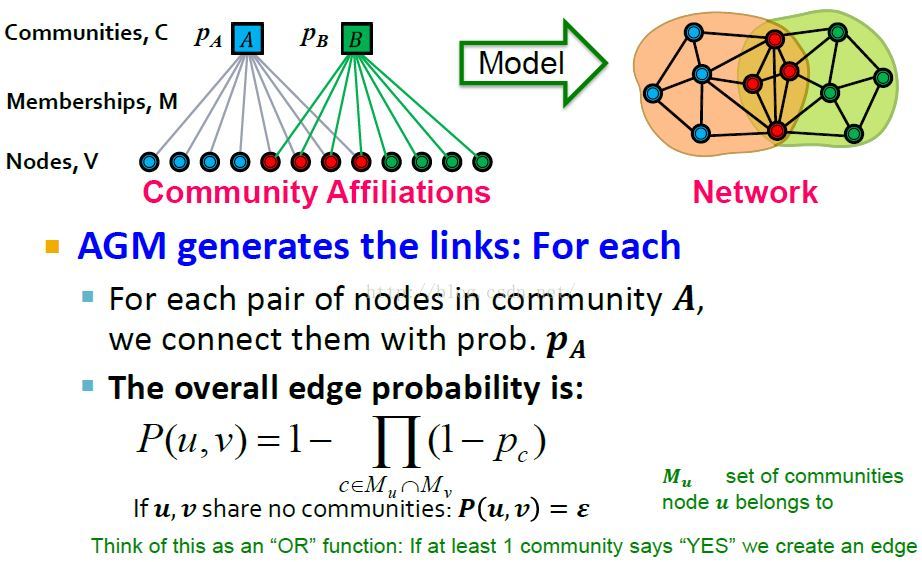
用户u,v在网络中有边的概率P(u,v)就是其至少同属于一个社区的概率,共同社区越多,其概率值越大,概率越大越可能生成边。
Note: AGM模型中假定个体属于社区是没有权重的,或者说权重都为1。
AGM模型的优势
BIGCLAM模型
{AGM的relaxed版本。简化AGM成BIGCLAM,可以在large networks中检测社区}
带权值Memberships的AGM模型
对原始AGM模型进行relax,即考虑边权,重新计算两个个体属于同一社区A的概率P C(u, v)。

1. 原来成员u属于社区A是01表示,现在表示成一个绳strands,值越高,说明这个个体在社区中越活跃。
2. 用户u,v同时属于某个社区如A的概率PA(u,v),直觉上,如果两个都与社区A强关联,则两者间的关系就越强。PA(u,v)计算公式的一个重要性质是,如果某个Fu=0,就是u完全不属于社区A,则u,v也是没关联的。
使用因子矩阵Factor Matrix F重新构造P(U, V)
矩阵F就是BIGCLAM模型的表示。
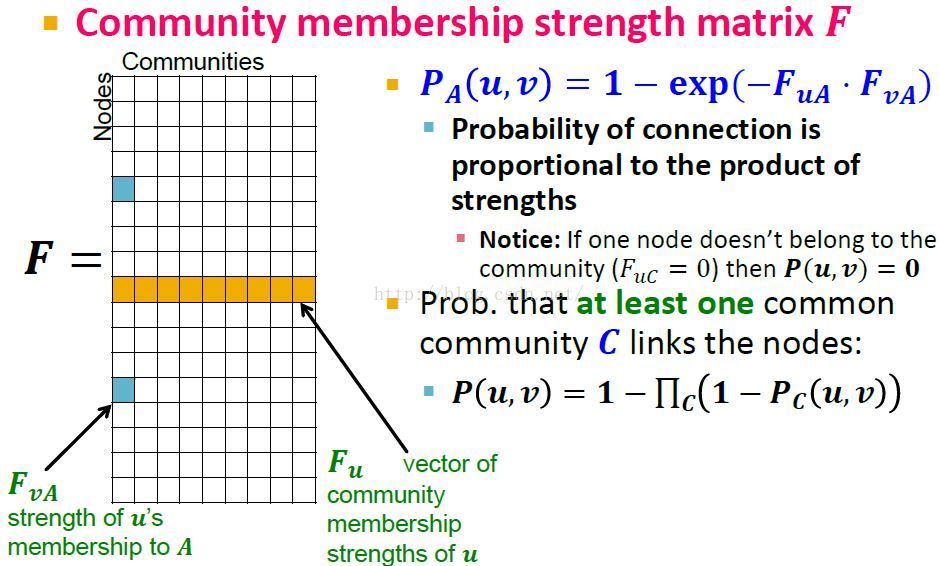
概率 P(u,v)的计算
两个个体u,v生成links的概率表示,即在网络中有边的概率或者是至少同时属于一个社区的概率 P(u,v)的计算:
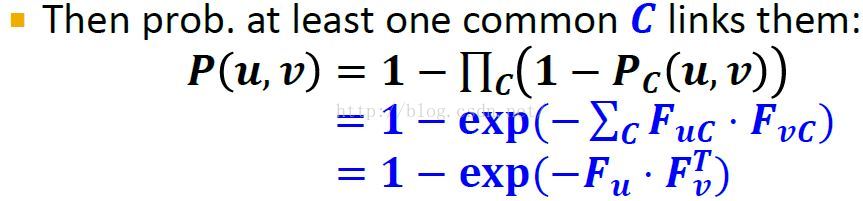
只要估计出矩阵F就可以计算出P(u,v),就可以通过P(u,v)概率生成图中的边。而矩阵F就给出了社区,完成社区检测。
Note: 如果F仅仅是0-1矩阵,则上式P(u, v)计算就是原始AGM模型了。
解BigCLAM
{给定一个网络G(V,E)我们知道节点和边,要找到这个模型BIGLAM的表示,也就是找到矩阵F}
最大似然估计:使用已知事实数据network G(V, E)估计F矩阵
为了使networks图中存在边的两点其属于同一社区的概率P(u, v)较大,同时不存在边的两点其属于同一社区的概率P(u, v)较小。我们要做的就是最大化下式。

BigCLAM解F版本一:梯度上升

1. 使用梯度方法的一个假设:认为函数some kind of convex, smooth shape.并且这里我们是要求最大值而不是最小值,所以会使用梯度上升而不是梯度下降。如果将p(u,v),1-p(u,v)互换应该就可以使用梯度下降了。
2. 这里求梯度是对给定的node进行的,对应F的一行向量Fu,对Fu求导应该等价于对Fu各分量分别求导再重组成向量。
3. 这个算法可能导致其中的strands FuC变成负值,每次迭代都要检测并修正。
算法的缺点
导致这个的原因:由于计算和式(梯度式中第二部分)要遍历给定节点的所有非邻节点,要遍历整个数据。
BigCLAM解F版本二:cache缓存加速
通过邻居neibor来迭代求解F矩阵。缓存F中所有行的向量行和,就是将F所有行加起来,通过下式的转换就不用每次遍历整个数据了,只需遍历一次缓存,每次遍历的只是邻居节点。

BigClam的伸缩性scalability
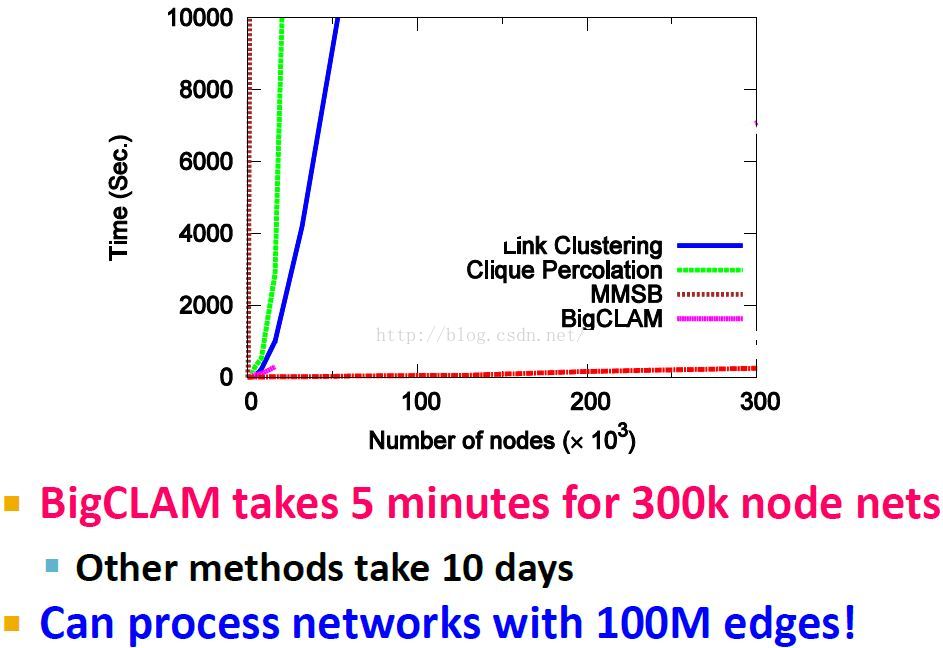
更多关于求解F的细节的论文
Overlapping Community Detection at Scale: A Nonnegative Matrix Factorization Approach by J. Yang, J. Leskovec. ACM International Conference on Web Search and Data Mining (WSDM), 2013.
Detecting Cohesive and 2-mode Communities in Directed and Undirected Networks by J. Yang, J. McAuley, J. Leskovec. ACM International Conference on Web Search and Data Mining (WSDM),2014.
Community Detection in Networks with Node Attributes by J. Yang,J. McAuley, J. Leskovec. IEEE International Conference On Data Mining (ICDM), 2013.
from:http://blog.csdn.net/pipisorry/article/details/49052057
ref: [Community Detection Algorithm Combining Stochastic Block Model and Attribute Data Clustering 2016]
《Community detection in networks: A user guide》S Fortunato, D Hric [ Indiana University & Aalto University School of Science] (2016)
论文:(社交)网络影响基准度量方法《Benchmarking Measures of Network Influence》A Bramson, B Vandermarliere (2016)















 4204
4204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









