








Linux版本:
iconv指令:
iconv -f 原始字符集 -t 目标字符集 原始文件 -o 目标文件
比如将日文SHIFT-JIS文件转为简体中文:
iconv -f SHIFT-JIS -t GB18030 url.txt -o test18030.txt
使用iconv有时候会报错,比如将shift-jis编码的文件转为简体中文,文件中包含一个字“須”,在转码时就报下面的错误:
iconv: illegal input sequence at position 0
意思是第0个字符,有问题。
因为shitf-jis中“須”字的编码为907B,我们使用hexdump来验证:
hexdump -n 10 -C -s 0 usrl.txt
显示如下:

也就是确实,该字符为907b。
我们再来看看,在GB2312中907b,对应哪个字符。这个可以到https://www.qqxiuzi.cn/bianma/zifuji.php 网上查询,显示如下:
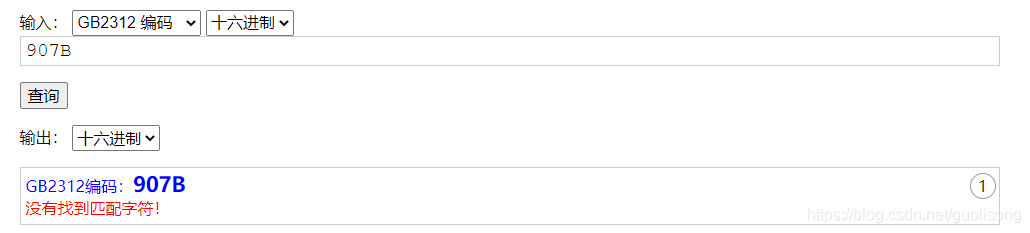
也就是907B在GB2312中是不存在的。那么,无法转换就可以理解了。
windows版本:
void codeTranslateToUTF8(int codePage,const char* srcData,string& utf8Str)
{
if(srcData)
{
int len = MultiByteToWideChar(codePage, 0, srcData,strlen(srcData), NULL, 0);//如果使用-1替代strlen(srcData),会将srcData的最后一个结尾符'\0'也进行转换
wchar_t* wstr = new wchar_t[len + 1];
wmemset(wstr, 0, len + 1);//因为是wstr是wchar类型,所以需要用wmemset
MultiByteToWideChar(codePage, 0, srcData,strlen(srcData), wstr, len);
len = WideCharToMultiByte(CP_UTF8, 0, wstr, wcslen(wstr) NULL, 0, NULL, NULL);
char* str = new char[len + 1];
memset(str, 0, len + 1);
WideCharToMultiByte(CP_UTF8, 0, wstr, wcslen(wstr), str, len, NULL, NULL);
for(int i=0;i<len;i++)
{
utf8Str.push_back(str[i]);
}
if (wstr) delete[] wstr;
if(str) delete[] str;
}
}
该函数首先将源编码格式的字符串转为utf-16的字符串,然后再将utf-16的字符串转为utf8的字符串。
输入参数codePage用于表明原始字符串的编码格式:
具体的编码格式的定义值,在下面的网页可以查询
https://docs.microsoft.com/en-us/windows/win32/intl/code-page-identifiers
比如936对应GB2312,因此如果原始文件是以GB2312格式书写的,转成utf-8时,就要输入936。同理,950表示繁体BIG5。54936则代表GB18030。
常用的编码查询网站:
日文编码查询网站(可以查询日文中的汉字):
https://www.haomeili.net/Code/DetailCodes?
汉字编码查询网站:
https://www.qqxiuzi.cn/bianma/zifuji.php

















 1091
1091

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









