







 本文介绍如何使用Keras库处理IMDB电影评论数据集,通过构建神经网络模型实现影评的情感分析,涵盖数据加载、预处理、模型训练及评估等步骤。
本文介绍如何使用Keras库处理IMDB电影评论数据集,通过构建神经网络模型实现影评的情感分析,涵盖数据加载、预处理、模型训练及评估等步骤。
简介
二分类问题是应用很广泛的机器学习问题,它根据输入,回答yes/no。
IMDB数据集,包含来自互联网电影数据库(IMDB)的50000条严重两极分化的评论。
数据集被分为用于训练的25000条评论和用于测试的25000条评论,训练集和测试集中都包括50%的正面评价和50%的负面评价。
IMDB数据集内置于Keras库中,它已经过预处理,单词序列的评论已经被转换为整数序列,其中每个整数代表字典中的某个单词。
下面开始。
加载数据
直接加载IMDB数据:
from keras.datasets import imdb
# 仅保留训练数据中前10000个最常出现的单词,舍弃低频单词
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words = 10000)
train_data/test_data变量是评论组成的列表,每条评论又是单词索引组成的列表,表示的是一系列的单词。
train_labels/test_labels是0和1组成的列表,其中0表示负面,1表示正面评论。
查看数据如下:

为了进行测试,可以使用正面的代码把某条评论数据解码为英文单词:
# 解码评论为英文单词
word_index = imdb.get_word_index()
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
decoded_review = ' '.join([reverse_word_index.get(i - 3, '?') for i in train_data[0]])
注意,第一行中的get_word_index()函数默认会从网络下载名称为imdb_word_index.json的文件。
该文件是一个将单词映射为整数索引的字典。
如果网络不好,经常会遇到下载失败的问题:TimeoutError: [WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。
建议先行下载数据到本地,加载数据时在参数中指定路径即可:
path = r"E:\practice\tf2\imdb_moive_2_classcify\imdb_word_index.json"
word_index = imdb.get_word_index(path)
如果不指定路径,会使用默认路径,一般Linux下是~/.keras/datasets/filename,windows是C:\\用户\\用户名\\。
指定绝对路径后,数据会下载在该路径下,函数在下载会先从该目录下查找文件,如果找到了有效的文件,就不再下载。
准备数据
我们不能直接将整数数据直接输入神经网络,需要先将列表转换为张量。
这里对列表进行one-hot编码,将其转换为0和1组成的向量。
代码如下:
# 将整数序列编码为二进制矩阵
import numpy as np
def vectorize_sequences(sequences, dimension = 10000):
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1.
return results
x_train = vectorize_sequences(train_data) # 向量化训练数据
x_test = vectorize_sequences(test_data) # 向量化测试数据
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')
数据现在变成了这个样子:

构建网络
输入数据是向量,输出数据是标量,使用带有relu激活的全连接层(Dense)的简单堆叠就能很好地处理这个问题,如Dense(16, activation = 'relu')。
每个带有relu激活的Dense层都实现了下列张量运算:
output = relu(dot(W, input) + b)
16个隐藏单元对应的权重矩阵W的形状为(input_dimension, 16),与W做点积相当于将输入数据投影到16维表示空间中。
隐藏单元越多,网络越能够学习到更加复杂的表示,但网络的计算代价也会越高,而且可能会导致学到不好的模式。
对于Dense层的堆叠,需要确定两个关键架构:网络的层数、每层的隐藏单元个数。
本例中使用的网络是三层,每层使用16个隐藏单元。
构建网络代码如下:
from keras import models
from keras import layers
# 模型由两个中间层(每层16个隐藏单元)和一个输出层(输出标量)组成
model = models.Sequential()
model.add(layers.Dense(16, activation = 'relu', input_shape = (10000,)))
model.add(layers.Dense(16, activation = 'relu'))
model.add(layers.Dense(1, activation = 'sigmoid'))
# 编译模型,使用内置的优化器、损失函数
model.compile(optimizer = 'rmsprop', loss = 'binary_crossentropy', metrics = ['accuracy'])
验证结果
直接上代码:
# 验证数据
x_val = x_train[:10000]
partial_x_train = x_train[10000:]
y_val = y_train[:10000]
partial_y_train = y_train[10000:]
# 训练模型,每批次512条样本,共20次迭代,把训练过程中的数据保存在history
history = model.fit(partial_x_train, partial_y_train, epochs = 20, batch_size = 512, validation_data = (x_val, y_val))
训练过程如下:

查看训练过程中的数据:

下面把结果绘制成图形,来展示效果。
- 训练损失和验证损失
# 绘制训练损失和验证损失
import matplotlib.pyplot as plt
history_dict = history.history
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']
epochs = range(1, len(loss_values) + 1)
plt.plot(epochs, loss_values, 'bo', label = 'Training loss')
plt.plot(epochs, val_loss_values, 'b', label = 'Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
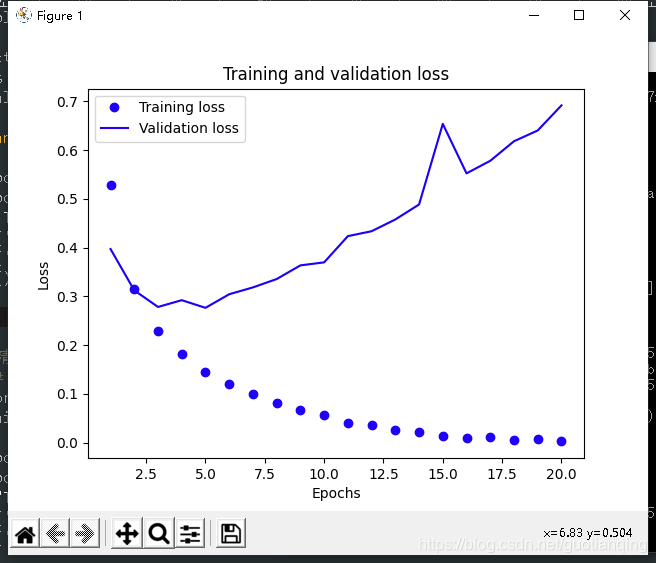
得到下图:
- 训练精度和验证精度
# 绘制训练精度和验证精度
plt.clf() # clear the pic
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
plt.plot(epochs, acc, 'bo', label = 'Training acc')
plt.plot(epochs, val_acc, 'b', label = 'Validation acc')
plt.title("Training and validation accuracy")
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
结果如下图:
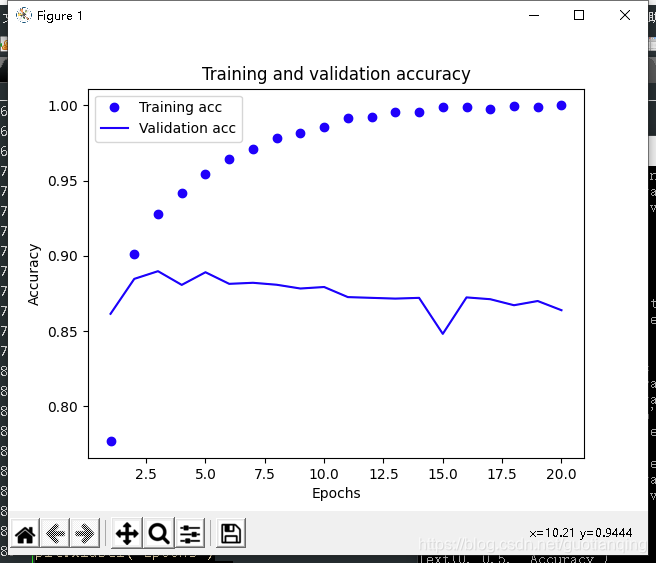
如你所见,训练损失每轮都在降低,训练精度每轮都在提升。
这正是梯度下降优化的预期结果——希望最小化的量随着每次迭代越来越小。
但验证损失和验证精度并非如此,它们好像在第4轮就达到最优值。这种现象就是过拟合。
通俗地说,模型在训练数据上的表现越来越好,但在前所未有的数据上不一定表现的也越来越好。
在第二轮之后,对训练数据的过度优化,最终学到的表示仅针对训练数据,无法泛化到训练数据集之外的数据。
防止过拟合,是深度学习中的重要议题,有多种方法可以达到这个目的,对于本例,在第3轮之后停止训练就可以做到了。
使用训练好的网络在新数据上预测结果
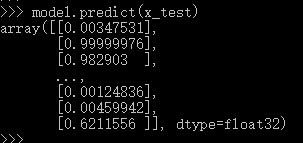
把训练好的网络用于实践,是一件令人激动的事情。predict方法可以帮你完成:
model.predict(x_test)
结果如下:
小结
本文描述了训练二分类网络的完整步骤,但并非是最佳模型。
即使是使用本例中相同的模型,仍然具有一定的改进空间,如:
- 尝试调整隐藏层数量,本例使用了2个隐藏层,可以使用1个或者3个
- 尝试使用更多的隐藏单元,本例中使用了16个
- 尝试不同的损失函数
- 尝试使用不同的激活函数
- 对过拟合的改善
参考资料
《Python深度学习》


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









