




本章目标:
- 我们需要理解什么时AI Agent,以及如何让LLM变得能干;
- 掌握使用DeepSeek开发Agent的基本方式:工具调用和ReAct范式;
- 学习如何特定任务(如小红书文案)设计Agent的工作逻辑和Prompt提示词;
- 最终打造出小红书文案智能助手。
Agent理论基础与开发入门
在当今互联网的背景下,LLM大语言模型的能力已经很强大了,那么为什么还是需要Agent呢?
这需要参考LLM和Agent的主要功能上的区别:
- LLM大语言模型:擅长理解和生成文本,但是响应通常都是一次性的响应,你问一句,它答一句;
- Agent智能体:不仅仅是对话,他是一个有自主规划,使用工具,并根据环境反馈采取行动的系统。
- 使用Agent可以让LLM从一个简单的聊天机器人进化成可以完成复杂任务的智能助理。
Agent基本概念与特点:
- 自主性:Agent可以在没有认为干预的情况下,根据设定的目标和当前环境,自主地做出决策和执行动作;
- 感知:Agent可以通过各种传输方式(如文本传输,API返回,传感器数据)感知其所处的环境和状态;
- 行动:Agent能够执行一系列动作来改变环境或达成目标。这些动作可能包括调用API,执行代码。生成文本,与其他系统交互等;
- 目标导向:Agent的所有行为都是为了实现一个或多个预定的目标。
最简单的AI Agent核心组件:Agents通过传感器收集各类的数据,借助推理引擎提出合理解决方案,并通过控制系统执行动作,以此提升能力。
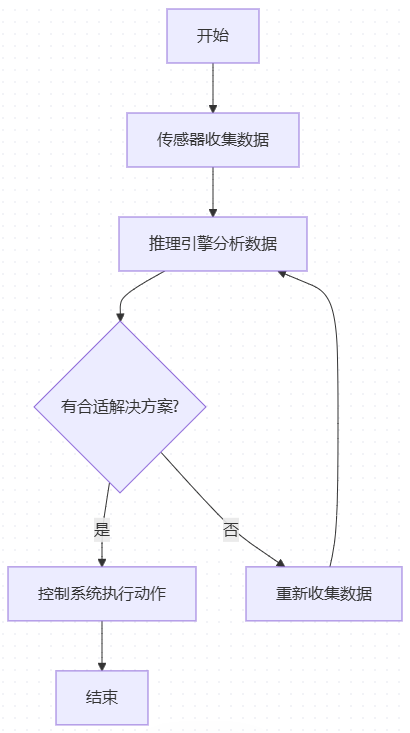
Agent核心能力和独特优势:
- 复杂任务分解与规划:LLM可以将大目标拆分为一个个可以执行的小步骤,能够动态调整计划以应对意外情况;
- 工具使用:Agent可以赋予各种工具能力,LLM负责合适使用工具;
- 长期记忆与学习:通过外部记忆模块(如向量数据库),Agent可以存储和检索过期的经验知识和历史对话,从而实现更连贯的交互和持续学习;
- 自主性与适应性:Agent能够在没人干预情况下,根据环境变化和任务进展推荐工作;
- 与外部世界交互:不在局限于文本生成,Agent可以通过工具实际影响和改变外部系统和获取外部信息。
Agent开发核心技术栈
Agent开发流程和关键模块分析:
- 定义目标与范围:
-
- Agent要完成什么具体任务?
- 任务的边界和约束是什么?
- 选择核心LLM:选择一个具备良好的指令遵循能力,推理能力和工具使用能力的LLM。
- 设计Agent架构:
-
- 核心逻辑/控制器:负责驱动整个Agent的运行流程;
- 规划模块:LLM思考如何分解任务,并提供调用接口;
- 工具集:定义Agent可以使用的工具,并提供调用接口;
- 记忆执行:短期记忆(历史对话),长期记忆(知识库);
- 行动执行器:实际执行LLM决定的动作。
- 工具开发与集成:
-
- 为了Agent需要的每个功能开发或者封装为一个工具;
- 确保LLM能够理解工具的描述,输入输出格式。
- 提示词工程:
-
- 设计精良的Prompt(至关重要)来引导LLM进行思考,规划,工具选择和最终输出;
- Prompt建议包含:Agent角色,目标,可用工具描述,输出格式要求,思考链模板等。
- 记忆机制实现:选择合适的记忆存储(如简单的列表,向量数据库)。
- 测试,评估与迭代:
-
- 在各种场景测试Agent 的表现;
- 评估其任务完成率,效率,鲁棒性;
- 根据测试结果不断优化Prompt,工具,计划逻辑等。
DeepSeek Agent开发入门
Agent基本概念回顾:
- 不仅仅是语言模型,而是具备感知,规划,决策,执行,反思能力的智能体;
- 核心要素:LLM(大脑)+工具(双手)+记忆(经验)+规划与反思(思维);
DeepSeek Agent 的特点与优势:
- 强大的推理能力:DeepSeek模型在复杂逻辑推理和多步骤任务处理上表现出色;
- 灵活的工具调用:无缝集成外部API,函数,扩展LLM的能力边界;
- 高效的任务执行循环:通过迭代的"思考-行动-观察"循环,逐步逼近目标;
- 易于开发与部署:提供友好的接口和框架,降低Agent开发门槛。
Agent核心架构与工作流:
- 用户指令输入:接收用户的任务需求;
- 意图理解与规划(LLM核心):
-
- DeepSeek模型分析用户意图,将其分解为一系列可执行的子任务;
- 生成初步的执行计划和步骤;
- 工具选择与调用:
-
- 根据规划的子任务,智能选择最合适的外部工具(Function Calling);
- 构造工具调用参数,并执行。
- 结果观察与反思:
-
- 接收工具执行结果;
- DeepSeek模型对结果进行评估和分析:是否达到预期?是否有新的信息?是否需要调整计划?
- 循环与迭代:
-
- 基于反思结果,修正计划;
- 再次进入工具选择与调用阶段,直至任务完成或者达到终止条件。
- 最终输出:将任务结果以用户可理解的方式呈现。
Prompt核心作用:指定DeepSeek Agent行为,设定其能力边界和目标的关键,如果Agent的操作系统。
DeepSeek Prompt的核心组成:
- System Prompt(角色与全局设定):定义Agent 身份,专业领域,基本行为准则和总体目标;
- User Promp(任务指令):用户具体输入的任务需求;
- Tool Description(工具描述):在system或tools参数中详细描述可用工具的功能,参数和用途。
- Few-shot Examples(示例引导):提供输入-输出的少量示例,帮助大模型理解复杂任务模式或者特点的行为规范。

import os
from openai import OpenAI
# 从环境变量中获取 API 密钥
api_key = os.getenv("DEEPSEEK_API_KEY")
if not api_key:
raise ValueError("DEEPSEEK_API_KEY environment variable not set")
# 初始化DeepSeek客户端
client = OpenAI(
api_key=api_key,
base_url="https://api.deepseek.com/v1",
)
# 1. 先定义 tools(解决作用域问题)
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get weather of a location, the user should supply a location first",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and country, e.g. Shanghai, CN",
}
},
"required": ["location"]
},
}
},
]
# 2. 定义 send_messages 函数(此时 tools 已定义)
def send_messages(messages):
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages,
tools=tools, # 引用已定义的 tools
tool_choice="auto" # 显式指定自动选择工具(可选,增强稳定性)
)
return response.choices[0].message
# 3. 执行核心逻辑
# 初始化用户消息
messages = [{"role": "user", "content": "How's the weather in Shanghai?"}]
print(f"User>\t {messages[0]['content']}")
# 第一步调用:触发工具调用
message = send_messages(messages)
# 检查是否有工具调用(增加容错)
if hasattr(message, 'tool_calls') and message.tool_calls:
tool = message.tool_calls[0]
print(f"Tool Call>\t {tool.function.name} (参数: {tool.function.arguments})")
# 将模型的工具调用消息加入对话上下文
messages.append(message)
# 模拟工具调用结果(修复 role 格式:正确为 function 类型的响应)
tool_response = {
"role": "function", # 关键:tool 响应的 role 应为 function
"name": tool.function.name, # 必须指定调用的函数名
"tool_call_id": tool.id,
"content": "24℃"
}
messages.append(tool_response)
# 第二步调用:传入工具结果,获取最终回答
final_message = send_messages(messages)
print(f"Model>\t {final_message.content}")
else:
# 兜底:模型未触发工具调用时直接返回结果
print(f"Model>\t {message.content}")DeepSeek小红书文案
import os
from openai import OpenAI
# 建议将 API Key 设置为环境变量,避免直接暴露在代码中
# 从环境变量获取 DeepSeek API Key
api_key = os.getenv("DEEPSEEK_API_KEY")
if not api_key:
raise ValueError("请设置 DEEPSEEK_API_KEY 环境变量")
# 初始化 DeepSeek 客户端
client = OpenAI(
api_key=api_key,
base_url="https://api.deepseek.com/v1", # DeepSeek API 的基地址
)
SYSTEM_PROMPT = """
你是一个资深的小红书爆款文案专家,擅长结合最新潮流和产品卖点,创作引人入胜、高互动、高转化的笔记文案。
你的任务是根据用户提供的产品和需求,生成包含标题、正文、相关标签和表情符号的完整小红书笔记。
请始终采用'Thought-Action-Observation'模式进行推理和行动。文案风格需活泼、真诚、富有感染力。当完成任务后,请以JSON格式直接输出最终文案,格式如下:
```json
{
"title": "小红书标题",
"body": "小红书正文",
"hashtags": ["#标签1", "#标签2", "#标签3", "#标签4", "#标签5"],
"emojis": ["✨", "🔥", "💖"]
}
```
在生成文案前,请务必先思考并收集足够的信息。
"""
TOOLS_DEFINITION = [
{
"type": "function",
"function": {
"name": "search_web",
"description": "搜索互联网上的实时信息,用于获取最新新闻、流行趋势、用户评价、行业报告等。请确保搜索关键词精确,避免宽泛的查询。",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "要搜索的关键词或问题,例如'最新小红书美妆趋势'或'深海蓝藻保湿面膜 用户评价'"
}
},
"required": ["query"]
}
}
},
{
"type": "function",
"function": {
"name": "query_product_database",
"description": "查询内部产品数据库,获取指定产品的详细卖点、成分、适用人群、使用方法等信息。",
"parameters": {
"type": "object",
"properties": {
"product_name": {
"type": "string",
"description": "要查询的产品名称,例如'深海蓝藻保湿面膜'"
}
},
"required": ["product_name"]
}
}
},
{
"type": "function",
"function": {
"name": "generate_emoji",
"description": "根据提供的文本内容,生成一组适合小红书风格的表情符号。",
"parameters": {
"type": "object",
"properties": {
"context": {
"type": "string",
"description": "文案的关键内容或情感,例如'惊喜效果'、'补水保湿'"
}
},
"required": ["context"]
}
}
}
]
#%% md
### 3.3 模拟工具实现
由于我们无法直接调用真实的外部 API (如Google Search或内部产品数据库),我们将创建一些模拟 (Mock) 工具函数来演示 Agent 的工作流程。在实际应用中,您需要将这些模拟函数替换为真实的 API 调用。
import random # 用于模拟生成表情
import time # 用于模拟网络延迟
def mock_search_web(query: str) -> str:
"""模拟网页搜索工具,返回预设的搜索结果。"""
print(f"[Tool Call] 模拟搜索网页:{query}")
time.sleep(1) # 模拟网络延迟
if "小红书美妆趋势" in query:
return "近期小红书美妆流行'多巴胺穿搭'、'早C晚A'护肤理念、'伪素颜'妆容,热门关键词有#氛围感、#抗老、#屏障修复。"
elif "保湿面膜" in query:
return "小红书保湿面膜热门话题:沙漠干皮救星、熬夜急救面膜、水光肌养成。用户痛点:卡粉、泛红、紧绷感。"
elif "深海蓝藻保湿面膜" in query:
return "关于深海蓝藻保湿面膜的用户评价:普遍反馈补水效果好,吸收快,对敏感肌友好。有用户提到价格略高,但效果值得。"
else:
return f"未找到关于 '{query}' 的特定信息,但市场反馈通常关注产品成分、功效和用户体验。"
def mock_query_product_database(product_name: str) -> str:
"""模拟查询产品数据库,返回预设的产品信息。"""
print(f"[Tool Call] 模拟查询产品数据库:{product_name}")
time.sleep(0.5) # 模拟数据库查询延迟
if "深海蓝藻保湿面膜" in product_name:
return "深海蓝藻保湿面膜:核心成分为深海蓝藻提取物,富含多糖和氨基酸,能深层补水、修护肌肤屏障、舒缓敏感泛红。质地清爽不粘腻,适合所有肤质,尤其适合干燥、敏感肌。规格:25ml*5片。"
elif "美白精华" in product_name:
return "美白精华:核心成分是烟酰胺和VC衍生物,主要功效是提亮肤色、淡化痘印、改善暗沉。质地轻薄易吸收,适合需要均匀肤色的人群。"
else:
return f"产品数据库中未找到关于 '{product_name}' 的详细信息。"
def mock_generate_emoji(context: str) -> list:
"""模拟生成表情符号,根据上下文提供常用表情。"""
print(f"[Tool Call] 模拟生成表情符号,上下文:{context}")
time.sleep(0.2) # 模拟生成延迟
if "补水" in context or "水润" in context or "保湿" in context:
return ["💦", "💧", "🌊", "✨"]
elif "惊喜" in context or "哇塞" in context or "爱了" in context:
return ["💖", "😍", "🤩", "💯"]
elif "熬夜" in context or "疲惫" in context:
return ["😭", "😮💨", "😴", "💡"]
elif "好物" in context or "推荐" in context:
return ["✅", "👍", "⭐", "🛍️"]
else:
return random.sample(["✨", "🔥", "💖", "💯", "🎉", "👍", "🤩", "💧", "🌿"], k=min(5, len(context.split())))
# 将模拟工具函数映射到一个字典,方便通过名称调用
available_tools = {
"search_web": mock_search_web,
"query_product_database": mock_query_product_database,
"generate_emoji": mock_generate_emoji,
}
import json
import re
def generate_rednote(product_name: str, tone_style: str = "活泼甜美", max_iterations: int = 5) -> str:
"""
使用 DeepSeek Agent 生成小红书爆款文案。
Args:
product_name (str): 要生成文案的产品名称。
tone_style (str): 文案的语气和风格,如"活泼甜美"、"知性"、"搞怪"等。
max_iterations (int): Agent 最大迭代次数,防止无限循环。
Returns:
str: 生成的爆款文案(JSON 格式字符串)。
"""
print(f"\n🚀 启动小红书文案生成助手,产品:{product_name},风格:{tone_style}\n")
# 存储对话历史,包括系统提示词和用户请求
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": f"请为产品「{product_name}」生成一篇小红书爆款文案。要求:语气{tone_style},包含标题、正文、至少5个相关标签和5个表情符号。请以完整的JSON格式输出,并确保JSON内容用markdown代码块包裹(例如:```json{{...}}```)。"}
]
iteration_count = 0
final_response = None
while iteration_count < max_iterations:
iteration_count += 1
print(f"-- Iteration {iteration_count} --")
try:
# 调用 DeepSeek API,传入对话历史和工具定义
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages,
tools=TOOLS_DEFINITION, # 告知模型可用的工具
tool_choice="auto" # 允许模型自动决定是否使用工具
)
response_message = response.choices[0].message
# **ReAct模式:处理工具调用**
if response_message.tool_calls: # 如果模型决定调用工具
print("Agent: 决定调用工具...")
messages.append(response_message) # 将工具调用信息添加到对话历史
tool_outputs = []
for tool_call in response_message.tool_calls:
function_name = tool_call.function.name
# 确保参数是合法的JSON字符串,即使工具不要求参数,也需要传递空字典
function_args = json.loads(tool_call.function.arguments) if tool_call.function.arguments else {}
print(f"Agent Action: 调用工具 '{function_name}',参数:{function_args}")
# 查找并执行对应的模拟工具函数
if function_name in available_tools:
tool_function = available_tools[function_name]
tool_result = tool_function(**function_args)
print(f"Observation: 工具返回结果:{tool_result}")
tool_outputs.append({
"tool_call_id": tool_call.id,
"role": "tool",
"content": str(tool_result) # 工具结果作为字符串返回
})
else:
error_message = f"错误:未知的工具 '{function_name}'"
print(error_message)
tool_outputs.append({
"tool_call_id": tool_call.id,
"role": "tool",
"content": error_message
})
messages.extend(tool_outputs) # 将工具执行结果作为 Observation 添加到对话历史
# **ReAct 模式:处理最终内容**
elif response_message.content: # 如果模型直接返回内容(通常是最终答案)
print(f"[模型生成结果] {response_message.content}")
# --- START: 添加 JSON 提取和解析逻辑 ---
json_string_match = re.search(r"```json\s*(\{.*\})\s*```", response_message.content, re.DOTALL)
if json_string_match:
extracted_json_content = json_string_match.group(1)
try:
final_response = json.loads(extracted_json_content)
print("Agent: 任务完成,成功解析最终JSON文案。")
return json.dumps(final_response, ensure_ascii=False, indent=2)
except json.JSONDecodeError as e:
print(f"Agent: 提取到JSON块但解析失败: {e}")
print(f"尝试解析的字符串:\n{extracted_json_content}")
messages.append(response_message) # 解析失败,继续对话
else:
# 如果没有匹配到 ```json 块,尝试直接解析整个 content
try:
final_response = json.loads(response_message.content)
print("Agent: 任务完成,直接解析最终JSON文案。")
return json.dumps(final_response, ensure_ascii=False, indent=2)
except json.JSONDecodeError:
print("Agent: 生成了非JSON格式内容或非Markdown JSON块,可能还在思考或出错。")
messages.append(response_message) # 非JSON格式,继续对话
# --- END: 添加 JSON 提取和解析逻辑 ---
else:
print("Agent: 未知响应,可能需要更多交互。")
break
except Exception as e:
print(f"调用 DeepSeek API 时发生错误: {e}")
break
print("\n⚠️ Agent 达到最大迭代次数或未能生成最终文案。请检查Prompt或增加迭代次数。")
return "未能成功生成文案。"
# 测试案例 1: 深海蓝藻保湿面膜
product_name_1 = "深海蓝藻保湿面膜"
tone_style_1 = "活泼甜美"
result_1 = generate_rednote(product_name_1, tone_style_1)
print("\n--- 生成的文案 1 ---")
print(result_1)
# 测试案例 2: 美白精华
product_name_2 = "美白精华"
tone_style_2 = "知性温柔"
result_2 = generate_rednote(product_name_2, tone_style_2)
print("\n--- 生成的文案 2 ---")
print(result_2)
















 640
640

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









