







MachineLearning Note-Week 5
Lecture 9-Neural Networks:Learning
1. Cost function (代价函数)
神经网络的基本结构
其中
- 训练集是:
(x(1),y(1)),...,(x(m),y(m))
- L =神经网络的层数
- sl=第l层的单元个数(不包含偏置单元)
对于一个分类问题有两种情况:
- Binary Classification : y = 0 or =1. Output Layer 有一个神经元
- Multi-Class Classificaiton:
神经网络的输出层上有K个输出单元
1.1 Cost function
Logistic Regression
向量化之后应为
X是n×(m+1)维
y是n×1维
θ是(m+1)×1维
neural networks
神经网络中的输出层通常有多个输出,属于K维向量,cost function定义如下:
向量化之后应为
X是n×(m+1)维
y是n×K维
θ是L−1个sl+1×sl+1维矩阵
神经网络中的输出层通常有多个输出,属于K维向量,cost function定义如下:
向量化之后应为
X是n×(m+1)维
y是n×K维
θ是L−1个sl+1×sl+1维矩阵
目标是最小化
minΘJ(Θ)
通过下列偏导数计算梯度
J(Θ)
∂∂ΘlijJ(Θ)
2. Backpropagation algorithm(BP算法)
2.1 BP算法初探
BP算法全称为错误后向传递算法, J(Θ) 的梯度如何计算就需要请出大名鼎鼎的BP算法.
定义如下网络,输出层采用逻辑回归:
首先,我们引入 符号 δ ,解释如下:
从上图可以看出,与激励值计算类似,误差的计算也是层层传递的以上面的网络模型为例,反向传播算法从后往前(或者说从右往左)计算,即从输出层开始计算,并反向逐层向前计算每一层的 δ 。反向传播法这个名字源于我们从输出层开始计算 δ 项,然后我们返回到上一层计算第 3 个隐藏层的 δ 项,接着我们再往前一步来计算 δ2 。所以说我们是类似于把输出层的误差反向传播给了第3层,然后是再传到第2层,这就是反向传播的意思。
通过反向传播计算的这些 δ 项,可以非常快速的计算出所有参数的偏导数项( J(Θ) 关于 所有 Θ 的偏导数项)。
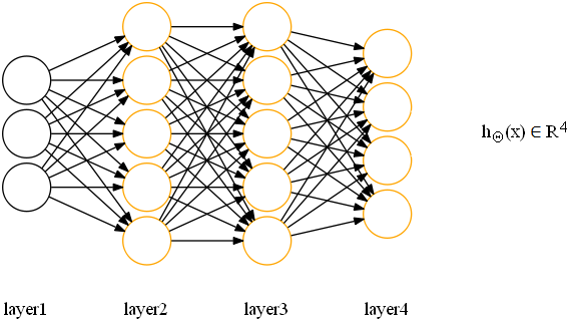

2.2 反向传播与前向传播对比

直观地看,这个 δ 项在某种程度上捕捉到了在神经节点上的激励值的误差。反过来理解,一个神经节点的残差也表明了该节点对最终输出值的残差产生了多少影响。 因此可以说, 反向传播算法就是在逐层计算每个神经节点的激励值误差。
其实
δ
本质上是代价函数
J
对加权和
2.3 δ(l) 的计算方法
δ(l)
的计算有两种不同的格式,即
不同形式的代价函数和输出层激励函数,会推导出不同的输出层误差计算公式
如下图
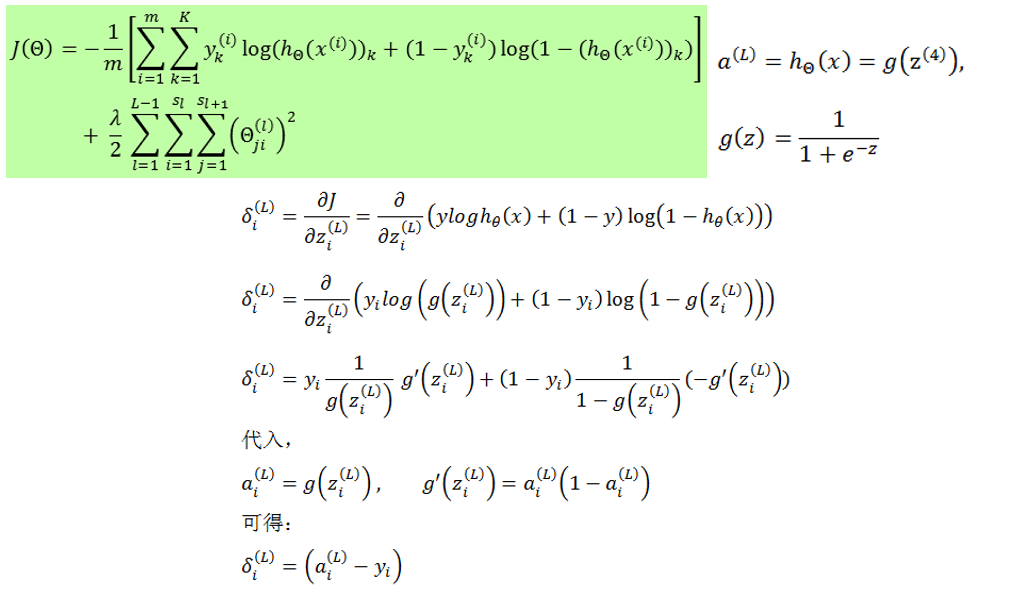
又如下图
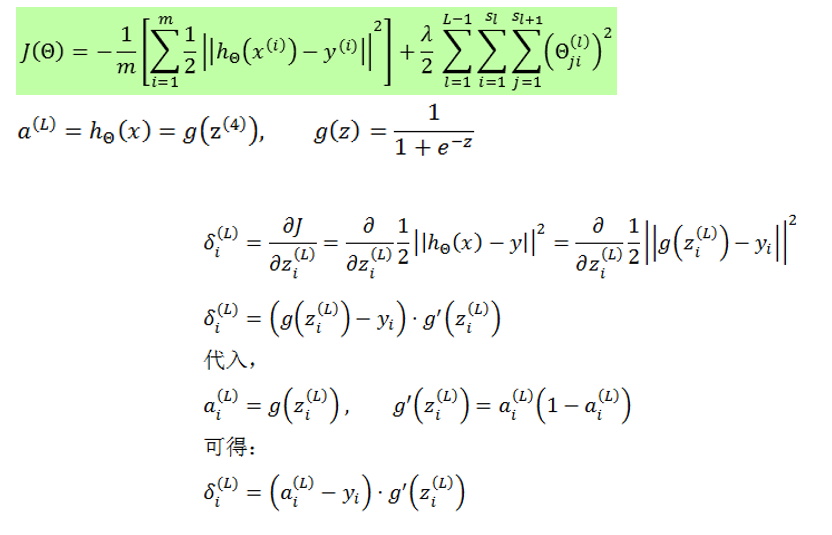
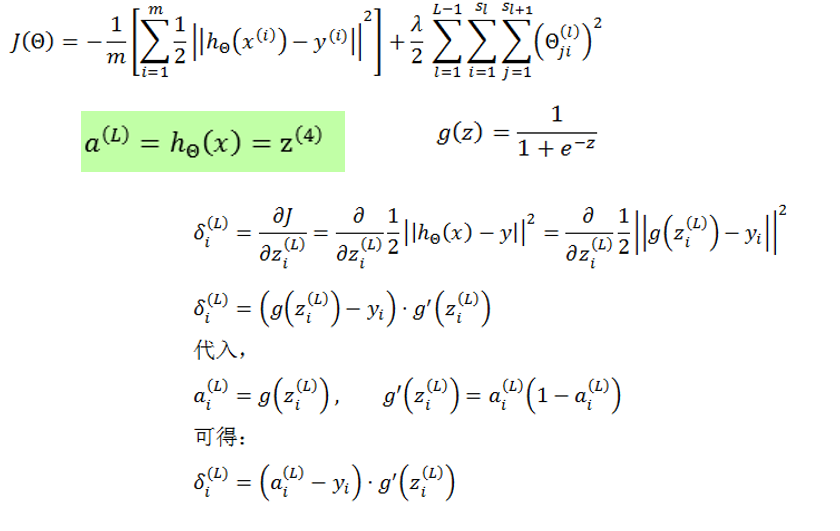
2.4 梯度计算
向量化表示如下
更为详细的证明过程参见 BP_Algorithm
2.5 BP总结
反向传播仅仅是计算过程的一个直观上的称呼罢了,更重要的是其背后的神经网络求导思想.
所以,无论说:反向传播是用来逐层计算(或称传递)误差的;又或者说:反向传播是用来计算梯度的。 其实所说所指的都是如何对神经网络的参数进行快速求导这个事情。
3 Gradient Checking(梯度检查)
3.1 为什么需要梯度检查
反向传播算法作为一个有很多细节的算法在实现的时候比较复杂,可能会遇到很多细小的错误。所以如果把BP算法和梯度下降法或者其他优化算法一起运行时,可能看起来运行正常,并且代价函数可能在每次梯度下降法迭代时都会减小,但是可能最后得到的计算结果误差较高,更要命的是很难判断这个错误结果是哪些小错误导致的。
3.2 怎样进行梯度检检查
梯度检查 (Gradient Checking)的思想就是通过数值近似(numerically approximately)的方式计算导数近似值,从而检查导数计算是否正确。虽然数值计算方法速度很慢,但实现起来很容易,并且易于理解,所以它可以用来验证例如BP算法等快速求导算法的正确性。
梯度检查 的核心是导数的数值计算
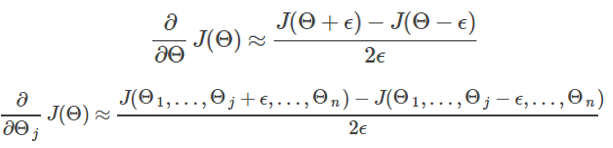
梯度检查算法实现

4. Random initialization(随机初始化)
4.1 为什么要随机初始化
将 Θ 初始化为全 0 向量在逻辑回归时是可行的的,但在训练神经网络时是不可行的,这会使得神经网络无法学习出有价值的信息。
以第一层参数矩阵(权重矩阵)为例,假定有K个隐藏单元,那么神经网络的参数矩阵 Θ1 实质上对应着特征的K个映射函数(映射关系),如果参数全为 0,那就意味着所有映射关系都是相同的,即所有的隐藏单元都在计算相同的激励值,那么这样一个具有很多隐藏单元的网络结构就是完全多余的表达,最终该网络只能学到一种特征。
4.2 随机初始化算法实现

5. Putting it together(组合到一起).
5.1设计网络结构
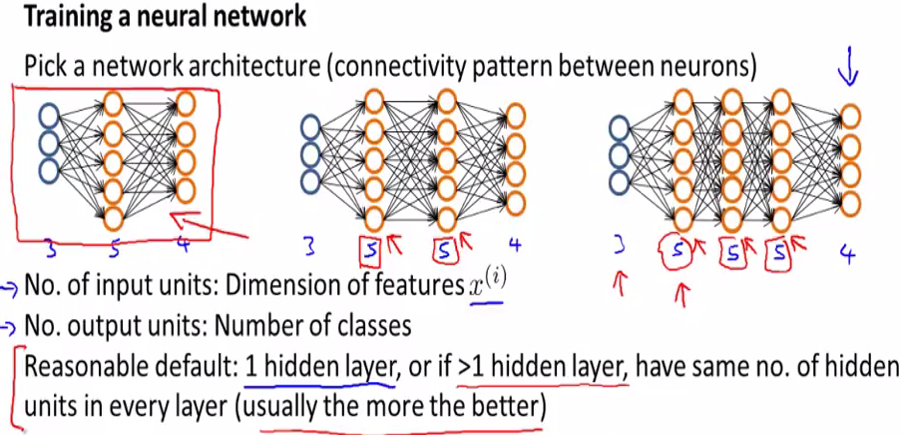
网络结构的选择规则:
一个默认的规则是只使用单个隐藏层,即PPT中最左边的结构,或者如果使用不止一个隐藏层的话,同样也有一个默认规则就是每一个隐藏层通常都应有相同的隐藏单元数。
输入层与输出层:
对于一个用于分类的神经网络,输入层即特征,输出层即类别。
隐藏单元的选择规则:
通常情况下隐藏单元越多越好,不过需要注意的是如果有大量隐藏单元,那么计算量一般会比较大。一般来说,每个隐藏层所包含的单元数量还应该和输入 x 的维度相匹配,也要和特征的数目匹配。一般来说,隐藏单元的数目取为稍大于输入特征数目都是可以接受的。
5.2 神经网络训练过程
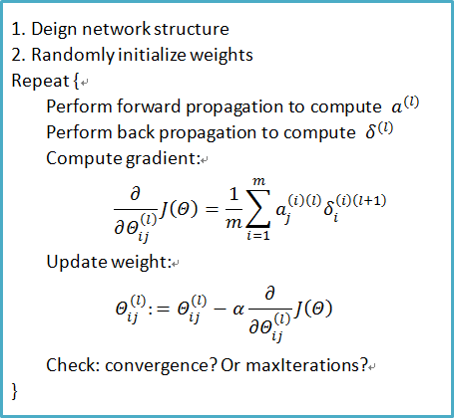
本周笔记参考文献如下
1. http://neuralnetworksanddeeplearning.com/index.html
2. http://deeplearning.stanford.edu/wiki/index.php/Backpropagation_Algorithm
3. http://deeplearning.stanford.edu/wiki/index.php/UFLDL_Tutorial
4. http://blog.csdn.net/walilk/article/details/50504393
6. 实用小技巧介绍环节
6.1 机器学习该怎么入门–知乎热门回答
https://www.zhihu.com/question/20691338/answer/53910077?group_id=692140642196811776
6.2 GraphLab
raphLab 是由CMU(卡内基梅隆大学)的Select 实验室在2010 年提出的一个基于图像处理模型的开源图计算框架,框架使用C++语言开发实现。该框架是面向机器学习(ML)的流处理并行计算框架,可以运行在多处理机的单机系统、集群或是亚马逊的EC2 等多种环境下。GraphLab 自成立以来就是一个发展很迅速的开源项目,其用户涉及的范围也相当广泛,全球有2 000 多个企业、机构使用GraphLab。
https://dato.com/
http://www.select.cs.cmu.edu/code/graphlab/
6.3 实验楼-大数据工程师学习路线图
实验楼是一个 以实验为核心的IT技术学习平台,所有实验均在Linux虚拟机上运行,实验内容干货较多。
https://www.shiyanlou.com/jobs/bigdata
6.4 如何在网上获得免费的论文资料
- 适合没有买数据库的用户使用
- 只要有论文DOI(数字对象唯一标识符)就可以下载论文
http://www.sci-hub.io/
6.5 研究人员排行榜
通过论文数量、引用率、H引子等轻松了解行业内的学术大牛,通过他们的论文进入一个学术领域
https://aminer.org/















 1186
1186











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









