







# -*- coding:utf-8 -*-
import requests
from lxml import etree
url = "https://www.dy2018.com/html/gndy/dyzz/index.html"
response = requests.get(url)# 下面这句话最好加上
# response.encoding = response.apparent_encoding
root = etree.HTML(response.text)
page_urls = root.xpath("//select[@name='select']/option/@value")
# print(page_urls)
for url_1 in page_urls:
url_1 = "https://www.dy2018.com" + url_1 # 每一页的地址
# 下载
response = requests.get(url_1)
root = etree.HTML(response.content)
a_list = root.xpath("//td[@height='26']/b/a")
for a in a_list:
# print(a)
title = a.xpath("text()")
if title:
title = title[0]
else:
continue
# print(title)
url = a.xpath("@href")
if url:
url = url[0]
else:
continue
if not url.startswith("https"):
url = "https://www.dy2018.com" + url
movie_response = requests.get(url)
movie_root = etree.HTML(movie_response.content)
# <a>hello<b>world</b></a>
# root.xpath("//a/text()") 找到的只是hello
# root.xpath("//a//text()") 找到的是标签里面的所有文本 hello world
movie_links = movie_root.xpath("//td[@bgcolor='#fdfddf']//text()")
print(movie_links)
print(url_1)
完整代码:
# -*- coding:utf-8 -*-
import requests
from lxml import etree
url = "https://www.dy2018.com/html/gndy/dyzz/index.html"
response = requests.get(url)
# 统一网页的编码格式
# 下面这句话最好加上
# response.encoding = response.apparent_encoding
root = etree.HTML(response.text)
page_urls = root.xpath("//select[@name='select']/option/@value")
# print(page_urls)
for url_1 in page_urls:
url_1 = "https://www.dy2018.com" + url_1 # 每一页的地址
# 下载
response = requests.get(url_1)
root = etree.HTML(response.content)
a_list = root.xpath("//td[@height='26']/b/a")
for a in a_list:
# print(a)
title = a.xpath("text()")
if title:
title = title[0]
else:
continue
# print(title)
url = a.xpath("@href")
if url:
url = url[0]
else:
continue
if not url.startswith("https"):
url = "https://www.dy2018.com" + url
movie_response = requests.get(url)
movie_root = etree.HTML(movie_response.content)
# <a>hello<b>world</b></a>
# root.xpath("//a/text()") 找到的只是hello
# root.xpath("//a//text()") 找到的是标签里面的所有文本 hello world
movie_links = movie_root.xpath("//td[@bgcolor='#fdfddf']//text()")
print(movie_links)
print(url_1)
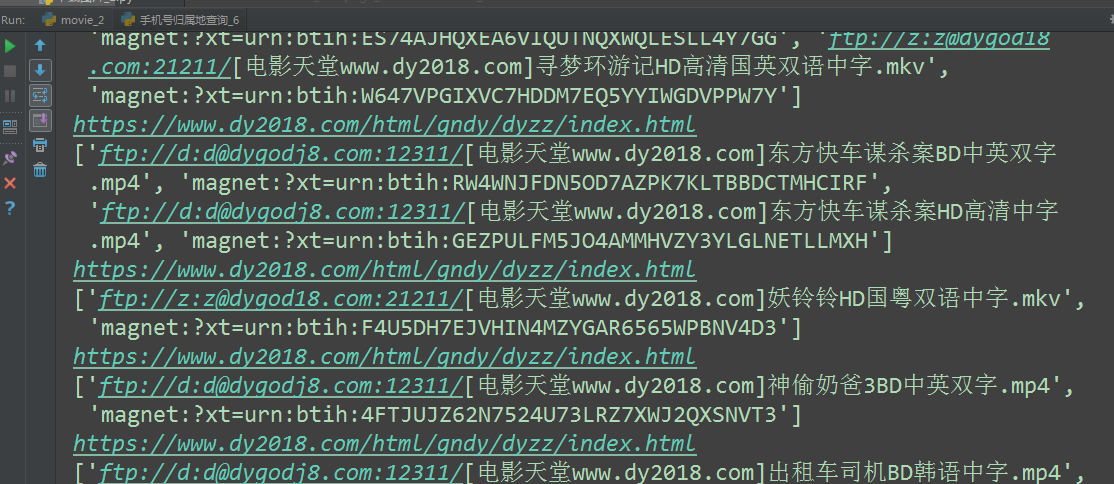
运行结果:















 1059
1059

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









