






Linear Regression with One Variable
Hypothesis function: hθ(x)=θ0+θ1x
Idea:Choose
θ0,θ1
so that
hθ(x)
is close to
y
for our training examples
minimizeθ0,θ112m∑mi=1(hθ(x(i))−y(i))2
Parameters: θ0,θ1
Cost function: J(θ0,θ1)=12m∑mi=1(hθ(x(i))−y(i))2 , where m is the training size
So, the goal:
Note that: J(θ0,θ1)=12m∑mi=1(hθ(x(i))−y(i))2=12m∑mi=1((θ0+θ1x(i))2+(y(i))2−2(θ0+θ1x(i))y(i))
It’s a function of the parameters θ0,θ1 , its graph like the following:
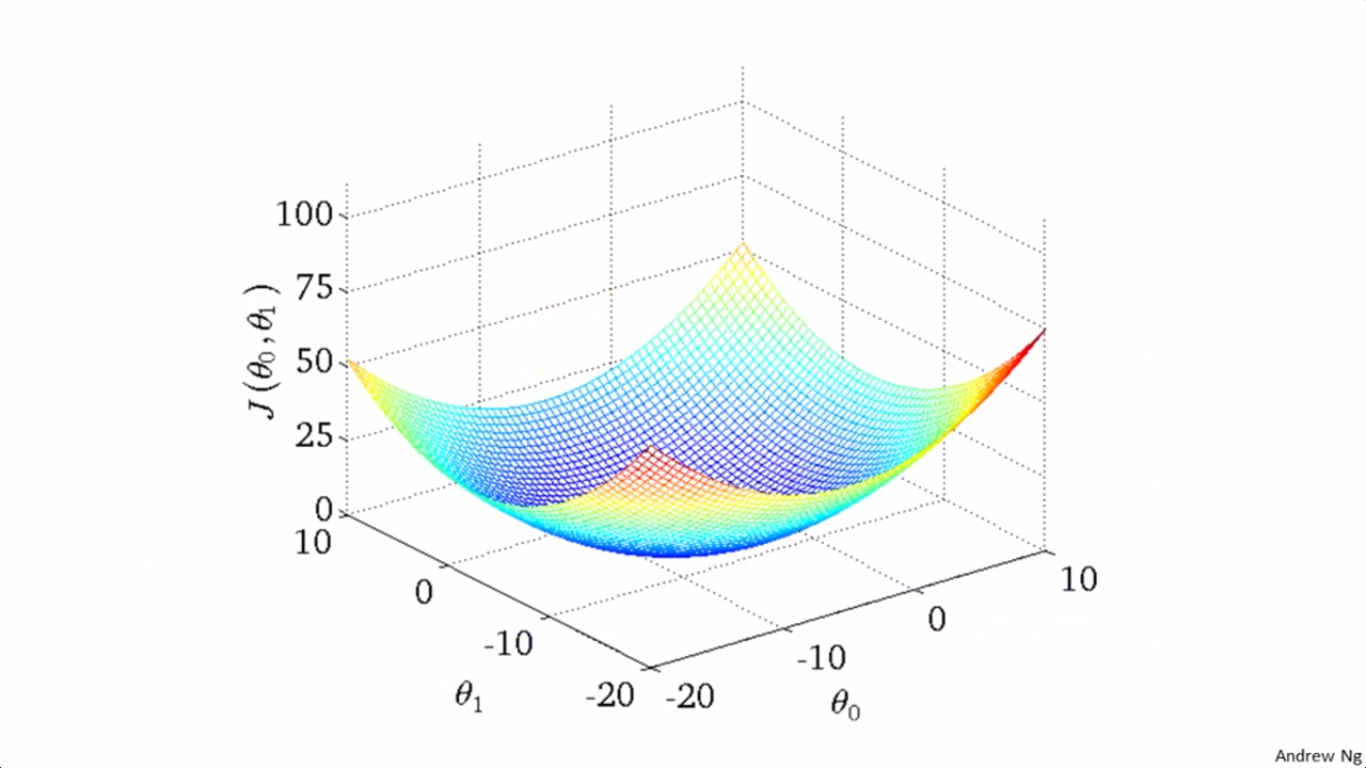
Gradient descent algorithm:
- Start with some θ0,θ1
- Keep changing θ0,θ1 to reduce J(θ0,θ1) until we hopefully end up at a minimum
repeat until convergence{
θ0:=θ0−α∂∂θ0J(θ0,θ1)=θ0−α1m∑mi=1(hθ(x(i))−y(i))
θ1:=θ1−α∂∂θ1J(θ0,θ1)=θ1−α1m∑mi=1(hθ(x(i))−y(i))⋅x(i)
(update
θ0,θ1
simultaneously)
}
where
α
is learning rate, usually set to 0.03
















 1268
1268

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











