







机器学习西瓜书,我计划本次暑假学完该课程,后面会不断更新,谢谢大家。
2.3性能度量
2.31 错误率与精度公式

查找率,查全率与F1
第三章 线性模型
3.1 基本形式
线性模型要做的有两类任务:分类任务、回归任务
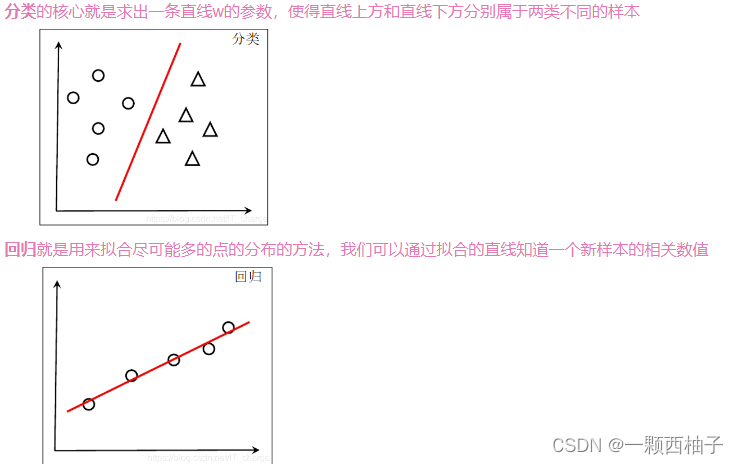

3.2 线性回归
3.2.1 一元线性回归

3.2.2 多元线性回归


3.2.3 广义线性模型(将非线性转换为线性)
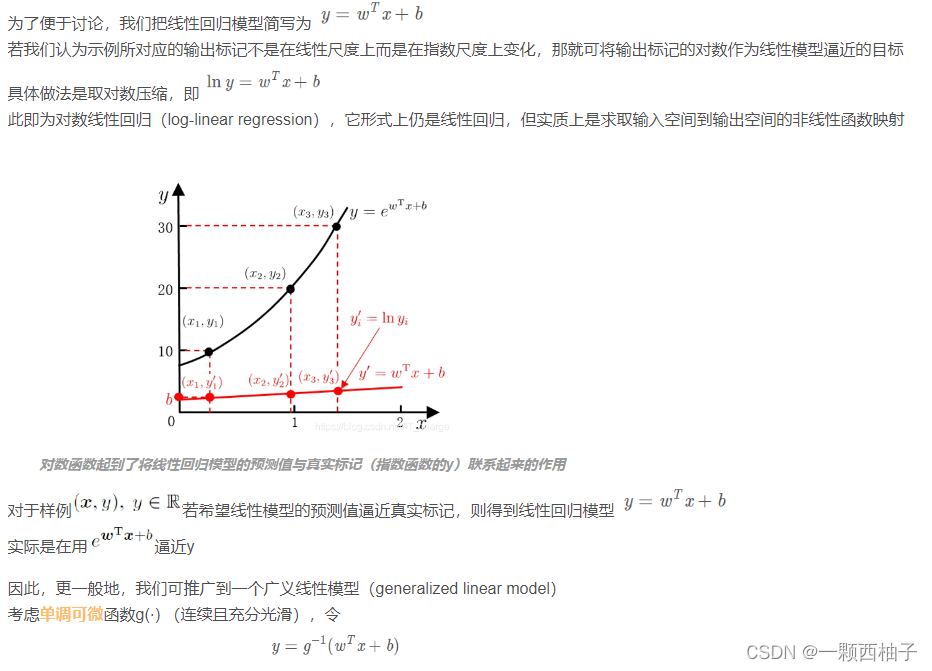

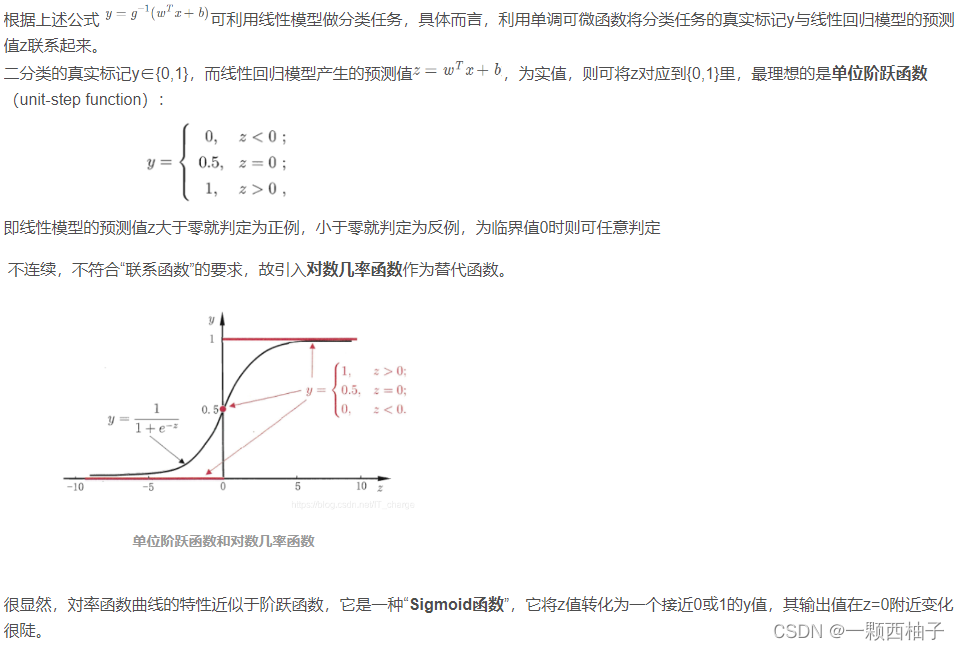
3.2.4 对数几率回归(用线性模型做分类任务)
4 决策树
决策树(decision tree):是一种基本的分类与回归方法,此处主要讨论分类的决策树。
决策树通常有三个步骤:特征选择、决策树的生成、决策树的修剪。用决策树分类:从根节点开始,对实例的某一特征进行测试,根据测试结果将实例分配到其子节点,此时每个子节点对应着该特征的一个取值,如此递归的对实例进行测试并分配,直到到达叶节点,最后将实例分到叶节点的类中。
4.1 决策树的构造
4.1.1 信息增益(ID3训练算法)

熵:划分数据集的大原则是:将无序数据变得更加有序,但是各种方法都有各自的优缺点,信息论是量化处理信息的分支科学,在划分数据集前后信息发生的变化称为信息增益,获得信息增益最高的特征就是最好的选择,所以必须先学习如何计算信息增益,集合信息的度量方式称为香农熵,或者简称熵。
信息熵

信息增益:什么是信息增益呢?在划分数据集之前之后信息发生的变化成为信息增益,知道如何计算信息增益,我们就可以计算每个特征值划分数据集获得的信息增益,获得信息增益最高的特征就是最好的选择。

4.1.2 基尼指数

6 支持向量机
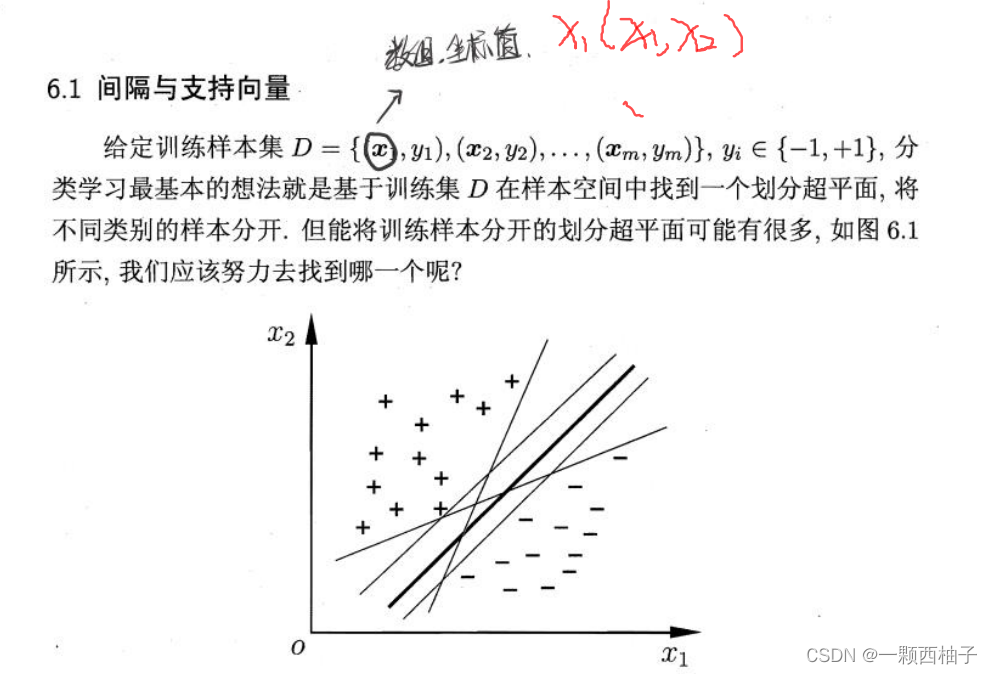
通俗来讲,所谓支持向量机是一种分类器,对于做出标记的两组向量,给出一个最优分割超曲面把这两组向量分割到两边,使得两组向量中离此超平面最近的向量(即所谓支持向量)到此超平面的距离都尽可能远。
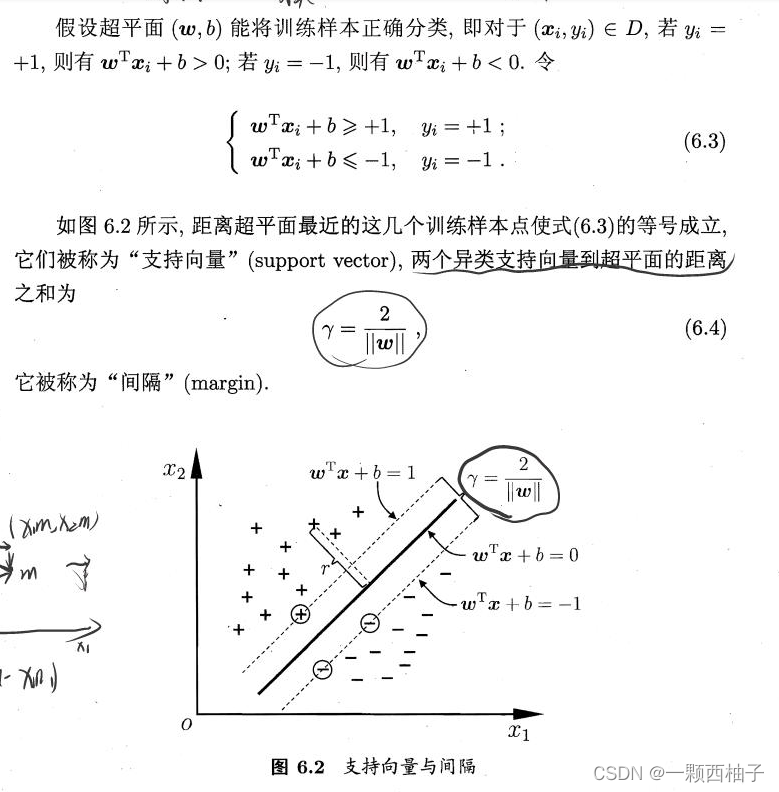
6.1间隔与支持向量
样本集中的X1表示一个点的坐标,是一个数组,y1表示该点的分类。
在前面的分析中,我们知道SVM的工作原理就是:找到离分隔超平面最近的点,确保它们离分隔面的距离尽可能的远。这里点到分隔面的距离的两倍被称为间隔,支持向量就是离分隔超平面最近的那些点。在样本空间中,划分超平面可通过如下形式来描述:
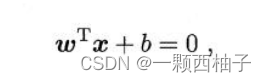
其中w = ( w 1 ; w 2 ; . . . ; w d ) 为法向量,决定了超平面的方向;b为位移项决定了超平面与原点之间的距离。下面我们将其记为( w , b ) 。样本空间中任意点x到超平面( w , b ) 的距离可写为:(点到直线的距离公式类比)



6.2对偶问题

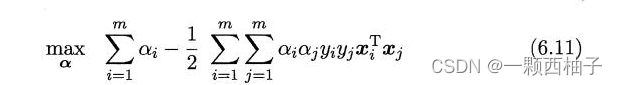

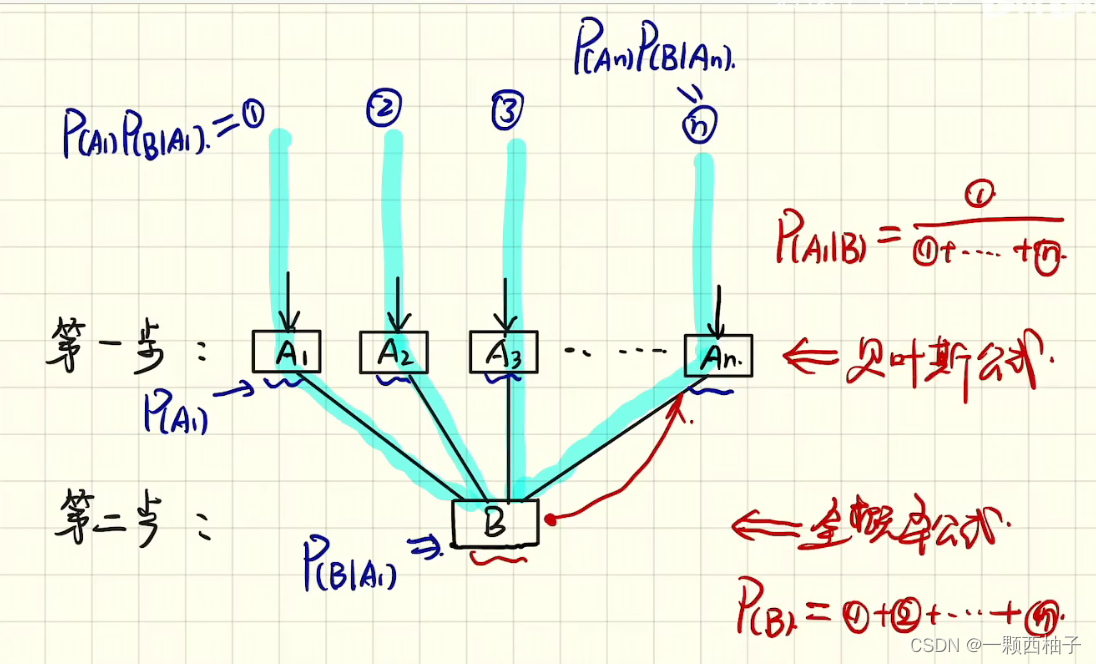
7 贝叶斯分类
7.1贝叶斯定理

P(A|B)=P(B|A)*P(A)/P(B)
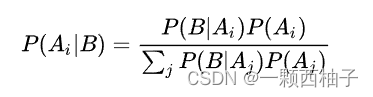

7.2 最大似然估计
似然估计,用结果去反推起因,最大似然估计,就是最有可能的起因


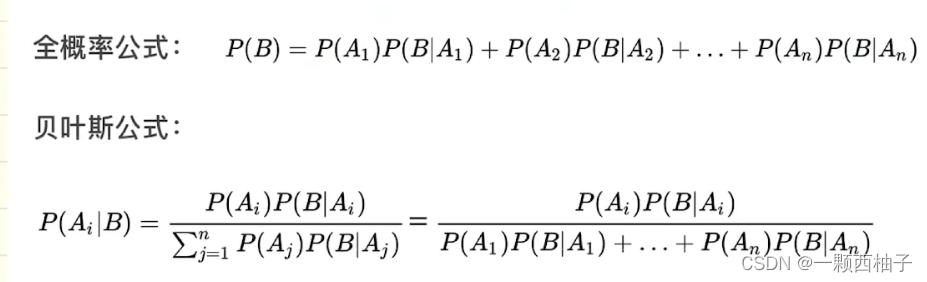















 828
828











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









