







一.基本知识
1.下面的网页中
'http://neihanshequ.com/joke/?is_json=0&app_name=neihanshequ_web&max_time='
is_json=0获取到的是html数据
is_json=1获取到的是json数据
2.时间戳
只要有max_time就一直有数据
本次爬取的网页没有下一页,只有“加载更多”,只有获取到max_time(不同),才能加载出下一页
1.初始化函数
2.启动爬虫函数
3.请求函数:传入max_time,并且设置其初始参数,使其可以获取到首页的数据
4.解析函数
4.在函数内部调用执行函数本身,这种方式叫做递归函数
完整代码
# -*- coding:utf-8 -*-
"""
本文件是老师的思路:
1.初始化函数
2.启动爬虫函数
3.请求函数
4.解析函数
"""
# -*- coding:utf-8 -*-
import re
# xlwt 操作Excel表格
import xlwt
from tool import Tools
from urllib import request, parse
from fake_useragent import UserAgent
agent = UserAgent()
class NHSpider(object):
def __init__(self):
# 初始化基础url
# is_json=0从html源代码中获取
self.url = 'http://neihanshequ.com/joke/?is_json=0&app_name=neihanshequ_web&max_time='
self.headers = {'User-Agent': agent.random}
# 记录html源代码
self.html = ''
# 创建好工作簿
self.workbook = xlwt.Workbook(encoding='utf-8')
# 添加数据表
self.sheet = self.workbook.add_sheet('内涵段子')
# 写入表头
self.sheet.write(0, 0, '用户头像')
self.sheet.write(0, 1, '用户昵称')
self.sheet.write(0, 2, '发布时间')
self.sheet.write(0, 3, '段子内容')
self.sheet.write(0, 4, '点赞数')
self.sheet.write(0, 5, '踩数')
self.sheet.write(0, 6, '评论数')
self.sheet.write(0, 7, '转发数')
# 声明写入数据时记录行数的属性
self.count = 1
# 请求函数 max_time='1520296373'缺省参数
def get_html(self, max_time='1520296373'):
# 根据max_time拼接完整的url地址
url = self.url + max_time
# print(url)
req = request.Request(url, headers=self.headers)
# 发起请求,接收响应
response = request.urlopen(req)
# 转换html utf-8 gbk gb2312 记录拿到的html源代码
self.html = response.read().decode('utf-8')
# 解析数据的函数
def parse_data(self):
# 解析段子数据
data_pat = re.compile('<div.*?class="detail-wrapper.*?<img.*?src="(.*?)".*?class="name">(.*?)</span.*?<span.*?>(.*?)</span.*?<h1.*?>(.*?)</h1>.*?class="digg">(.*?)</span.*?class="bury">(.*?)</span.*?class="repin">(.*?)</span.*?class="share">(.*?)</span.*?class="comment.*?>(.*?)</span>', re.S)
res = re.findall(data_pat, self.html)
for msg in res:
print('正在爬取第%s条段子' % self.count)
data = Tools.strip_char(msg[2])
content = Tools.strip_char(msg[3])
self.sheet.write(self.count, 0, msg[0]) # 用户头像
self.sheet.write(self.count, 1, msg[1]) # 用户昵称
self.sheet.write(self.count, 2, data) # 发布日期
self.sheet.write(self.count, 3, content) # 段子内容
self.sheet.write(self.count, 4, msg[4]) # 点赞数
self.sheet.write(self.count, 5, msg[5]) # 踩数
self.sheet.write(self.count, 6, msg[6]) # 评论数
self.sheet.write(self.count, 7, msg[7]) # 转发数
# 计数+1
self.count += 1
# print(data, content)
# 匹配 max_time的正则
max_pat = re.compile("max_time: '(.*?)'", re.S)
res = re.search(max_pat, self.html)
# if res:只要有max_time就一直有数据
# self.count>300直接结束 只爬取300条数据
# if res:
if self.count < 300:
# 根据max_time再次发起请求
self.get_html(res.group(1))
# 解析数据
# 在函数内部调用执行函数本身,这种方式叫做递归函数
self.parse_data()
else:
self.workbook.save('内涵段子.xls')
# 启动爬虫的函数
def start(self):
# 调用get_html()获取第一页数据
self.get_html()
self.parse_data()
if __name__ == '__main__':
nhdz = NHSpider()
nhdz.start()
运行结果
生成300条数据:
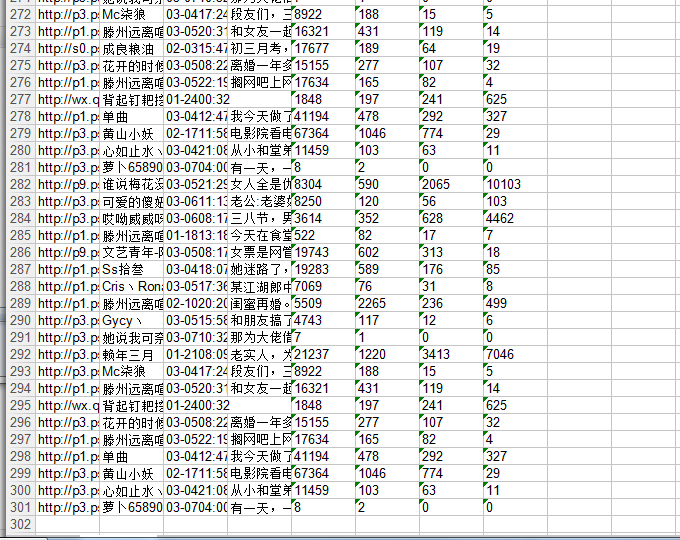















 6398
6398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









