









今天的博文主要参考了以下材料:
1 2020年阿里《Scenario-aware and Mutual-based approach for Multi-scenario Recommendation in E-Commerce》—— SAML
2 2021年阿里CIKM会议的《One Model to Serve All: Star Topology Adaptive Recommender for Multi-Domain CTR Prediction》—— START
3 2022年阿里在WSDM会议的《Leaving No One Behind: A Multi-Scenario Multi-Task Meta Learning Approach for Advertiser Modeling》—— M2M
4 2020年京东的《DADNN: Multi-Scene CTR Prediction via Domain-Aware Deep Neural Network》
5 基于多Domain多任务学习框架和Transformer,搭建快手精排模型
6 美团搜索排序实践。
今天的讲解方式并不是说将以上材料中的内容按照顺序从前到后完整的论述下来。而是按照一种建模框架的思路,将各个部分的内容融合进来。好了,废话不多说,开始进入正题。
从博客的标题上看,今天要讲的是多场景学习方法。那么首先我们要明白一点什么是“多场景学习”,它和另一个本领域常见的词语“多任务学习”有什么联系和区别?
多场景学习:
不同用户群体(如新老用户)、APP不同频道模块、不同客户端等,可以看作不同场景。不同场景具有用户差异,即使是同一用户,在不同场景下的心智也不同,页面呈现的形式和内容,进入页面前的用户状态也存在很大的差异,这些差异直接反映到数据分布上,使得不同场景数据分布上存在明显差异。多场景下需要面临的最大挑战是:不同场景下的用户行为不一样,从而导致数据分布不同。
多场景与多任务区别:
多任务学习:解决相同场景/分布下的不同任务,如推荐场景下的多任务学习通常是单个样本对于 CTR,CVR 等目标同时预估;
多场景建模:解决不同场景/分布下的相同任务,如对不同场景样本预估相同的 CTR 目标。
(PS:当然如果面对的业务场景足够复杂,往往会出现 (多任务+多场景) 情况下的建模需求。)
如果将模型结构按照数据流的处理流向来看,那么可以分为输入部分,中间处理部分,和输出部分三个模块。下面我就以这三个模块为基准梳理一下在多场景学习中,每个模块的一些场景处理技巧:
输入部分
1 将场景的domain信息作为特征和模型的其他特征一起拼接输入到后续的网络结构中;(随着网络深度的增加,场景特征对最终预测结果影响有限。)
2 使用类似domain-aware的机制,引入domain-aware参数矩阵对输入的特征进行空间映射;
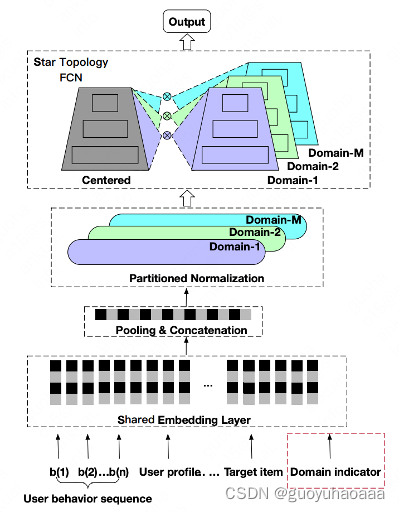
3 将场景视为bias,使用类似多模块并行结构,阿里的START就采取了这样的结构:
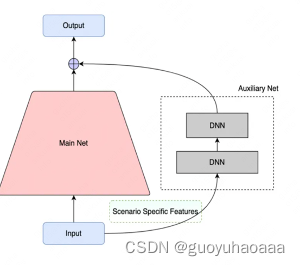
4 输入侧对齐特征语义,提取共性特征,删除独特特征;(如果是实在有用的某场景下的独有特征,可以考虑后续加入到针对对应场景的网络子结构部分)
5 使用目前的门控机制,使用能够表征domain的信息作为门控的trigger,对于输入的特征进行过滤;
6 类似阿里的START,分domain的normalization;
7 类似阿里的SAML,针对同一个特征生成两份embedding向量表征,一份代表global info(全局共享信息),另一份代码specific info(某个特定场景下的信息)。如下所示
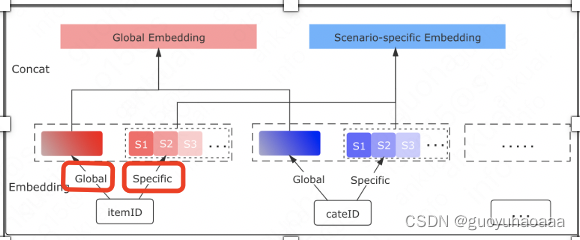
中间处理部分
1 类似快手方案中的PPNET做法,使用门控网络对网络MLP结构都加上基于场景的门控网络,使中间处理部分的网络层参数都会经过场景参数的过滤;
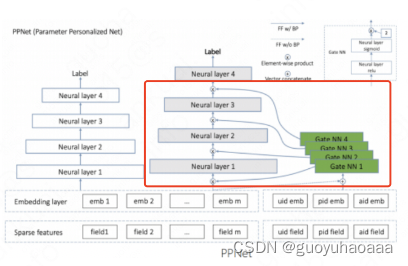
2 类似阿里的M2M结构的处理部分,使用meta unit结构进行处理,由于其同时是多任务和多场景的模型,因此整个模型的结构设计的相对复杂,需要同时将多任务和多场景信息编码入网络结构中去:
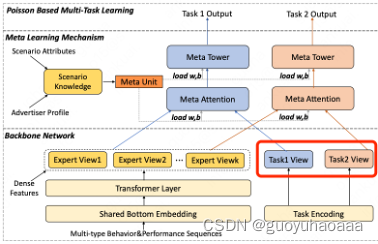
上图中的task就代表了任务标识id,比方说CTR任务,CVR任务等含义。
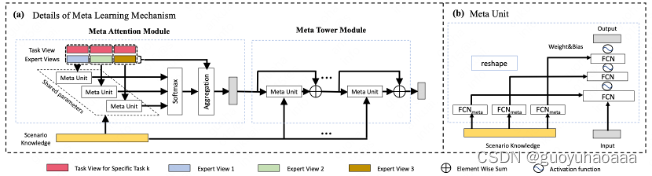
其实上图中的meta unit才是整个模型中对于多场景任务建模的精髓,将场景相关特征作为网络的weight参数,这样在不同的场景下,不同的特征就能够发挥不同的作用。
上述两种结构更多的是把重点放到了刻画不同场景的差异性和每个场景的独特性上来
3 类似阿里SAML的方式,将global共享部分和
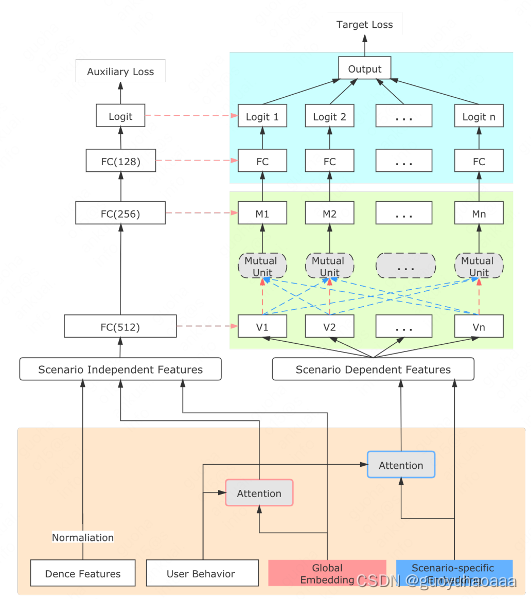
左边的网络结构是为了提取和场景无关的信息,属于global部分的网络参数,所有场景都是共享的;右边的部分则是scenario dependent 部分的网络参数,其中的
V
1
,
V
2
.
.
.
V
n
V_1,V_2...V_n
V1,V2...Vn代表了n个场景。
可以看到的是,为了将global网络学习到的信息加入到specific的网络结构中去,每一层网络的输出都有一条线输入到specific网络对应的网络结构中去,公式如下:
V
a
l
=
σ
(
V
a
l
−
1
W
a
l
+
b
l
a
)
V_a^l=\sigma(V_a^{l-1}W_a^l + b_l^a)
Val=σ(Val−1Wal+bla)
V
m
i
l
=
σ
(
[
V
m
i
l
−
1
,
V
a
l
]
W
m
i
l
+
b
m
i
l
)
V_{m_i}^l=\sigma([V_{m_i}^{l-1},V_{a}^l]W_{m_i}^l+b_{m_i}^l)
Vmil=σ([Vmil−1,Val]Wmil+bmil)
其中
V
a
l
V_a^l
Val代表了global网络的第
l
l
l层输出,
V
m
i
l
V_{m_i}^l
Vmil代表了第
m
i
m_i
mi个任务的第
l
l
l层参数。
同时为了挖掘不同场景下的联系,又提出了Mutual unit的参数结构,采用类似self-attention的思想,将不同场景下的信息和当前的目标信息计算相似度后进行聚合操作:
M
i
=
V
i
+
g
i
∗
∑
j
=
1
,
j
!
=
i
N
α
i
j
∗
V
j
M_i=V_i+g_i*\sum_{j=1,j!=i}^N{\alpha_{ij}*V_j}
Mi=Vi+gi∗∑j=1,j!=iNαij∗Vj
g
i
=
S
i
g
m
o
i
d
(
W
i
V
i
+
b
i
)
g_i=Sigmoid(W_iV_i+b_i)
gi=Sigmoid(WiVi+bi)
α
i
j
=
s
o
f
t
m
a
x
(
c
o
s
<
V
i
,
V
j
>
∑
j
=
1
,
j
!
=
i
N
c
o
s
<
V
i
,
V
j
>
)
\alpha_{ij}=softmax(\frac{cos<V_i,V_j>}{\sum_{j=1,j!=i}^Ncos<V_i,V_j>})
αij=softmax(∑j=1,j!=iNcos<Vi,Vj>cos<Vi,Vj>)
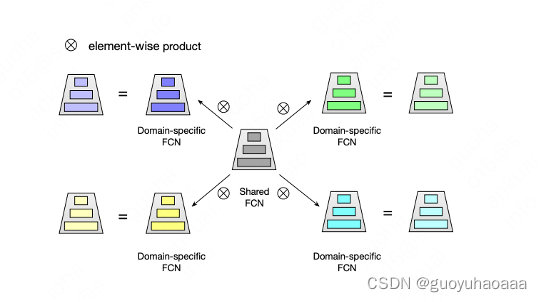
4 类似阿里START的处理,将global共享参数和specific场景定制化参数矩阵相乘,得到最终的网络处理参数,个人感觉相比于上面SAML的global和specific交互方式,这种直接将权重矩阵相乘的方式对于交互信息的挖掘总感觉弱了一些,之前笔者在自己的场景下对比过这种方式和美团CGC特征交互方式的效果,发现其效果明显差一些:
6 类似美团的处理方式,使用多任务中下的CGC模块,来建模每个场景下global信息和specific信息的交互。
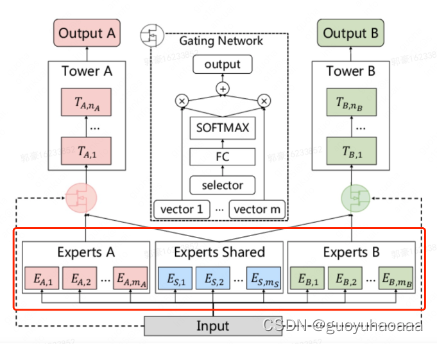
7 类似京东的DADNN中的交互方式,使用多任务中下的MMOE模块来建模每个场景下global信息和specific信息的交互。
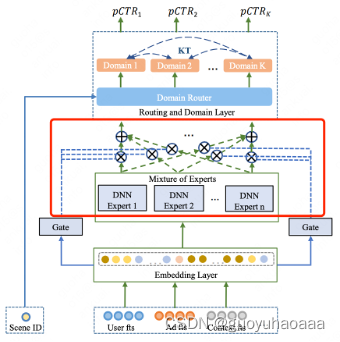
上述四种结构更多的是把重点放到提取多场景之间的共性和挖掘不同场景之间的联系上来
输出部分
1 为了刻画不同场景下的特异性,比方说针对目标场景挖掘该场景下的独有特征,往往在输出部分对不同场景的网络结构进行区分,不同的场景在输出部分走其对应的子输出网络(其实大部分网络结构都是MLP)。在美团的应用场景和阿里的SAML中都用到了这种做法:
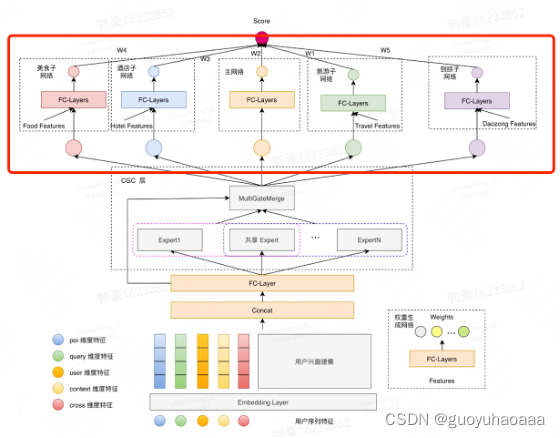
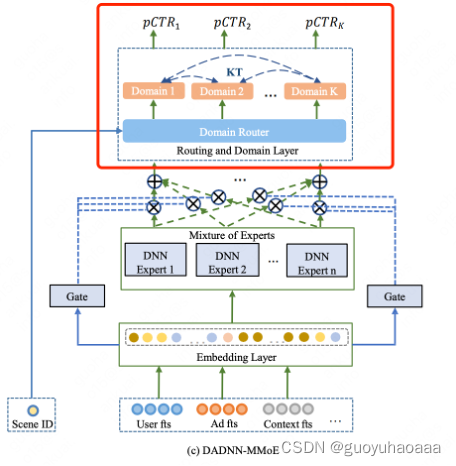
这样不同场景下的独有特征可以直接feed到对应的子网络中去,而不是在底层和其他输入一起拼接,这样降低了目标场景独有特征对其他场景的干扰。
2 为了进一步提取不同场景之间的相关性同时缓解某些数据稀疏场景下的训练不充分问题,可以在输出部分加入辅助loss,就像上图中京东在模型结构中的做法:
假设针对场景
K
K
K的样本在针对其的
d
o
m
a
i
n
K
domain_K
domainK子网络中输出是
p
(
x
i
)
p(x_i)
p(xi),那么其他domain也会对该样本有一个预测输出
q
(
x
i
)
q(x_i)
q(xi),可以将
p
(
x
i
)
p_(x_i)
p(xi)作为lable去指导其他domain子网络的输出
q
(
x
i
)
q(x_i)
q(xi)的学习。就像teacher-student学习模式一样,每一个目标场景在输入是其场景下的样本时都会作为teacher去指导其他student的学习:
L
k
t
=
∑
p
=
1
K
∑
q
=
1
,
p
!
=
q
K
w
p
q
L
p
q
L_{kt}=\sum_{p=1}^K\sum_{q=1,p!=q}^K w_{pq}L_{pq}
Lkt=∑p=1K∑q=1,p!=qKwpqLpq
L
p
q
=
−
1
N
∑
i
=
1
N
(
p
(
x
i
)
l
o
g
q
(
x
i
)
+
(
1
−
p
(
x
i
)
l
o
g
(
1
−
q
(
x
i
)
)
)
L_{pq}=-\frac{1}{N}\sum_{i=1}^{N}(p(x_i)logq({x_i})+(1-p(x_i)log(1-q(x_i)))
Lpq=−N1∑i=1N(p(xi)logq(xi)+(1−p(xi)log(1−q(xi)))
以上就是多任务学习从数据的输入,中间处理部分到最后输出部分的常用方法策略总结。大家如果在工作中遇到了同样的问题,可以进行适当的参考与创新。
永远没有银弹模型,适合你的才是最好的。与君共勉!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









