






题目要求: 编写Scala工程代码,将ods库中相应表数据全量抽取到Hive的dwd库中对应表中。表中有涉及到timestamp类型的,均要求按照yyyy-MM-dd HH:mm:ss,不记录毫秒数,若原数据中只有年月日,则在时分秒的位置添加00:00:00,添加之后使其符合yyyy-MM-dd HH:mm:ss。
将ods库中customer表数据抽取到dwd库中dim_customer的分区表,分区字段为etldate且值与ods库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”, 、dwd_modify_time均填写操作时间,并进行数据类型转换。在hive cli中按照cust_key顺序排序,查询dim_customer前1条数据,将结果内容复制粘贴至对应报告中;
此题应该用spark-core或者sparksql都可以,感觉用sql会简单一些
一、先将数据从customer表抽取到dim_customer
由于没有数据源,不清楚dim_customer的字段有哪些,所以就按照customer表的字段自行创建一个,数据也是我随便写吧
1.建表
spark.sql("create table dim_customer(id int,name string,age int) partitioned by (etldate string)")
这里也可以使用like,会更简单一些,但要确定两表的分区字段一致,否则会报错
2.导入数据
在这里我用的动态导入,需要先关闭严格模式
scala> spark.sql("set hive.exec.dynamic.partition.mode=nonstrict;")
spark.sql("insert overwrite table dim_customer PARTITION (etldate) select * from customer")
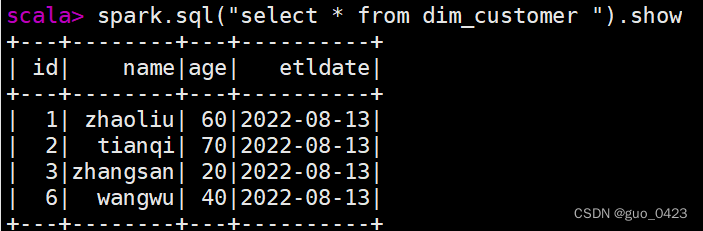
3.查表
可见数据已经导入成功
二、添加字段
spark.sql("ALTER TABLE dept add columns(dwd_insert_user string)")
spark.sql("ALTER TABLE dept add columns(dwd_insert_time string)")
spark.sql("ALTER TABLE dept add columns(dwd_modify_user string)")
spark.sql("ALTER TABLE dept add columns(dwd_modify_time string)")
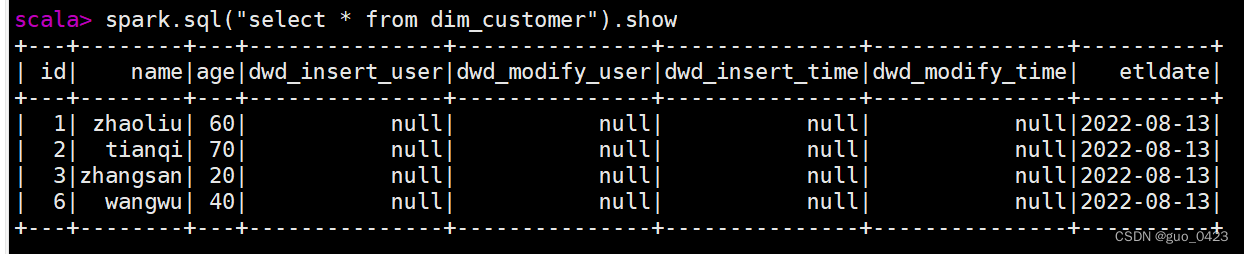
查表
我不知道hive如何在新增字段时设置默认值,所以此时新增的数据都为null,所以下一步要将null修改为我们需要的值
修改dwd_insert_user列
scala> spark.sql("insert overwrite table dim_customer partition(etldate) select id,name,age,nvl(dwd_insert_user,'user1') as dwd_insert_user,dwd_modify_user,dwd_insert_time,dwd_modify_time,etldate from dim_customer")
修改dwd_modify_user列
spark.sql("insert overwrite table dim_customer partition(etldate) select id,name,age,dwd_insert_user,nvl(dwd_modify_user,'user1') as dwd_modify_user,dwd_insert_time,dwd_modify_time,etldate from dim_customer")
修改dwd_modify_time列
spark.sql("insert overwrite table dim_customer partition(etldate) select id,name,age,dwd_insert_user,dwd_modify_user,dwd_insert_time,nvl(dwd_modify_time,'2022-08-13'),etldate from dim_customer")
修改dwd_insert_time列
spark.sql("insert overwrite table dim_customer partition(etldate) select id,name,age,dwd_insert_user,dwd_modify_user,nvl(dwd_insert_time,'2022-08-13'),dwd_modify_time,etldate from dim_customer")
三、将日期格式改为yyyy-MM-dd HH:mm:ss
由于不知道原数据是什么样,这里只改dwd_insert_time和dwd_modify_time两列
spark.sql("insert overwrite table dim_customer partition(etldate) select id,name,age,dwd_insert_user,dwd_modify_user,date_format(dwd_insert_time,'yyyy/MM/dd HH:mm:ss') as dwd_insert_time ,date_format(dwd_modify_time,'yyyy/MM/dd HH:mm:ss') as dwd_modify_timeetldate ,etldate from dim_customer") ;
注意:date_format函数如果第一个参数是字符串,连接符只能是
-,别的识别不了
四、查询
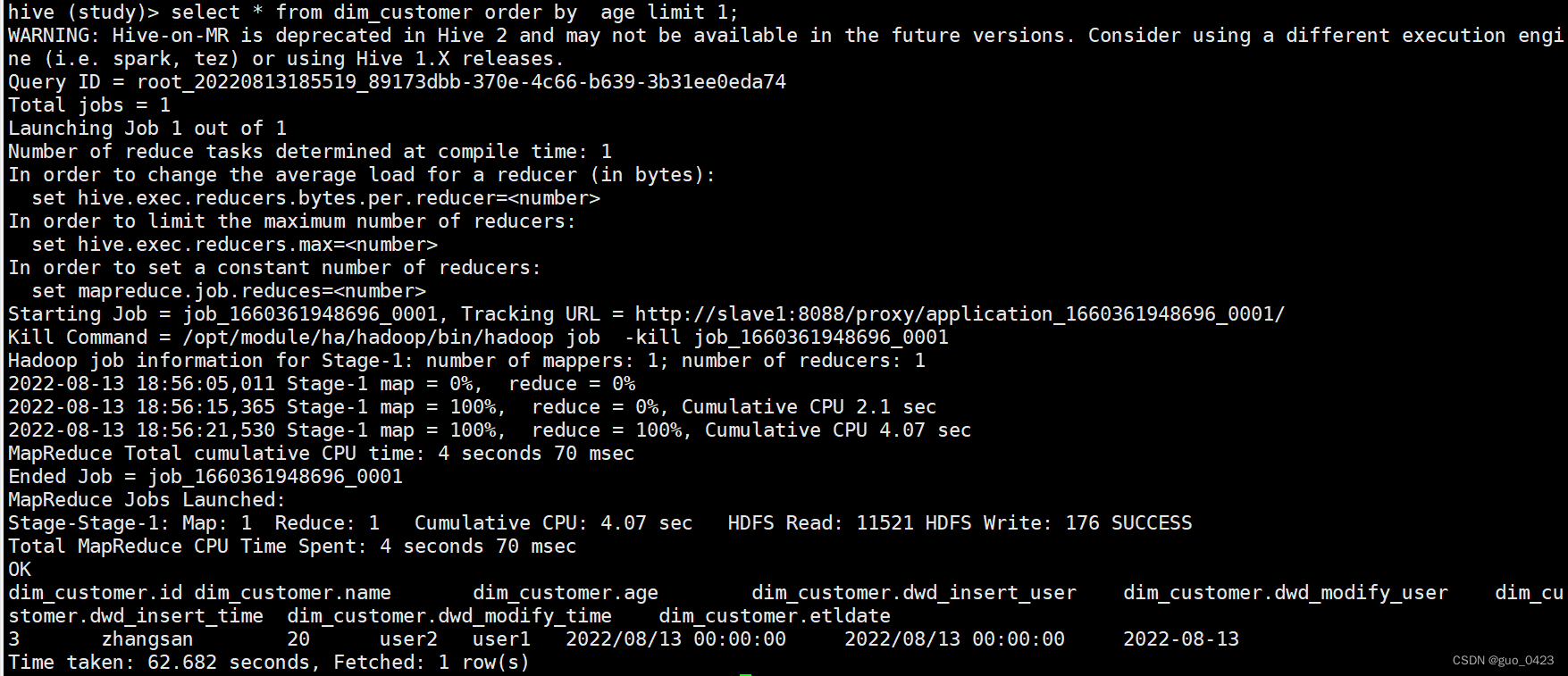
题目让使用cust_key排序,在这里我用age排序
select * from dim_customer order by age limit 1;
我感觉我写的还是有一些麻烦,如果有简单一点的希望大佬们能指点一下















 2545
2545











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









