







第一部分
1.网页模板:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>电影信息网</title>
<link rel="stylesheet" href="bootstrap-3.3.7-dist/css/bootstrap.css">
<!--注意:css文件有两种形式,例如:a.css和a.min.css-->
<!--其中min.css没有多余的空行或空格,文件长度更小,有利于网络传输-->
<!--min.css一般用于生产环境-->
<!--生产环境:项目完成以后的运行环境-->
<!--css有空格或换行,文件的长度大一些,看起来更直观-->
<!--一般用于开发环境-->
<!--网页开发工具用的是HBuilder,WebStorm-->
</head>
<body>
<div class="container">
<table class="table table-bordered table-responsive table-hover">
<tr>
<td>ID</td>
<td>电影图片</td>
<td>电影名称</td>
<td>电影评分</td>
<td>上映时间</td>
<td>电影分类</td>
<td>演员表</td>
</tr>
<tr>
<td>1</td>
<td><img src="" alt="蜘蛛侠"></td>
<td>蜘蛛侠</td>
<td>9.5</td>
<td>2018-2-28</td>
<td>科幻/动作</td>
<td>刘一凡</td>
</tr>
</table>
</div>
</body>
</html>2.运行结果
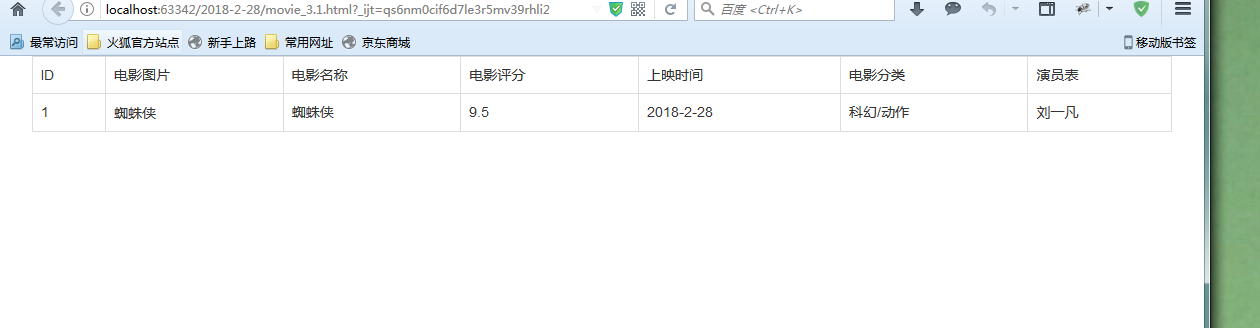
第二部分
1.下载的图片无法正常显示,所有需要把图片下载到本地,并且 把所有图片放在一个文件夹中
引入操作系统:import os
程序 要求:数据处理好之后,以网页的形式展示
注意: 如果url中的参数包含中文,那么需要先编码,否则对方服务器不识别
参数是中文的必须编码,requests包会自动编码
2. response.json()自动将响应数据解析为json对象
注意:数据格式必须满足json
法一
print(response.json())
print(type(response.json()))
法二
print(response.text)
print(type(response.text))
3.可以通过导入json包手动转换
导入文件,一般写在文件的最上面
import json
对应上面法一
json_obj = json.loads(response.text)
对应上面法二:
json_obj = response.json()
4.获取数据
movie_list = json_obj.get("result").get("movie")
5.网页中无法正确显示图片,所有需要手动下载图片
创建文件夹,将下载的图片放在一个文件夹下面
if not os.path.exists("imgs"):
os.makedirs("imgs")
6.网页相关的一些概念
<!--注意:css文件有两种形式,例如:a.css和a.min.css-->
<!--其中min.css没有多余的空行或空格,文件长度更小,有利于网络传输-->
<!--min.css一般用于生产环境-->
<!--生产环境:项目完成以后的运行环境-->
<!--css有空格或换行,文件的长度大一些,看起来更直观-->
<!--一般用于开发环境-->
<!--网页开发工具用的是HBuilder,WebStorm-->
完整代码:
# -*- coding:utf-8 -*-
import requests
# 把所有图片放在一个文件夹中
import os
# 如果url中的参数包含中文,那么需要先编码,否则对方服务器不识别
# 参数是中文的必须编码,requests包会自动编码
city = input("输入城市名称:")
url = "http://api.map.baidu.com/telematics/v3/movie?qt=hot_movie&ak=TueGDhCvwI6fOrQnLM0qmXxY9N0OkOiQ&output=json"
response = requests.get(
url,
params={"location": city}
)
# response.json()自动将响应数据解析为json对象
# 注意:数据格式必须满足json
# 法一
print(response.json())
print(type(response.json()))
# 法二
print(response.text)
print(type(response.text))
# 也可以通过导入json包手动转换
# 导入文件,一般写在文件的最上面
import json
# 对应上面法一
# json_obj = json.loads(response.text)
# 对应上面法二:
json_obj = response.json()
# print(json_obj)
movie_list = json_obj.get("result").get("movie")
with open("movie_info.html", "w", encoding="utf-8") as f:
f.write("""<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>电影信息网</title>
<link rel="stylesheet" href="bootstrap-3.3.7-dist/css/bootstrap.css">
<!--注意:css文件有两种形式,例如:a.css和a.min.css-->
<!--其中min.css没有多余的空行或空格,文件长度更小,有利于网络传输-->
<!--min.css一般用于生产环境-->
<!--生产环境:项目完成以后的运行环境-->
<!--css有空格或换行,文件的长度大一些,看起来更直观-->
<!--一般用于开发环境-->
<!--网页开发工具用的是HBuilder,WebStorm-->
</head>
<body>
<div class="container">
<table class="table table-bordered table-responsive table-hover">
<tr>
<td>ID</td>
<td>电影图片</td>
<td>电影名称</td>
<td>电影评分</td>
<td>上映时间</td>
<td>电影分类</td>
<td>演员表</td>
</tr>""")
for idx, movie in enumerate(movie_list):
# 电影图片,电影名称,评分,上映时间,分类,演员
# python中注释只有#一种形式,三个单引号和三个双引号表示字符串,不叫注释
# movie_id = movie['movie_id']
movie_picture = movie.get("movie_picture")
# 网页中无法正确显示图片,所有需要手动下载图片
movie_picture_response = requests.get(movie_picture)
movie_name = movie.get("movie_name")
# 创建文件夹
if not os.path.exists("imgs"):
os.makedirs("imgs")
with open("imgs/" + movie_name+".jpg", "wb") as f1:
f1.write(movie_picture_response.content)
movie_score = movie.get("movie_score")
movie_release_date = movie.get("movie_release_date")
movie_tags = movie.get("movie_tags")
movie_starring = movie.get("movie_starring")
f.write("""<tr>
<td>%s</td>
<td><img src="%s" alt="蜘蛛侠" width="50px"></td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
<td>%s</td>
</tr>""" % (idx+1, "imgs/" + movie_name+".jpg", movie_name, movie_score, movie_release_date, movie_tags,
movie_starring[:10]+"..."))
print(movie_picture, movie_name, movie_score, movie_release_date, movie_tags, movie_starring)
f.write("""</table>
</div>
</body>
</html>""")运行结果:
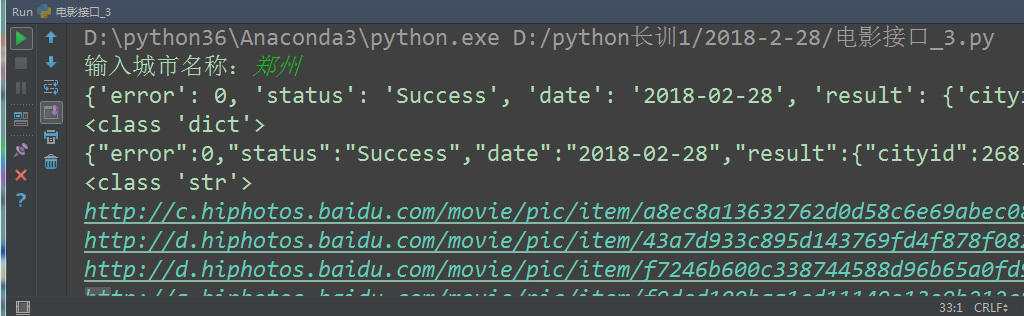
生成一个html网页
打开网页,显示结果如下:
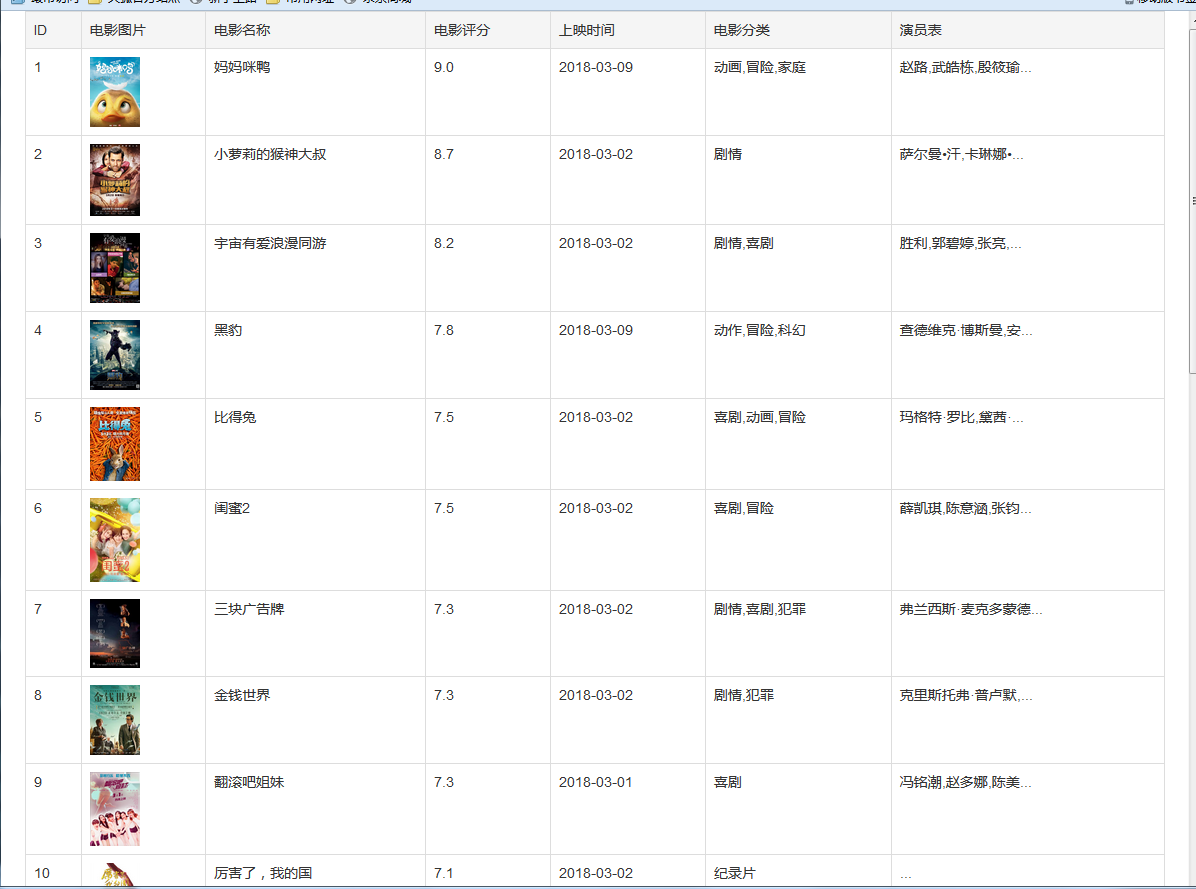

















 30万+
30万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









