






1. 编写Scala工程代码,根据dwd层表统计每个地区、每个国家、每个月下单的数量和下单的总金额,存入MySQL数据库shtd_store的nationeverymonth表(表结构如下)中,然后在Linux的MySQL命令行中根据订单总数、消费总额、国家表主键三列均逆序排序的方式,查询出前5条,将SQL语句与执行结果截图粘贴至对应报告中;
spark.sql("select nationkey,regexp_replace(nationname,'\'','') as nationname,regionkey,regexp_replace(regionname,'\'','') as regionname,sum(totalnum) as totalorder,sum(totalprice) as totalconsumption,year,month from nationeverymonth group by nationkey,regionkey,month,nationname,year,regionname;")我为了方便查询和之后的操作,将上面的查询结果导入到新表nationeverymonths
查表
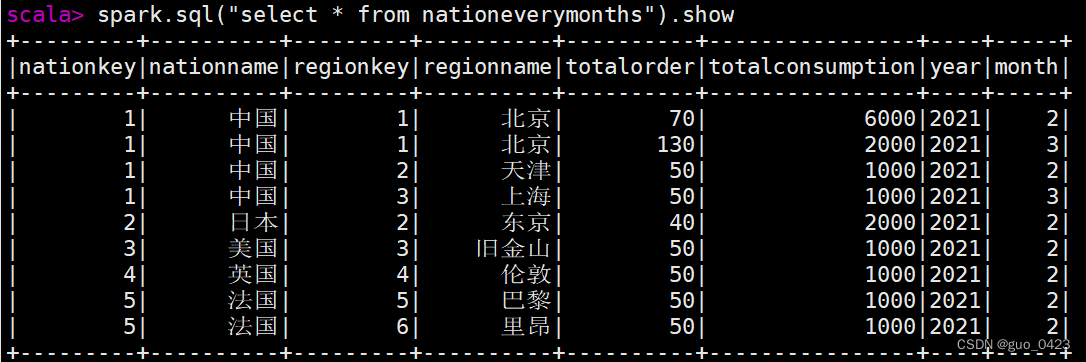
接下来将hive中的数据导入mysql中
package com.atguigu.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import java.util.Properties
object DataHiveToMySQL {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSQL")
val spark = SparkSession.builder().enableHiveSupport().config(sparkConf).getOrCreate()
val result=spark.sql("select * from ods.nationeverymonths")
val props=new Properties()
props.setProperty("user","root")
props.setProperty("password","123456")
props.setProperty("driver","com.mysql.jdbc.Driver")
result.write.mode("overwrite").jdbc("jdbc:mysql://192.168.230.132:3306/user?serverTimezone=UTC&characterEncoding=UTF-8&useSSL=false", "nationeverymonth", props)
println("导入成功")
spark.stop()
}
}运行可见导入成功

进入MySQL中查看结果
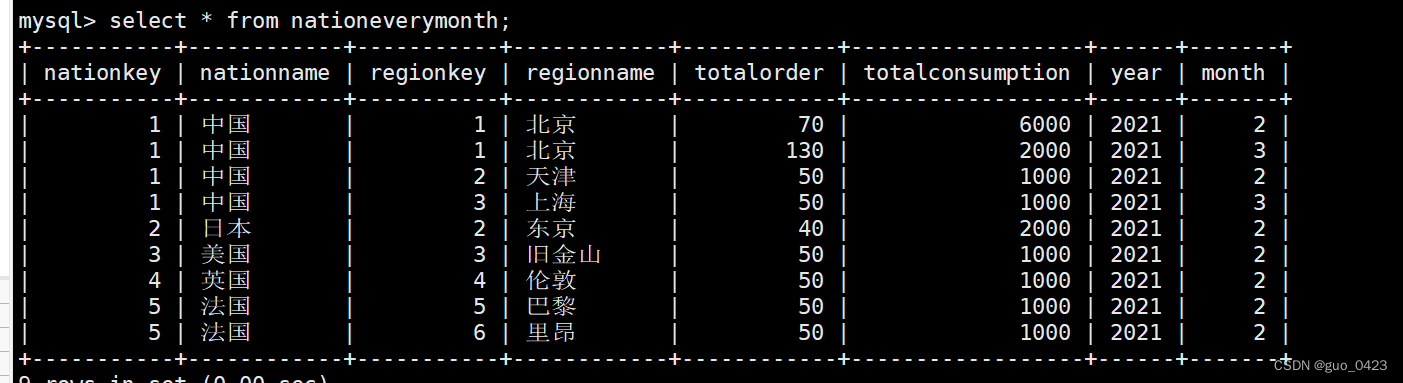 可见数据成功导入
可见数据成功导入
接下来按照要求查询:
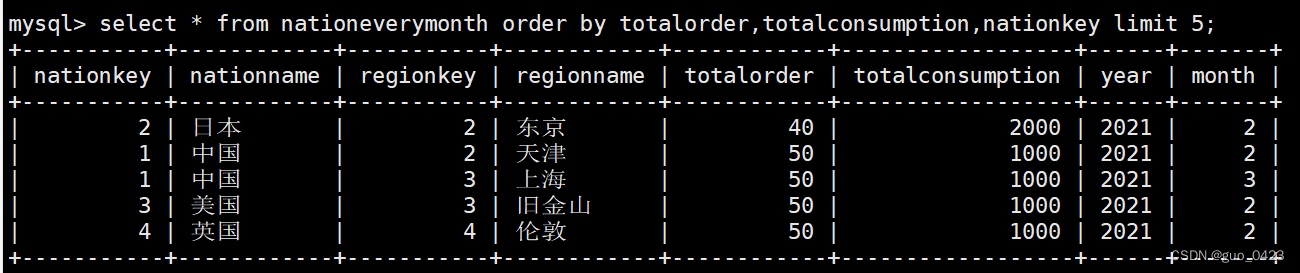
2.请根据dwd层表计算出某年每个国家的平均消费额和所有国家平均消费额相比较结果(“高/低/相同”),存入MySQL数据库shtd_store的nationavgcmp表(表结构如下)中,然后在Linux的MySQL命令行中根据订单总数、消费总额、国家表主键三列均逆序排序的方式,查询出前5条,将SQL语句与执行结果截图粘贴至对应报告中;
在解这道题的时候遇见一个问题,在求所有国家平均消费额的时候一直报错,由于没有数据这道题的题意还是有点没看明白,于是我就用了最简单的办法先新增一列,再单独将所有国家平均消费额求出来然后再插入,如果各位大佬有解决这个问题的办法希望能指导一下
先将每个国家的平均消费额求出来
spark.sql("select nationkey,nationname,avg(totalconsumption) as nationavgconsumption from nationeverymonths group by nationkey,nationname")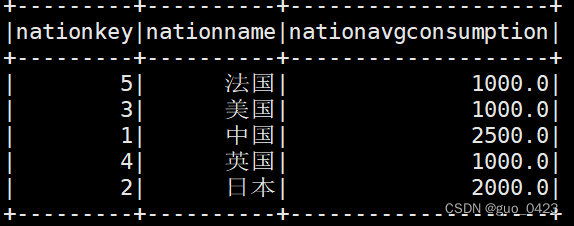
再新增一列所有国家平均消费额
spark.sql("alter table nationeverymonths add columns(avg_allstring)")再将查询到的所有国家平均消费额导入进去
spark.sql("insert overwrite table nationeverymonths1 select nationkey,nationname,avg_totalconsumpt,1500 from nationeverymonths1")再次查表
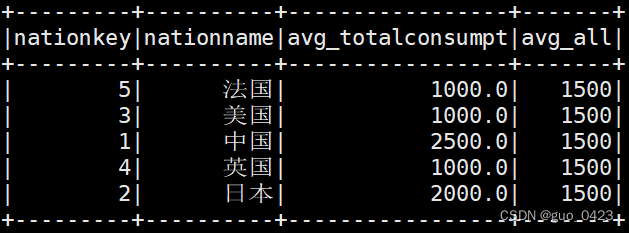
按照题意添加比较结果字段
spark.sql("select *,case when avg_totalconsumpt>avg_all then '高' when avg_totalconsumpt<avg_all then '低' when avg_totalconsumpt=avg_all then '相同' else 'null' end as comparison from nationeverymonths1").show
最后的排序语句和题一一样


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









