







 本文介绍了一种使用Python实现的知乎网站登录爬虫方法。利用requests库进行HTTP请求,BeautifulSoup解析网页,通过分析知乎登录过程,实现了自动填写表单并提交登录请求的功能。
本文介绍了一种使用Python实现的知乎网站登录爬虫方法。利用requests库进行HTTP请求,BeautifulSoup解析网页,通过分析知乎登录过程,实现了自动填写表单并提交登录请求的功能。
python 爬虫——登录知乎
说明
语言,版本,包:
pytho3.4
requests.get
request.post
requests.session
步骤:
1 通过浏览器f12开发者工具,找到登录时提交的表单以及请求的url
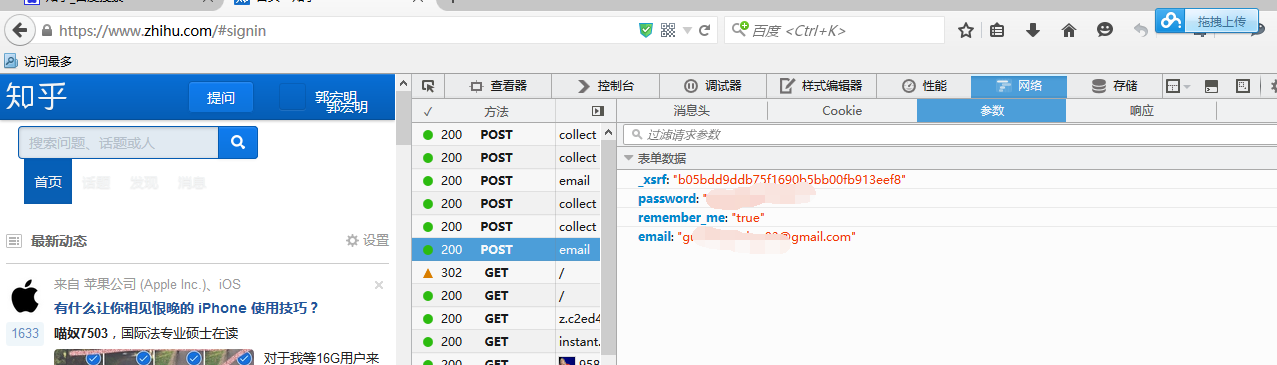
注意请求的url不是浏览器域名框的url
因为知乎改了,现在不需要验证码了,所以图片中少了验证码的参数,不过代码里是有的
2 设计到登录等会跳转的页面,推荐使用火狐浏览器,然后打开持续日志功能
3具体实现见代码
代码:
__author__ = 'Guo'
# coding:utf-8
import requests
from bs4 import BeautifulSoup
# 解决编码问题
try:
from io import BytesIO as StringIO
except ImportError:
try:
from cStringIO import StringIO
except ImportError:
from io import StringIO
def login():
header = {
'Host':"www.zhihu.com",
'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:40.0) Gecko/20100101 Firefox/40.0",
'Accept':"*/*",
'Accept-Language':"zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
'Accept-Encoding':"gzip, deflate",
'Content-Type':"application/x-www-form-urlencoded; charset=UTF-8"
}
session = requests.session() # 处理cookie
res = session.get('http://www.zhihu.com/captcha.gif',headers = header) # seesionh会记下访问验证码的cookie
with open('captcha.jpg', 'wb') as fp:
fp.write(res.content) # 讲验证码图片保存在本地。
# print(res.content)
#print(res.cookies)
# cook = res.cookies
capt = input('input captcha') # 手动读取
xsrf = BeautifulSoup(session.get('http://www.zhihu.com/#signin').content).find('input', attrs={'name': '_xsrf'})['value'] # 从源码中获取的表单中的一个字段
print(xsrf)
data = {
'_xsrf': xsrf,
'email': '*******@gmail.com',
'password': '*******',
'remember_me': 'true',
'captcha': capt
}
response = session.post('http://www.zhihu.com/login/email',data = data,headers = header ) # post 登录时提交的表单,此时session中是保存了此时的cookie 的
print(response.status_code)
print(response.content.decode('utf-8'))
html = session.get('http://www.zhihu.com/#signi') # 再次访问,由于cookie 的存在,记下了登录的状态,所以此时就可以获取我们登录之后的类容了啦。
print(html.content.decode('utf-8'))
if __name__ == '__main__':
login()
















 256
256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









