






背景:近期项目需要,引入flink,研究了下flink,步步踩坑终于可以单独运行,也可发布到集群运行,记录下踩坑点。开发环境:idea+springboot(2.3.5.RELEASSE)+kafka(2.8.1)+mysql(8.0.26)。废话不多说,直接上可执行代码。
以下代码实现了某个时间间隔,设备不上传数据,判断为离线的逻辑
一、项目application创建
/**
* flink任务提交application
*
* @author wangfenglei
*/
@SpringBootApplication(scanBasePackages = {"com.wfl.firefighting.flink","com.wfl.firefighting.util"})
public class DataAnalysisFlinkApplication {
public static void main(String[] args) {
SpringApplication.run(DataAnalysisFlinkApplication.class, args);
}
}二、设备状态计算主体,从kafka接收数据,然后通过KeyedProcessFunction函数进行计算,然后把离线设备输出到mysql sink,更新设备状态
/**
* 从kafka读取数据,计算设备状态为离线后写入mysql
*
* @author wangfenglei
*/
@Component
@ConditionalOnProperty(name = "customer.flink.cal-device-status", havingValue = "true", matchIfMissing = false)
public class DeviceDataKafkaSource {
private static final Logger log = LoggerFactory.getLogger(CalDeviceOfflineFunction.class);
@Value("${spring.kafka.bootstrap-servers:localhost:9092}")
private String kafkaServer;
@Value("${spring.kafka.properties.sasl.jaas.config}")
private String loginConfig;
@Value("${customer.flink.cal-device-status-topic}")
private String topic;
@Autowired
private ApplicationContext applicationContext;
/**
* 执行方法
*
* @throws Exception 异常
*/
@PostConstruct
public void execute() throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(5000);
env.setParallelism(1);
Properties properties = new Properties();
//kafka的节点的IP或者hostName,多个使用逗号分隔
properties.setProperty("bootstrap.servers", kafkaServer);
//kafka的消费者的group.id
properties.setProperty("group.id", "data-nanlysis-flink-devicestatus");
//设置kafka安全认证机制为PLAIN
properties.setProperty("sasl.mechanism", "PLAIN");
//设置kafka安全认证协议为SASL_PLAINTEXT
properties.setProperty("security.protocol", "SASL_PLAINTEXT");
//设置kafka登录验证用户名和密码
properties.setProperty("sasl.jaas.config", loginConfig);
FlinkKafkaConsumer<String> myConsumer = new FlinkKafkaConsumer<>(topic, new SimpleStringSchema(), properties);
DataStream<String> stream = env.addSource(myConsumer);
stream.print().setParallelism(1);
DataStream<String> deviceStatus = stream
//进行转换只获取设备序列码
.map(data -> CommonConstant.GSON.fromJson(data, MsgData.class).getDevSn())
//按照设备序列码分组
.keyBy(new KeySelector<String, String>() {
@Override
public String getKey(String value) throws Exception {
return value;
}
})
//进行计算,判断周期内是否有新数据上传,没有则输出认为设备离线
.process((CalDeviceOfflineFunction) applicationContext.getBean("calDeviceOfflineFunction"));
//写入数据库
deviceStatus.addSink((SinkFunction) applicationContext.getBean("deviceStatusSink"));
//启动任务
new Thread(() -> {
try {
env.execute("deviceStatusFlinkJob");
} catch (Exception e) {
log.error(e.toString(), e);
}
}).start();
}
}说明:
1、通过@ConditionalOnProperty开关形式控制程序是否执行,后续此模块可以开发多个flink执行任务,通过开关的形式提交需要的job
2、通过springboot的@PostConstruct注解,让项目application启动时,自动执行job
3、用Thread线程执行任务提交,否则application启动时会一直flink执行中
4、日志打印,需要使用slf4j,跟flink自己依赖jar包打印日志保持一致,如此在flink集群执行时可以打印日志
import org.slf4j.Logger; import org.slf4j.LoggerFactory;
private static final Logger log = LoggerFactory.getLogger(CalDeviceOfflineFunction.class);
5、kafka连接开启了登录验证,配置见application.yml。kafka登录验证server端配置见官网资料,后续有时间写个文章记录下
三、设备离线计算
/**
* KeyedProcessFunction 为每个设备序列码维护一个state,并且会把间隔时间内(事件时间)内没有更新的设备序列码输出:
* 对于每条记录,CalDeviceOfflineFunction 修改最后的时间戳。
* 该函数还会在间隔时间内调用回调(事件时间)。
* 每次调用回调时,都会检查存储的最后修改时间与回调的事件时间时间戳,如果匹配则发送设备序列码(即在间隔时间内没有更新,表示没有设备数据上传)
*
* @author wangfenglei
*/
@Component
@ConditionalOnProperty(name = "customer.flink.cal-device-status", havingValue = "true", matchIfMissing = false)
public class CalDeviceOfflineFunction extends KeyedProcessFunction<String, String, String> {
private static final Logger log = LoggerFactory.getLogger(CalDeviceOfflineFunction.class);
/**
* 这个状态是通过 ProcessFunction维护
*/
private ValueState<DeviceLastDataTimestamp> deviceState;
/**
* 定时任务执行时间
*/
private ValueState<Long> timerState;
@Autowired
private DeviceService deviceService;
@Override
public void open(Configuration parameters) throws Exception {
deviceState = getRuntimeContext().getState(new ValueStateDescriptor<>("deviceState", DeviceLastDataTimestamp.class));
timerState = getRuntimeContext().getState(new ValueStateDescriptor<>("timerState", Long.class));
}
/**
* 每条数据执行过程
*
* @param value 输入数据
* @param ctx 环境
* @param out 输出数据
* @throws Exception 异常
*/
@Override
public void processElement(String value, Context ctx, Collector<String> out) throws Exception {
log.info("++++++++++++++fink recevice deviceSn={}", value);
// 查看当前计数
DeviceLastDataTimestamp current = deviceState.value();
if (current == null) {
current = new DeviceLastDataTimestamp();
current.key = value;
current.lastDataTime = ctx.timestamp();
}
Long currentTimerState = timerState.value();
if (null == currentTimerState) {
//初始值设置为-1
timerState.update(-1L);
}
if (-1 != timerState.value()) {
//删除原先定时任务,然后重新注册新的定时任务
ctx.timerService().deleteProcessingTimeTimer(timerState.value());
}
long interval = deviceService.getDeviceOfflineInterval(value);
// 设置状态的时间戳为记录的事件时间时间戳
current.lastDataTime = ctx.timestamp();
//设置判断离线时间间隔
current.interval = interval;
// 状态回写
deviceState.update(current);
//更新定时任务执行时间
timerState.update(current.lastDataTime + interval);
//注册新的定时任务
ctx.timerService().registerProcessingTimeTimer(current.lastDataTime + interval);
}
/**
* 定时器触发后执行的方法
*
* @param timestamp 这个时间戳代表的是该定时器的触发时间
* @param ctx 定时器环境类
* @param out 输出
* @throws Exception 异常
*/
@Override
public void onTimer(
long timestamp,
OnTimerContext ctx,
Collector<String> out) throws Exception {
// 取得该设备状态的State状态
DeviceLastDataTimestamp result = deviceState.value();
// timestamp是定时器触发时间,如果等于最后一次更新时间+离线间隔时间,就表示这十秒内没有收到过该设备报文了
if (timestamp == result.lastDataTime + result.interval) {
// 发送
out.collect(result.key);
// 打印数据,用于核对是否符合预期
log.info("==================" + result.key + " is offline");
}
}
/**
* 设备最后上传数据时间戳数据类
*/
class DeviceLastDataTimestamp {
public String key;
public long lastDataTime;
public long interval;
}
}四、 更新设备离线状态
/**
* 向mysql写入数据
*
* @author wangfenglei
*/
@Component
@ConditionalOnProperty(name = "customer.flink.cal-device-status", havingValue = "true", matchIfMissing = false)
public class DeviceStatusSink extends RichSinkFunction<String> {
private static final Logger log = LoggerFactory.getLogger(DeviceStatusSink.class);
@Value("${spring.datasource.dynamic.datasource.master.url}")
private String datasoureUrl;
@Value("${spring.datasource.dynamic.datasource.master.username}")
private String userName;
@Value("${spring.datasource.dynamic.datasource.master.password}")
private String password;
@Value("${spring.datasource.dynamic.datasource.master.driver-class-name}")
private String driverClass;
private Connection conn = null;
private PreparedStatement ps = null;
@Override
public void open(Configuration parameters) throws Exception {
//加载驱动,开启连接
try {
Class.forName(driverClass);
conn = DriverManager.getConnection(datasoureUrl, userName, password);
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public void invoke(String deviceSn, Context context) {
try {
String sql = "update biz_device t set t.status=2 where t.dev_sn=?";
ps = conn.prepareStatement(sql);
ps.setString(1, deviceSn);
ps.executeUpdate();
log.info("update biz_device t set t.status=2 where t.dev_sn={}", deviceSn);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 结束任务,关闭连接
*
* @throws Exception
*/
@Override
public void close() throws Exception {
if (conn != null) {
conn.close();
}
if (ps != null) {
ps.close();
}
}
}五、application.yml配置
server:
port: 8099
spring:
autoconfigure:
exclude: com.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceAutoConfigure
datasource:
druid:
stat-view-servlet:
enabled: true
loginUsername: admin
loginPassword: 123456
allow:
web-stat-filter:
enabled: true
dynamic:
druid: # 全局druid参数,绝大部分值和默认保持一致。(现已支持的参数如下,不清楚含义不要乱设置)
# 连接池的配置信息
# 初始化大小,最小,最大
initial-size: 5
min-idle: 5
maxActive: 20
# 配置获取连接等待超时的时间
maxWait: 60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
timeBetweenEvictionRunsMillis: 60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
minEvictableIdleTimeMillis: 300000
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
# 打开PSCache,并且指定每个连接上PSCache的大小
poolPreparedStatements: true
maxPoolPreparedStatementPerConnectionSize: 20
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
filters: stat,wall,slf4j
# 通过connectProperties属性来打开mergeSql功能;慢SQL记录
connectionProperties: druid.stat.mergeSql\=true;druid.stat.slowSqlMillis\=5000
datasource:
master:
url: jdbc:mysql://127.0.0.1:3306/fire?characterEncoding=UTF-8&useUnicode=true&useSSL=false&tinyInt1isBit=false&allowPublicKeyRetrieval=true&serverTimezone=Asia/Shanghai
username: root
password: root
driver-class-name: com.mysql.cj.jdbc.Driver
kafka:
bootstrap-servers: 127.0.0.1:9092 # 指定kafka 代理地址,可以多个
producer: # 生产者
retries: 1 # 设置大于0的值,则客户端会将发送失败的记录重新发送
# 每次批量发送消息的数量
batch-size: 16384
buffer-memory: 33554432
# 指定消息key和消息体的编解码方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
#修改最大向kafka推送消息大小
properties:
max.request.size: 52428800
consumer:
group-id: data-analysis-flink
#手动提交offset保证数据一定被消费
enable-auto-commit: false
#指定从最近地方开始消费(earliest)
auto-offset-reset: latest
#消费者组
#group-id: dev
properties:
#服务端没有收到心跳超时时间,设置长点以防调试时超时
session:
timeout:
ms: 60000
heartbeat:
interval:
ms: 30000
security:
protocol: SASL_PLAINTEXT
sasl:
mechanism: PLAIN
jaas:
config: 'org.apache.kafka.common.security.scram.ScramLoginModule required username="root" password="root";'
#自定义配置
customer:
#flink相关配置
flink:
#是否开启设置状态计算
cal-device-status: true
cal-device-status-topic: device-upload-data六、pom.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>com.wfl.firefighting</groupId>
<artifactId>data-analysis</artifactId>
<version>1.0.0</version>
</parent>
<groupId>com.wfl.firefighting</groupId>
<artifactId>data-analysis-flink</artifactId>
<version>1.0.0</version>
<packaging>jar</packaging>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-logging</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.wfl.firefighting</groupId>
<artifactId>data-analysis-service</artifactId>
<version>1.0.0</version>
</dependency>
<dependency>
<groupId>com.wfl.firefighting</groupId>
<artifactId>data-analysis-model</artifactId>
<version>1.0.0</version>
</dependency>
<dependency>
<groupId>io.github.openfeign</groupId>
<artifactId>feign-httpclient</artifactId>
<version>10.10.1</version>
</dependency>
<!-- druid -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.22</version>
</dependency>
<!-- 动态数据源 -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>dynamic-datasource-spring-boot-starter</artifactId>
<version>2.5.4</version>
</dependency>
<!--mysql-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.20</version>
</dependency>
<!-- flink依赖引入 开始-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.13.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.13.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.13.1</version>
</dependency>
<!-- flink连接kafka -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.13.1</version>
</dependency>
<!-- flink连接es-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>1.13.1</version>
</dependency>
<!-- flink连接mysql-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-jdbc_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<!-- flink依赖引入 结束-->
</dependencies>
<build>
<finalName>data-analysis-flink</finalName>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<createDependencyReducedPom>false</createDependencyReducedPom>
<artifactSet>
<excludes>
<exclude>com.google.code.findbugs:jsr305</exclude>
<exclude>org.slf4j:*</exclude>
<exclude>log4j:*</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>module-info.class</exclude>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer">
<resource>META-INF/spring.handlers</resource>
<resource>reference.conf</resource>
</transformer>
<transformer
implementation="org.springframework.boot.maven.PropertiesMergingResourceTransformer">
<resource>META-INF/spring.factories</resource>
</transformer>
<transformer
implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer">
<resource>META-INF/spring.schemas</resource>
</transformer>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer" />
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.wfl.firefighting.flink.DataAnalysisFlinkApplication</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>说明:
1、如果使用local执行方式,不需要提交到flink服务端执行job,可以使用spring-boot-maven-plugin,直接java -jar执行即可,如下:
<build>
<finalName>data-analysis-flink</finalName>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<!-- 指定启动入口 -->
<configuration>
<mainClass>com.wfl.firefighting.flink.DataAnalysisFlinkApplication</mainClass>
</configuration>
<executions>
<execution>
<goals>
<!--可以把依赖的包都打包到生成的Jar包中-->
<goal>repackage</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
使用spring-boot-maven-plugin打的jar包,提交到flink集群端执行,会报错,提示找不到类,因为springboot默认打包BOOT-INF目录,flink服务端执行会提示找不到类。使用maven-shade-plugin打包,既可以用java -jar执行,也可以提交到flink服务端执行。
2、maven-shade-plugin打的jar包,如果提交到服务端执行,需要去掉springboot默认集成的logback,否则服务端执行报错,提示Caused by: java.lang.IllegalArgumentException: LoggerFactory is not a Logback LoggerContext but Logback is on the classpath,如下:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-logging</artifactId>
</exclusion>
</exclusions>
</dependency>
如果本地执行java -jar形式,需要在build的中注释掉以下内容,否则启动报错提示:java.lang.NoClassDefFoundError: org/slf4j/LoggerFactory
<!--<exclude>org.slf4j:*</exclude>--> <!--<exclude>log4j:*</exclude>-->
3、使用maven-shade-plugin打包,必须添加如下,否则提示Cannot find 'resource' in class org.apache.maven.plugins.shade.resource.ManifestResourceTransformer
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer">
<resource>META-INF/spring.handlers</resource>
<resource>reference.conf</resource>
</transformer>
<transformer
implementation="org.springframework.boot.maven.PropertiesMergingResourceTransformer">
<resource>META-INF/spring.factories</resource>
</transformer>
<transformer
implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer">
<resource>META-INF/spring.schemas</resource>
</transformer>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer" />
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.wfl.firefighting.flink.DataAnalysisFlinkApplication</mainClass>
</transformer>
</transformers>
七、执行效果:
1、本地执行

2、提交到flink集群执行

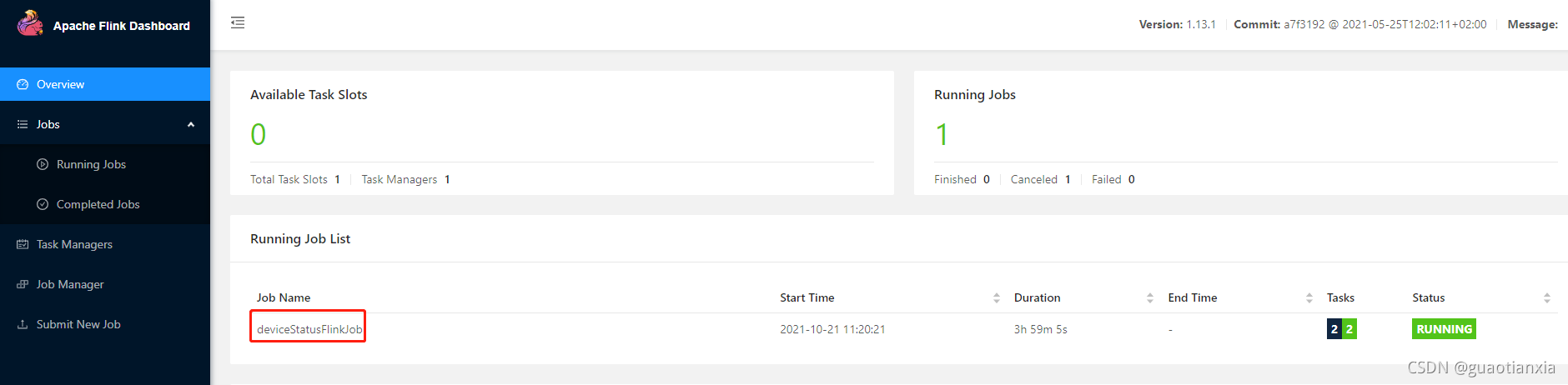
八、其他踩坑点
1、报错提示:The RemoteEnvironment cannot be instantiated when running in a pre-defined context
解决方法:将StreamExecutionEnvironment修改为getExecutionEnvironment,获取当前执行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();2、报错提示: Insufficient number of network buffers: required 65, but only 38 available. The total number of network buffers is currently set to 2048 of 32768 bytes each.
解决办法:env.setParallelism(1)
env.setParallelism(1);3、报错提示: Caused by: java.lang.IllegalStateException: Trying to access closed classloader. Please check if you store classloaders directly or indirectly in static fields. If the stacktrace suggests that the leak occurs in a third party library and cannot be fixed immediately, you can disable this check with the configuration 'classloader.check-leaked-classloader'
解决办法:在 flink 配置文件里 flink-conf.yaml设置
classloader.check-leaked-classloader: false














 229
229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









